

| Double-Byte Character Set Support | Examples | |

The Micro Focus Extensions for Double-Byte Character Support is the additional facility provided by Micro Focus as the programming solution for environments using 16-bit coding schemes (DBCS). This facility incorporates every implementation of Japanese language support from earlier Micro Focus products.
If you wish your program to comply with the Multivendor Integration Architecture (MIA) Standard or to be compatible with IBM VS COBOL II, COBOL/370 or IBM SAA you should use the DBCS Support defined earlier in the chapter Double-Byte Character Set Support.
8-bit codes used by your COBOL system are referred to as the Single-Byte Character Set (SBCS). 16-bit codes, each character occupying a pair of adjacent bytes are referred as the Double-Byte Character Set (DBCS).
Micro Focus Extensions for Double-Byte Character Support is enabled by the NCHAR or JAPANESE Compiler directives.
When the Micro Focus Extensions for Double-Byte Character Support is enabled, the support defined in the chapter Double-Byte Character Set Support is modified. In particular, in this chapter MOVE operations from SBCS to DBCS data items perform SBCS to DBCS conversion.
The classes NCHAR and JAPANESE, and NCHAR-EDITED and JAPANESE-EDITED are synonyms and interchangeable. In this chapter, reference to the class or category NCHAR or the category NCHAR-EDITED is equivalent to the class or category JAPANESE or the category JAPANESE-EDITED respectively.
The NCHAR or JAPANESE directive makes your COBOL compiler recognize the NCHAR data category in which data is stored in DBCS. It does not prevent the use of other SBCS data categories; thus you can still use those data categories in which data is stored in SBCS.
Provided you have the necessary hardware support, NCHAR data items used in input and output are recognized and their data displayed and accepted correctly on such devices as screens, keyboard, printers.
DBCS characters can be used in literals, in comments and comment-entries, and in user-defined words. Otherwise the NCHAR or JAPANESE directives do not change the range of characters that can be used in source programs - the program is still written using the COBOL character set (see the chapter Concepts of the COBOL Language in your Language Reference).
There are extensions to the PICTURE and USAGE clauses to define items that are to contain NCHAR data.
There are additional rules for various options, clauses and statements to define the behavior of NCHAR data.
Except where otherwise stated, all the rules and features of COBOL remain applicable when the Micro Focus Extensions for Double-Byte Character Support are in use. The following sections give only the additional rules and formats pertaining to this support.
SBCS and DBCS characters can be mixed freely in comments and comment-entries.
Either SBCS or DBCS characters can be used and mixed freely in user-defined words for:
| alphabet-name, | cd-name, | class-name, |
| condition-name, | constant-name, | data- name/identifier, |
| file-name, | index-name, | level-number, |
| library-name, | mnemonic-name, | object-computer-name, |
| paragraph-name, | program-name, | record-name, |
| report-name, | screen-name, | section-name, |
| segment-number, | source-computer-name, | symbolic-character, |
| text-name. | ||
This entry should be considered as an additional syntax rule for each user-defined word specified above. Where a character exists in both the DBCS and SBCS character sets, its DBCS and SBCS representations are not regarded as equivalent.
On some operating systems, only ASCII characters might be permitted for:
| external-file-reference, | library-name, | program-name. |
Spaces in data of class NCHAR are represented by the DBCS code for space. A space character represented by a 2-byte code is referred to as a DBCS space.
The values assigned to a DBCS space are sensitive to the NCHAR, JAPANESE and DBSPACE Compiler directives.
In common with all data items that do not have a VALUE clause, data items of class NCHAR initially contain SBCS spaces.
There is a class of data additional to the classes described in the chapter Concepts of the COBOL Language in your Language Reference: NCHAR. It includes two data categories: NCHAR and NCHAR-EDITED.
A data item of class NCHAR can be described by using the USAGE NCHAR or USAGE JAPANESE clause. An item with this clause can have only the characters "N", "B", "/" or "0" in its PICTURE character-string.
An item whose PICTURE character-string is all "N"s is of category NCHAR, an item whose PICTURE character-string contains both "N" and "B", "/" or "0" is of category NCHAR-EDITED.
Note that each "N", "B", "/" or "0" represents one 2-byte character position. Except where otherwise stated, the length of the data item for all purposes is the number of "N"s, "B"s, "/"s and "0"s in its PICTURE character-string.
For reference modification, the leftmost-character-position and length specify the number of DBCS characters, not bytes.
Data items of class NCHAR can be used wherever data items of class alphanumeric can be used, subject to rules and exceptions given in the appropriate places in this chapter.
DBCS characters can be included in data stored in data items of category alphanumeric. In such data, SBCS characters are represented by SBCS codes and DBCS characters by DBCS codes. Each space character is represented by the SBCS code for space.
In operations within the program the data are treated as ordinary alphanumeric data. It is the programmer's responsibility to ensure that the two halves of a DBCS code do not get separated.
The length of the data item for all purposes is its length in bytes when stored in machine memory.
There is a third type of literal in addition to the nonnumeric and numeric literals described in the chapter Concepts of the COBOL Language in your Language Reference, the NCHAR literal.
An NCHAR literal is a character-string delimited at both ends by quotation marks or apostrophes, the character-string can consist of any allowable character in the computer's DBCS character set.
All DBCS literals can be used wherever nonnumeric literals can be used, subject to rules and exceptions given in the appropriate places in this chapter.
DBCS characters can be included in nonnumeric literals. A nonnumeric literal that includes SBCS and DBCS characters is called a mixed literal. In such a literal, SBCS characters are represented by SBCS codes and DBCS characters by DBCS codes. Each space character is represented by the SBCS code for space.
On output both the SBCS and the DBCS codes are recognized. In operations within the program the literal is treated as an ordinary nonnumeric literal. It is the programmer's responsibility to ensure that the two halves of a DBCS code do not get separated.
A mixed literal is of category alphanumeric, not NCHAR.
Whether quotation marks or apostrophes are used as character-string delimiters, the presence of that delimiter in a mixed literal can be represented by two contiguous occurrences. The presence of the character that is not serving as the delimiter is represented by a single occurrence. The value of a mixed literal in the object program is the string of characters itself, except each embedded pair of contiguous delimiter characters represents a single character.
If a figurative constant is used where only an NCHAR literal is allowed (according to the rules concerning classes and categories given in the appropriate places in this chapter), it is an NCHAR literal.
| Constant |
Representation |
Example NCHAR Japanese Values | |
|---|---|---|---|
| Shift-JIS |
EUC |
||
| ZERO
ZEROS ZEROES |
Represents one or more of the double-byte character "0" depending on the context. | x"824F" | x"A3B0" |
| SPACE
SPACES |
Represents one or more of the double-byte character space from the computer's set. | x"8140"1 | x"A1A1"1 |
| HIGH-VALUE
HIGH-VALUES |
Represents one or more character that has the highest ordinal position in the program collating sequence. | x"FFFF" | x"FFFF" |
| LOW-VALUE
LOW-VALUES |
Represents one or more character that has the lowest ordinal position in the program collating sequence. | x"0000" | x"0000" |
| QUOTE
QUOTES |
Represents one or more of the double-byte character " " ". | x"818D"2 | x"A1ED"2 |
| 1 | This value is sensitive to the DBSPACE Compiler directive | |
| 2 | This value is sensitive to the APOST Compiler directive |
The compiler is designed to allow only 8-bit characters to be used in the PROGRAM COLLATING SEQUENCE IS phrase.
It is meaningless to define a collating sequence using an ALPHABET clause in which the literals contain double-byte characters. This is because double-byte appears as two separate 8-bit characters. If you attempt to use double-byte in this way, double-byte characters are collated as two single bytes – any double-byte meaning is ignored.
You can, however, use non-ASCII characters in the ALPHABET clause literals when you define the program collating sequence. For example, in a Japanese environment single-byte Katakana can be used in a Shift-JIS environment as they are stored and displayed as one byte. If you are using EUC you cannot use single-byte characters in the ALPHABET IS phrase, because such characters are hybrid two-byte characters.
The functions of these symbols are as follows:
| Symbol
|
Representation
|
Example NCHAR Japanese Values | |
|---|---|---|---|
| Shift-JIS
|
EUC
|
||
| N | Each "N" represents a character position which can contain only a DBCS character or a DBCS space. | ||
| B | Each "B" represents a character position into which the DBCS space character is inserted. | x"8140"1 | x"A1A1"1 |
| / | Each "/" represents a character position into which the DBCS forward slash is inserted. | x"851E" | x"A1BF" |
| 0 | Each "0" represents a character position into which the DBCS Zero is inserted. | x"824F" | x"A3B0" |
| 1 | This value is sensitive to the DBSPACE Compiler directive. |
Note that each "N", "B", "/", "0" represents a single double-byte character position.
The type of editing that can be performed on an item depends on the category to which the item belongs. Table 4-1 Function Names Support (see the chapter Program Definition in your Language Reference) is extended with the following information:
Table 6-1: Editing Types for Data Categories
| Category |
Type of Editing |
|---|---|
| NCHAR | None |
| NCHAR-EDITED | Simple insertion "B", "/", "0" only |
When used in an SBCS item, "B" (space) represents an SBCS space. When used in an NCHAR item it represents a DBCS space.
When used in an SBCS item, "/" (forward slash) represents an SBCS forward slash. When used in an NCHAR item it represents a DBCS forward slash.
When used in an SBCS item, "0" (zero) represents an SBCS zero. When used in an NCHAR item it represents a DBCS zero.
The General Format is extended by the addition of the following:
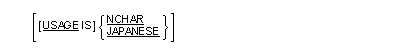
Whenever a PICTURE clause contains an "N" the associated item is considered to be of class NCHAR, Japanese.
An NCHAR literal in the VALUE clause must not exceed the size given by the PICTURE character-string.
If a condition-name with a literal of class NCHAR is associated with an elementary item which is not of class NCHAR, the literal is treated as an SBCS alphanumeric literal.
Data items and literals of class NCHAR can be used in a relation condition with any relational operator. No conversion, editing or de-editing is done and no distinction is made between items of category NCHAR and items of category NCHAR-EDITED.
The operation performed is a nonnumeric comparison. Since there is in general no collating sequence between the characters in a DBCS character set, the collating sequence used is based on the numeric values of the bit patterns representing the characters, interpreted as if they were binary numbers.
Note that if the DBCS character codes include codes for characters in the SBCS character set, there is no guarantee that this collating sequence orders them the same as in SBCS.
Where a character exists in both the DBCS and SBCS character sets, its DBCS and SBCS representations are not regarded as equivalent.
The PROGRAM COLLATING SEQUENCE clause has no effect on comparisons involving data items of class NCHAR or NCHAR literals.
If the operands are of unequal size, comparison proceeds as though the shorter operand were extended on the right by enough DBCS spaces to make them the same size.
An additional class test, JAPANESE, is available. This class test is true if all characters in the data item being tested are valid single-byte Katakana or double-byte characters, or if the data item contains all spaces.
In a Format 1 ACCEPT of an NCHAR-EDITED data item, there is no validation, conversion or character alignment of the data that you enter. As a result, the data might be corrupted. Therefore, we recommend that you do not use this method, or use it with caution.
In Formats 4 and 5, both single-byte and double-byte characters are valid characters to be entered into an NCHAR data item. However single-byte characters are converted to their double-byte equivalent.
All normal editing features are supported for the ACCEPT of NCHAR data items (backspace, retype, delete, restore, overtype and insert) on a character by character basis.
Note: In some environments, such as a Japanese EUC environment, special actions or behavior may occur.
The General Format is extended by the options NCHAR and JAPANESE as additional alternatives to options such as ALPHABETIC or ALPHANUMERIC.
All statements that involve moving data between items and/or literals of class NCHAR obey the rules given for such moves under the General Rules below.
| Category of Sending Item | Category of Receiving Data Item | |||
|---|---|---|---|---|
| Alpha-numeric | NCHAR | NCHAR-EDITED | NCHAR with JUSTIFIED | |
| Alpha-numeric | See Note | Yes/G1 | Yes/G4 | No/S2 |
| NCHAR | Yes/G2 | Yes/G3 | Yes/G4 | Yes/G5 |
| NCHAR-EDITED | No/S1 | No/S1 | No/S1 | No/S1 |
| NCHAR with JUSTIFIED | Yes/G2 | Yes/G3 | Yes/G4 | Yes/G5 |
Note: Class Alphanumeric is specified in this table as an illustration of the usage of single-byte or group data items. For details of MOVE operations involving only single-byte data items refer to the MOVE statement in the chapter Program Definition in your Language Reference. For details of MOVE operations mixing single- and double-byte data item, refer to the following information and the table above.
If a receiving data item is a different size from the sending data item, the data that is stored in the receiving item is truncated or padded on the right with DBCS spaces.
If a receiving data item is a different size from the sending data item, the data that is stored in the receiving item is truncated or padded on the right with SBCS spaces.
If a receiving data item is a different size from the sending data item, the data that is stored in the receiving item is truncated or padded on the right with DBCS spaces.
If a receiving data item is a different size from the sending data item, the data is stored in that receiving item and truncated or padded on the right with DBCS spaces.
If the sending data item is of class alphanumeric or alphabetic, the hexadecimal values of the single-byte characters in the source are converted to the equivalent double-byte characters in the target. DBCS characters in the source are moved unchanged into the target.
When a receiving data item is described with JUSTIFIED clause and the sending data item is larger than the receiving data item, the leftmost characters are truncated. When the receiving data item is described with the JUSTIFIED clause and it is larger than the sending data item, data is aligned at the rightmost character position in the data item with DBCS spaces padding from the leftmost character positions.
Copyright © 1999 MERANT International Limited. All rights reserved.
This document and the proprietary marks and names
used herein are protected by international law.
| Double-Byte Character Set Support | Examples | |