

| Managing Projects | Browsing Your Project | |
This chapter describes the analysis tools and how they can help you in your tasks.
Analysis tools provide powerful insights into how your source code systems function. They are accessed from the Tools menu and are named according to their functionality. The following tools are available for you to use during your analysis tasks:
The Integrated Editor, or Split Screen Editor as it appears in the encapsulated source view, is a full featured Windows editor. At the click of a mouse, you have full source code editing capabilities. When used in conjunction with the analysis tools and browsers, the editor becomes a highly effective way to maintain source code.
The Integrated Editor and the Split Screen Editor are the same tool except
for the ![]() New File option
that appears in the Integrated Editor. The New File option opens a new work
space for editing. The Split Screen Editor appears in an encapsulated view
within tools and browsers to allow the user to analyze items in the information
window simultaneously while viewing and editing the item's source code. The
Integrated Editor appears in standard window size to allow for extensive
editing. Because their features are so similar, the term Integrated Editor will
apply to both unless otherwise specified. The Integrated Editor is invoked with
the
speed menu or the Tools
menu. To access it from the speed menu, right-click on an item in the
information window, select Tools from the speed menu, and choose
Integrated Editor from the sub menu.
New File option
that appears in the Integrated Editor. The New File option opens a new work
space for editing. The Split Screen Editor appears in an encapsulated view
within tools and browsers to allow the user to analyze items in the information
window simultaneously while viewing and editing the item's source code. The
Integrated Editor appears in standard window size to allow for extensive
editing. Because their features are so similar, the term Integrated Editor will
apply to both unless otherwise specified. The Integrated Editor is invoked with
the
speed menu or the Tools
menu. To access it from the speed menu, right-click on an item in the
information window, select Tools from the speed menu, and choose
Integrated Editor from the sub menu.
The Split Screen Editor is invoked in any tool or browser by selecting an
item in the information window and clicking
![]() View Source Code.
View Source Code.
To edit source code in the Integrated Editor position the cursor to the insertion point of an edit and begin typing. The Backspace key and the Delete key will delete text respectively backward and forward from the cursor. The arrow keys can move you right, left, up, or down.
There are two methods of selecting source in the editor: the mouse or the keyboard. With the mouse, click and drag the cursor over the text to be selected. Use the keyboard to horizontally select text by holding down the Shift key and pressing the left and right arrow keys. The Shift key and the up and down arrow keys select text from the cursor to the line above or below the current position. The Shift key plus the Home or End keys selects text from the beginning (far-left) of a line to its end (far-right). Additionally, when an item is selected in the information window, its source code is selected in the split screen editing window.
To delete blocks of source in the editor, select the undesired text, hold
down the Ctrl key, and press the Delete key. To undo the last
edit, delete, or movement made in the Integrated Editor, hold down the Shift
key and press the Backspace key or click
![]() Undo selection.
Undo selection.
When you want to copy
The Integrated Editor enables you to move blocks of text in your source code to the Windows clipboard. The following list describes the features provided for moving text:
In addition to the source editing features described above, the Integrated Editor enables you to scan entire source files with the Search and Replace features. This is important to your source code editing because you can perform the following procedures:
The ![]() Search and
Replace dialog box enables you to specify a source code object and locate
it in the source code. The
Search and
Replace dialog box enables you to specify a source code object and locate
it in the source code. The ![]() Repeat Last Search feature enables you to advance to the next
occurrence of the object. When you click Ok the modification is applied
to the next object in relation to the cursor position.
Repeat Last Search feature enables you to advance to the next
occurrence of the object. When you click Ok the modification is applied
to the next object in relation to the cursor position.
When ![]() View Source Code
is clicked, the information window is split to make room for the encapsulated
Split Screen Editor. The source code that is selected in the editor window
corresponds to the item selected in the information window. When another item
is selected up top, the Split Screen Editor will display the correct source
code down below.
View Source Code
is clicked, the information window is split to make room for the encapsulated
Split Screen Editor. The source code that is selected in the editor window
corresponds to the item selected in the information window. When another item
is selected up top, the Split Screen Editor will display the correct source
code down below.
Within the editing windows you have the ability to move freely through the source code, viewing and making modifications. There are several features specific to mobility through source code files in the Integrated Editor.
The Integrated Editor enables you to save and load source files. The
![]() Save all Modifications
feature saves all your changes to the database. The
Save all Modifications
feature saves all your changes to the database. The
![]() Save to File feature
saves modifications to the current source file. The
Save to File feature
saves modifications to the current source file. The
![]() Save as File feature
opens the Save As dialog, so you can specify a new name and location for
the source file. The Load from File button
Save as File feature
opens the Save As dialog, so you can specify a new name and location for
the source file. The Load from File button
![]() opens the Open dialog to
load files into the editor.
opens the Open dialog to
load files into the editor.
The ![]() Status Bar
displays file names of accessed items in a drop down list box format. You can
view the current file's name and access previous files by selecting preferred
file names from the drop down list. The current cursor location and file status
are also displayed.
Status Bar
displays file names of accessed items in a drop down list box format. You can
view the current file's name and access previous files by selecting preferred
file names from the drop down list. The current cursor location and file status
are also displayed.
Three views can be invoked inside the Integrated Editor: the Code Flow view
![]() , the Screen view
, the Screen view
![]() , and the Inventory view
, and the Inventory view
![]() . Each of these views are
available for applicable source components. When a source file component has an
accompanying view, its button is enabled on the tool bar. Refer to the section
on Views for more details.
. Each of these views are
available for applicable source components. When a source file component has an
accompanying view, its button is enabled on the tool bar. Refer to the section
on Views for more details.
The ![]() Execution
Simulator is available from the Integrated Editor. The Execution Simulator
enables you to do perform several tasks. You can:
Execution
Simulator is available from the Integrated Editor. The Execution Simulator
enables you to do perform several tasks. You can:
A simulation is started at any statement in a COBOL program. Select the
statement and click ![]() Run.
The following features are available for you to apply to the walk through.
Run.
The following features are available for you to apply to the walk through.
| Click This: |
To Do This: |
|---|---|
|
Capture Results...: |
Invokes the Capture Results dialog. |
|
Step True/Into: |
Advances the simulation to the next statement, processes the true branch of a conditional statement, or processes statements inside of a PERFORM or CALL statement depending on the context. |
|
Step False/Over/Error: |
Processes the false branch of a conditional statement or skips the simulation of the statements inside of a branch statement depending on their context. |
|
Run: |
Initiates and halts the automatic simulation process. You are prompted when a conditional statement is encountered to verify the procedure. |
|
Backtrack: |
Undoes the previous step. |
|
Reset: |
Resets the simulation to the starting statement and clears the path and effected variables. |
|
Direction: |
Sets the direction of the simulation forwards or backwards. |
|
Options: |
Displays the Execution Simulator Options. The stepping speed is set in this dialog. You control the display of the Execution Path here also. |
Clear Highlights |
Removes highlighting from source code. |
The Metrics tool calculates four statistical measures of complexity:
To change from one mode to another, use
![]() Metrics
Options. After you select a new mode, the analysis is automatically
performed when you click Ok. The Metrics tool is set to Halstead by
default. To change the default mode go to the Utilities menu and choose
Tools > Views. Click the Metrics tab to change the settings
that are used when the Metrics tool starts its analysis.
Metrics
Options. After you select a new mode, the analysis is automatically
performed when you click Ok. The Metrics tool is set to Halstead by
default. To change the default mode go to the Utilities menu and choose
Tools > Views. Click the Metrics tab to change the settings
that are used when the Metrics tool starts its analysis.
The Halstead metric mode uses four numbers to calculate the estimated length of each program. These numbers are the total number of operator occurrences (N1), the total number of operand occurrences (N2), the number of distinct operators (n1), and the number of distinct operands (n2). With these numbers, Halstead estimates the program length to be:
N=N1 + N2
The volume to be:
V=N log2 (n1 + n2)
The McCabe metric mode calculates the cyclomatic, extended, and essential complexity of each paragraph and program. These numbers represent the number of logical paths through the source code.
The McClure metric mode calculates complexity for each paragraph and program as the number of conditionals plus the number of unique operands used in the conditionals.
Statistics metrics mode displays the number of lines and statements in each paragraph and program.
The implementation of Function Point Analysis is based on the International Function Point Users Group's (IFPUG's) 3.4 function point analysis definition.
Note: It is recommended that the Complete Project feature be used to provide any missing information prior to opening the Function Point Analysis tool.
Use the Function Point Analysis tool to measure the complexity of your project. Function Point Analysis first identifies and organizes the system's business functions into five groups:
Note: FPA classifies screen accesses as either inputs or outputs. Data files are classified as ILF (Internal Logical File) or EIF (External Interface File). The distinction is made in that ILF's are written to and EIF's are not.
Then each business function is classified and weighed by its level of complexity (low, average, or high). Finally, the numbers are totalled to establish the complexity of your project. The higher the total is the more complex the project is. The evaluation process can be viewed in the Function Point Analysis window.
The ![]() FPA
Options enable you to define weighting factors that adjust the parameters
of the Function Point Analysis. A numerical value is determined based on the
designated weight of each function where 0 represents no influence and 5
represents strong influence. The defaults for this dialog are changed with the
Complexity Factors option on the Utilities > Tools/Views >
Function Point Analysis tab.
FPA
Options enable you to define weighting factors that adjust the parameters
of the Function Point Analysis. A numerical value is determined based on the
designated weight of each function where 0 represents no influence and 5
represents strong influence. The defaults for this dialog are changed with the
Complexity Factors option on the Utilities > Tools/Views >
Function Point Analysis tab.
The ![]() Classifications feature opens the File Types dialog box which allows for
file types to be specifically identified. By selecting an item and clicking the
specific button, elements can be designated as inquiries, inputs, outputs, ILF,
or EIF. If an element is unused it can be tagged unused.
Classifications feature opens the File Types dialog box which allows for
file types to be specifically identified. By selecting an item and clicking the
specific button, elements can be designated as inquiries, inputs, outputs, ILF,
or EIF. If an element is unused it can be tagged unused.
The Annotation tool allows persistent documents or notes to be created that contain references to elements of source code as well as user-defined information about those elements. Annotations are useful:
Using annotations is an excellent way to document source code changes as well as performing project management tasks. Use the Annotation tool to manage, research, create, or delete annotations. Each annotation includes a title, description, status, and list of related elements. These documents or notes will exist within a Revolve project until they are explicitly deleted. The Annotation tool is accessed from the Tools menu or from the speed menu.
The Annotation tool locates annotations based on certain parameters defined in the Edit Annotation dialog. Use the pull down list box to select the Edit Annotation field that is to be used to find a specific annotation. Enter the name or naming convention in the Match edit field and click Match. Annotations that match the criteria are displayed in the information window.
When
you add elements to an annotation, you may or may not add them in the order
they occur in the source. To organize your annotations, use the
![]() Sort
function. It orders connected elements in two ways.
Sort
function. It orders connected elements in two ways.
Sorting elements according to the order they were added preserves any
existing process used to create the annotation. Sorting by location in the
source file enables you to order connected elements by their occurrence in the
source code. Especially useful when you want to organize elements that were
randomly added to the annotation. After clicking Sort, click
![]() Refresh, and
then expand the connected elements folder to view the changes.
Refresh, and
then expand the connected elements folder to view the changes.
The Edit Annotation dialog is invoked with
![]() Edit Annotation.
Edit Annotation.
The following information is available for each annotation:
| Field: |
Definition: |
|---|---|
| Title: |
Names the annotation. |
| Date: |
Indicates date the annotation was created. This field can not be changed. |
| By: |
Displays name assigned to the person who created the annotation. The default user name is taken from the value specified in the User Name field of the Utilities > Options... User tab. |
| Status: |
Monitors the status of annotations that are used for source code changes. |
| To: |
Identifies the intended recipient. |
| Description: |
Describes the annotation. Descriptions should be limited to 8,000 bytes (8K). |
| Associated Elements: |
Lists the other elements that are associated with this annotation. This is a concise way of associating related elements to a single annotation. Elements for this list can be selected by using tools, views, and information browsers. To add all currently highlighted elements, press the Add Highlighted button. To delete an element, select the element in the Associated Elements list and press the Remove button. |
| Element Description: |
Describes selected elements. Each element in the Associated Elements list can have an optional description associated with it. As the current selection in the Associated Element list is changed, the Element Description is updated with the corresponding description. |
To save changes to the annotation, click Ok. To cancel changes, click Cancel.
Information can be added to annotations from the Annotation tool or with Capture Results. If an annotation is currently being edited in an Edit Annotation window, the elements are added to that annotation, otherwise the Add element to annotation window is displayed. This enables you to create a new annotation or lookup an existing one.
Annotations in shareable projects have two classifications:
When you create an annotation in a shareable project it is Public by default. To move it to Private:
To make it Public again click
![]() Move to Public. If these
buttons are not displayed in the Annotation tool, then close and restart
Revolve. A single annotation cannot be both public and private simultaneously.
Move to Public. If these
buttons are not displayed in the Annotation tool, then close and restart
Revolve. A single annotation cannot be both public and private simultaneously.
Public annotations are stored by default in the same directory where the project file is stored (.prj). The location is changed on the Project tab, accessed with Utilities > Options.... Note that this directory must be accessible to all users of a project. Private annotations are stored according to the setting of the Private Annotation Directories setting on the Directories tab. We recommend that the Private and Public annotation directories be different.
The Scripts tool enables you to automate specific tasks in Revolve. Scripts are organized according to their general purpose in project analysis and operation. They are categorized as follows:
Expand each folder to view the scripts it contains. To run a script, select
it and click ![]() Run. Often specific project components must be selected for a script to
execute its designed function. The Choose Components dialog box enables
you to assign a scope to the script, applying the scripting procedure to
selected project items.
Run. Often specific project components must be selected for a script to
execute its designed function. The Choose Components dialog box enables
you to assign a scope to the script, applying the scripting procedure to
selected project items.
Shows records used in I-O against batch files and the copybooks containing the record layouts. Records moved to or from I-O records are included in the record list.
Shows records used in I-O for CICS datasets and copybooks containing the record layouts. Records to which I-O records are moved are included in the record list for a dataset.
Shows files accessed by their procedure.
Shows files accessed by programs. Records displayed for program/file are records READ INTO or WRITTEN - REWRITTEN FROM, as well as the data record defined in the File Definition (FD).
Shows procedures accessing files by file.
Shows programs accessing files by file.
Finds variables whose names are the same but whose PIC clauses define different types or sizes.
Reports on parser-generated errors in user-specified project components.
Reports on parser-generated errors and warnings in user-specified project components.
Returns all discrepancies discovered during project parsing.
Reports on parser-generated file-not-found warnings in user-specified project components. File-not-found warnings are most likely copybooks or proclibs that have not been added to the project before parsing.
Reports on the notices that occur during the loading process. Notices are the least severe of the parser-generated problems.
Reports on parser-generated syntax warnings in user-specified project components.
Reports on parser-generated Warnings in user-specified project components.
Shows all modules by type that have been added to the Project Manager where duplicate names exist in multiple directories. This script is designed to show invalid conditions that exist in the source code, so that problems can be resolved.
The Project Management scripts are provided as templates that you can
customize to automate some of your common administrative tasks. Select a script
and click ![]() View
Source Code to view its source. These templates are working scripts that
you can actually execute if your directory structure adheres to that used in
the script and if the sample source code that was included in the installation
is located in c:\revolve\sample.
View
Source Code to view its source. These templates are working scripts that
you can actually execute if your directory structure adheres to that used in
the script and if the sample source code that was included in the installation
is located in c:\revolve\sample.
Customize these scripts according to your project needs. You can review the
source and replace existing parameters with some of your project's parameters.
For example, in the Template for creating a new project by explicitly adding
sources, substitute the existing paths with your system paths and file
names. Once you are satisfied with the settings, save the script. Then click
![]() Compile. Once
the script has compiled it's ready to be
Compile. Once
the script has compiled it's ready to be
![]() Run. For
information on language constructs and functions specific to project
administration, see Automating Project
Management
Run. For
information on language constructs and functions specific to project
administration, see Automating Project
Management
Customize this script to create a new project and add components. Substitute existing settings with your system parameters.
Customize this script to set up search directories for your project, where
Revolve loads components of specified types from specified directories. These
search directories are referenced for subsequent
![]() Makes and
updates. Substitute existing settings with your system and project parameters.
Makes and
updates. Substitute existing settings with your system and project parameters.
Customize this script to automate project
![]() Makes.
Substitute existing settings with your project's parameters.
Makes.
Substitute existing settings with your project's parameters.
Opens a Choose dialog that displays all the copybooks referenced in the project. Select a copybook or copybooks (Ctrl key and left mouse button) and click Ok. The script describes all variables referenced in the copybook(s) and their attributes.
If nothing is returned for a selected copybook, check to see if the copybook is loaded properly. An easy way to find problem files is with the Parsing Problems scripts.
Reports on I-O Records. Records are 01 level input/output records.
Reports on non-I-O records. Records cannot be input or output (exclude all records defined in Comm Area, FD, and Linkage sections) and must be 01 group level data elements.
Groups IO records by size/name.
Groups secondary (non-I-O) records by size/name.
Reports on usage of hard-coded literals by program.
Identifies program source that violates the following indentation rule:
Reports on MOVE statements that result in truncation. Truncation is a result of data elements being moved from a field of a certain size to one of smaller size.
Returns MFS screen files that have duplicate FMT names.
Returns a list of copybooks in the project with duplicate names.
Determines greatest number levels of nested IF statements within the selected programs. Reports on and highlights all IF statements exceeding user specified maximum.
Reports on variable redefines, for which the redefining and redefined variables are of different lengths.
Generates a report of all COBOL programs whose program IDs differ from their member names. The discrepancy between program IDs and their member names may cause problems in other scripts, resulting in programs being out of order and duplicated in output reports. This script exposes such occurrences.
Generates a report of all PL/I programs whose program IDs differ from their member names. The discrepancy between program IDs and their member names may cause problems in other scripts, resulting in programs being out of order and duplicated in output reports. This script exposes such occurrences.
Reports on Variable Names whose length exceed a user defined maximum within the selected programs.
Reports on copybooks included in programs whose variable definitions are not referenced or whose procedural logic is not executed.
Reports on paragraphs whose statements are not executed.
Reports on the unused procedural logic within the program selected in the Choose dialog.
Provides information about variables that are not explicitly used in the loaded project. Please note that some returned fields may not be removed from the project because they are part of redefines, structure definitions, or copybook members that cannot be modified.
Invokes a Choose Components dialog where you need to specify the source file that needs to be copied to another location. Click Ok. In the Prompt dialog enter the path to the drive or directory where the files should be copied.
Counts logical and physical line numbers for all project members. It will generate four columns:
| Column |
Indicates |
| Module Name: |
Specifies the project module's name. |
| Logical: |
Refers to the total number of lines in a member, including imported elements (copybooks, procs, etc.). |
| Physical: |
Refers to the actual line count in the member. Imported elements (copybooks, procs, etc.) are not included. |
| Imports: |
Lists the numbers of lines brought into the member through imported elements (copybooks, procs, etc.). |
Allows you to utilize the import translations of one project in another one that requires the same translations. The default name and location of the script that is generated is C:\buildimp.rqs. When you use the script Rebuild Import Translations it will ask you for the compiled version of this file (.rqc).
Creates a script that is used to rebuild the active project (including Complete Project and Copybook Translation information).
Opens Screen views associated with the selected item. To select a project component, right-click on it in a Revolve information window and choose Select from the speed menu. The selected component's name is displayed at the bottom of the Revolve desktop.
If the selected item is a paragraph, printing the "text content" of a paragraph will print the whole paragraph.
Prompts you for the script that is created with Generate a script to rebuild the import translations. Enter the name of the compiled script (.rqc) and click Ok. The new translations will be displayed in Import Translations.
IF your IMS GEN has load modules and PDBs that are not referenced then this script will remove them.
IF your CSD report has load modules that are not referenced, then this script will remove them.
Impacts occur when data elements refer or relate to one another in a project through moves, redefines, conditionals, arithmetic operations, group relations, parameter passing, copybooks, references to files, and references to screens. When one item is changed in an application, it can effect other items, causing inconsistencies and even system failure.
The threat of data impacts poses a major problem when you consider the task of system maintenance and specifically making source code modifications. For example, if you modify just one data item, it might impact many different source components in many different areas of your system. To guarantee source code integrity, the Impact Analysis features enable you identify all locations in your system where specific data elements have impacts. Once you've located the impacts, you can modify source code accordingly to alleviate impact problems that may arise when you apply modifications to your actual system. The benefits of using Impact Analysis are:
The first step in impact analysis is to identify the data elements that are to be considered impact candidates. These impact candidates are used as starting points. After a list of starting points is defined, you should use the Impact Options dialog box to set the parameters for the impact trace. Impact tracing is the process where impacts are identified in your project. When you have a list of starting points and your impact options are set, you are ready to trace impacts. Impact Analysis traces each starting point according to your impact options and returns all the impact information that it finds in the project. Use the results of the impact trace to tailor your modifications for safe and effective implementation of modifications.
Note: It is recommended that the Complete Project dialog be used to provide Revolve with any missing information before the Impact Analysis tool is opened.
The first step in impact analysis is to define a list of data elements that may be impacted or cause impacts. This list of impact candidates is used as the starting point for the impact trace. A starting point can be any data element that is scheduled to be or has been modified or edited. Also, a starting point must be located in a loaded, up-to-date project file.
The Impact Analysis tool locates and loads starting points according to the
naming criteria you specify in the Match edit field, displayed on the
![]() Status Bar.
Specify an element's exact name or use wildcards to define naming patterns for
many elements that use similar naming conventions.
Status Bar.
Specify an element's exact name or use wildcards to define naming patterns for
many elements that use similar naming conventions.
Starting points must be classified as variables, BMS or MFS fields, literals, data files, or SQL columns. The status bar contains a pull down list box that enables you to specify the type of file. For example, to load all project variables whose names begin with WS, select Variable from the pull-down list box, enter WS* into the Match edit field, and click Match. The Impact Analysis information window fills with all project variables with names like WS-ABEND-MSG or WS-KEY.
When you click the Match button, Impact Analysis searches the project database and identifies all source components that comply with your name and type criteria. Matched components are displayed in the information window. These are your starting points for impact tracing. The total number of starting points is displayed on the status bar.
Note: Impact Analysis for the Assembler Extension uses variables as starting points and traces through direct variable manipulations in MOVE statements.
When you have a list of starting points that are considered impact candidates, you can edit, remove, or exclude items based on your analysis needs.
In a large, complicated project, it is essential that you be able to control
the direction and flow of the impact trace. Otherwise, you would be sifting
through unneeded and unimportant impact trace information. The Tracing
tab on the ![]() Impact Analysis
Options dialog enables you to define the parameters for tracing impacts from
your starting points through the project. There are two categories of options:
Impact Through and Prune.
Impact Analysis
Options dialog enables you to define the parameters for tracing impacts from
your starting points through the project. There are two categories of options:
Impact Through and Prune.

Impact Through settings enable you to configure the impact trace to return specific information on impacts occurring in certain project modules. You direct the path of impact tracing through source code components, like conditions, literals, arithmetics, redefines, copybooks, data files, executables, screens, and moves. With this control you can trace impacts through points of interest as well as known problem areas in your source code.
The Pruning options enable you to cut unnecessary data out of the impact trace results. For example, some source code constructs may seem to be impacts when really they aren't, or they do not actually cause significant impacts because of several kinds of buffers, suspect literals or executables. With the Pruning options, unimportant and irrelevant information can be removed from the impact trace results.
An instance of an insignificant impact that can be pruned is when a starting point being traced has a group level that is moved to another variable that does not have an overlapping element. Then only a portion of the third variable is impacted. That third variable is considered a buffer. Buffers often cause insignificant impacts and can removed with the Prune options.
Pruning options are described as follows:
After you are satisfied with your impact candidates and tracing options
you're ready to perform the impact trace. Impact tracing begins at each
starting point in the source code and traces from that point through each
element encountered. Along the way impacts with other project elements are
determined, identified, and returned in the results. To initiate impact
tracing, click ![]() Impact
Tracing. By default, the Impact Analysis tool displays all results by name.
You can change the display of impact information by clicking
Impact
Tracing. By default, the Impact Analysis tool displays all results by name.
You can change the display of impact information by clicking
![]() Options... and clicking
the Display tab. See Display Options.
Options... and clicking
the Display tab. See Display Options.
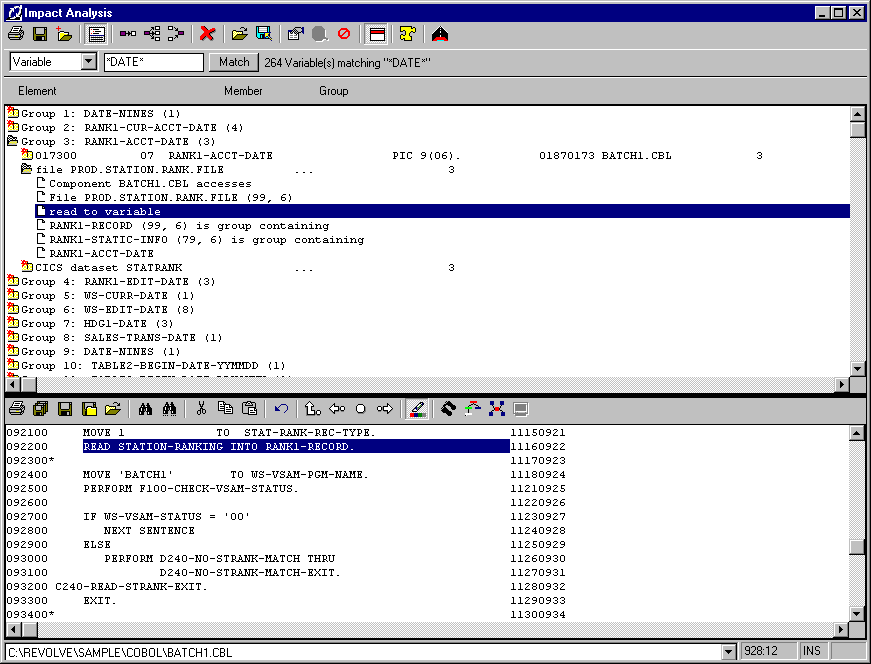
Figure 5-1: The Impact Trace
Once you have performed an impact trace, expand the displayed folders to
view the chain of events that led to each impact. The trace chain of events are
displayed as leafs ![]() . Each leaf
details a step in the data movement leading up to the impact of an item with
the impact candidate.
. Each leaf
details a step in the data movement leading up to the impact of an item with
the impact candidate.
During impact tracing the Impact Analysis tool analyzes data for all project entities that are effected when the variable, BMS field, or MFS field is modified. Impacts are categorized into the following types:
The Impact Analysis tool gives you various modes in which to view the
results of an impact trace. Click
![]() Options... and click the
Display tab.
Options... and click the
Display tab.

Figure 5-2: The Display Modes
| Click This: |
To Do This: |
|---|---|
| By Name: | Organize all impact items by name. |
| By Source Member: | List all impacts by their location in the project database. |
| By Program | Assemble the analysis results by the program through which the impact is logically defined. This option differs from the By Source Member option in that copybook-defined variables will appear in the folder for each program that includes the copybook. |
| By Type: | Arrange the results according to the type of the impact. Types are grouped by: Synonyms, Buffers, Files, Copybooks, Screen Fields, Literals, Screens, Global Variables, Executables. |
| By Impact Group: | Display impacts by grouping them according to the candidate. The top line in the folder represents the impact candidate. Each subsequent folder represents items that are effected if the candidate is modified. The number in parentheses beside the group number represents the number of impacts. If that number is one, there is only one occurrence and no additional impacts for the candidate. |
| Display all instances of matched patterns | Check this to display all instances of copybook variables that comply with match criteria. |
The Impact Analysis tool enables you to save the results of an impact trace.
The impact analysis is saved to a location that you define in the Save
dialog box that is invoked when you click
![]() Save Impact
Analysis. The file is given an .IA extension. To open the impact analysis
file later, click
Save Impact
Analysis. The file is given an .IA extension. To open the impact analysis
file later, click ![]() Load Impact Analysis.
Load Impact Analysis.
The Syntax Checker works in conjunction with the COBOL Workbench to check syntax in programs. It is required that you have version 4.0 of Micro Focus COBOL Workbench installed.
Revolve expects the environment to be correctly configured to execute COBOL.EXE. If the appropriate environment variables are not configured, then you should start Revolve with the command line:
MFENV 32 <revolve directory>\revolve\bin\revolve.exe
Revolve uses the information in the database to set directives and environment variables for the checker. Those are augmented by the rvchk.dir file located in the \revolve\bin subdirectory. Additionally, if user specific directives are necessary, Revolve will look for C:\rvuser.dir. Any warnings or errors are displayed under the program folder.
The ![]() Load Selected
feature initiates a compile of the selected items in the Syntax Checker.
Load Selected
feature initiates a compile of the selected items in the Syntax Checker.
Options for the Syntax Checker can be modified in the Options dialog,
invoked with ![]() Options....
If the environmental variable WBADVCFG is non-existent, undefined, or set to
"no" then the following dialog will be invoked.
Options....
If the environmental variable WBADVCFG is non-existent, undefined, or set to
"no" then the following dialog will be invoked.
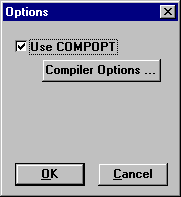
Figure 5-3: Syntax Options Setup
The Use COMPOPT check box enables access to the Workbench Compopt tool.
If the environmental variable WBADVCFG is defined and set to "yes"
then the following dialog will be invoked when you click
![]() Options....
Options....
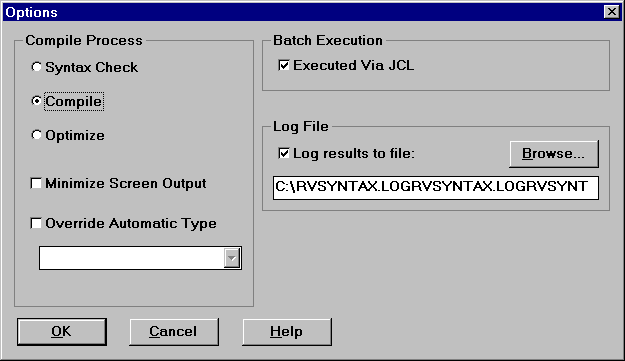
Figure 5-4: The Syntax Checker Options
Syntax Checker Options are described as follows:
| Select This: |
To Do This: |
|---|---|
| Syntax Check: |
Valid for COBOL and PSB. Syntax errors and warnings that were found during the compile are listed under the component in which they occurred. An .MSG file is generated for COBOL and an .ILS file is generated for PSB. |
| Compile: |
Valid for COBOL, Assembler, DBD, PSB, MFS, and BMS. Syntax errors and warnings that were found during the compile are listed under the component in which they occurred. An .MSG file is generated for COBOL, Assembler, and BMS, and an .ILS file is generated for DBD, MFS, and PSB. |
| Optimize: |
Valid for COBOL and Assembler. No output file is generated. |
| Minimize Screen Output: |
Specifies that the above operations be performed without the graphical output. This option greatly improves performance. |
| Override Automatic Type: |
Turns off/on Revolve's Automatic Typing functionality. Note that components sent to the Workbench as a wrong file type may return unpredictable results. If you select this option you must choose a file type from the pull-down list box. All components processed by the Workbench will be considered as files of the specified type. |
| Batch Execution: |
Specifies which directive will specify the COBOL file handler during execution: JCL, the default CALLFH(EXTFH),or CALLFH(PROXFH). |
| Log Results to File: |
Check box designates a log file of the checking procedure to be created in the specified directory. The Browse button opens a Get Log File Dir dialog, in which you can navigate to the desired location of the log file. |
Views create various graphical representations of the applications that comprise your system. These illustrations are overviews of how your system components are related to one another and the
The System view provides a graphical depiction of the relationships between entities (JCL jobs, COBOL programs, data files, etc.) in a project. In addition to the graphical icons, detailed information about each relationship is also provided.
Revolve uses the default options found under the Utilities >
Tools/Views option when opening a System view. Once a System view has been
opened the options can only be modified through the System View Options
dialog, invoked with the Options button
![]() on the tool bar.
on the tool bar.
For a description of the icons used in the System view choose the
![]() Print button
from the System view tool bar. Then check the Legend check box. Your
hard copy will be preceded by descriptions of the icons used in the view.
Print button
from the System view tool bar. Then check the Legend check box. Your
hard copy will be preceded by descriptions of the icons used in the view.
By default icons are shaded gray but clear icons may also appear. Clear or unshaded icons indicate that an element has duplicate icons in the graph. There will be only one shaded icon for each element in the source code. It is this icon which will be expanded to other elements. Icons which appear segmented symbolize a program entry point.

Figure 5-5: The System View
The buttons on the tool bar provide the following functionality:
Note: It is recommended that the Complete Project dialog be used to provide Revolve with any missing information before the System view is opened.
The Inventory view creates a complete graphical view of a program or JOB, including all of their related entities.
Note: It is recommended that the Complete Project dialog box be used to provide Revolve with any missing information before the Inventory view is opened.
When the Inventory view is invoked from the Tools menu, an Open Inventory dialog appears. To find a specific program, enter the program name into the Match edit box and click Match. Or use the list to find and select multiple programs for display in the view. The Select All button selects all of the items in the list and opens Inventory views for each program.
The Inventory for COBOL programs shows the main program, copybooks/includes, files, databases, screens, programs called, and entities invoking the main program.

Figure 5-6: Inventory View for Cobol File
The JCL/ECL inventory represents the job/run, steps, devices/files, executables, and DD statements.
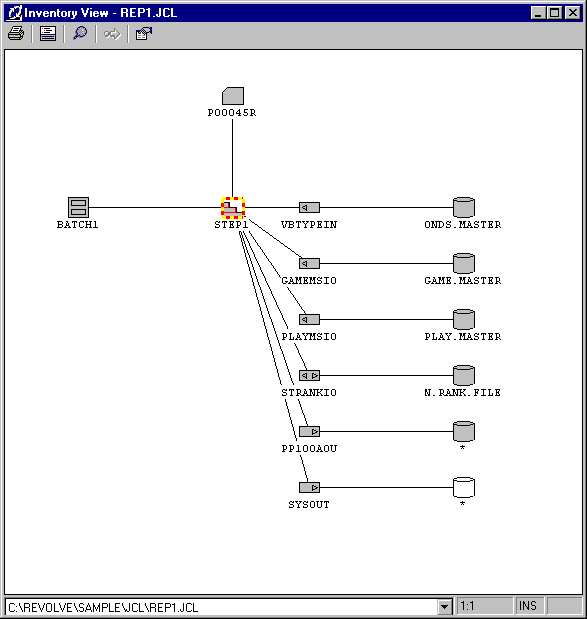
Figure 5-7: Inventory View for JCL
Depending on the DISP parameter of a DD statement, Revolve will place an arrow inside the DD icon indicating the usage of the data set.
Floating text enables you to see the full name of the elements the mouse passes over. You can disable the pop up text on the Utilities >Options... >User tab.
The Code Flow view displays a flow chart that illustrates the calling hierarchy of the paragraphs and sections in a COBOL program or entry point. The flow chart shows GO TO statements, PERFORM statements, CICS error handlers and fall throughs in relation to the paragraphs and sections in the program.
When the Code Flow view is invoked from the Tools menu, an Open Code Flow dialog appears. To find a specific program, enter the program name into the Match edit box and click Match . Or use the list to find and select multiple programs for display in the Code Flow view. The Select All button selects all of the items in the scroll-able list and opens Code Flow views for each program.
Please note that one Code Flow view is opened for each program that you select in the Open Code Flow dialog box. If you click Select All and there are a large number of programs in your project, then it may take considerable time for Revolve to create all of the appropriate Code Flow illustrations. If your project consists of many programs, we recommend that you specify the pertinent ones rather than clicking Select All.

Figure 5-8: Code Flow View for Cobol File
Revolve uses the default options on the Utilities > Tools/Views
options page, when opening a Code Flow view. Once a Code Flow view has been
opened, the options can be changed from the Code Flow Options dialog, invoked
by clicking ![]() Options . The
Options . The
![]() Overview Panel displays
the entire file's code flow. If there are multiple occurrences of the selected
component in the program, then
Overview Panel displays
the entire file's code flow. If there are multiple occurrences of the selected
component in the program, then ![]() Next Usage is enabled. When clicked, it displays the next usage of the
selected element.
Next Usage is enabled. When clicked, it displays the next usage of the
selected element.
Some COBOL programs allow execution to fall through the end of a paragraph into a new block of code. This will often result in flow charts that while accurate do not reflect the implied structure of the program. When the analysis is done to create the flow chart, the user can limit the number of times the system can fall through paragraphs that are also used to end a block of code. These paragraphs are referred to as "live" fall throughs because they are designated as exit paragraphs but under certain conditions they may fall through instead of returning. By limiting the number of "live" fall throughs with the Number of Live Fall Throughs option, the user can create a logical representation of the COBOL program.
Code Flow Options enable you to allocate the number of characters displayed in each label. This enables you to customize the display. The number of characters cannot be set to less than than five. Floating text enables you to see the full name of the elements the mouse passes over. You can disable the pop up text on the Utilities >Options... >User tab.
The Display Error/Exception Branches check box enables you to show or hide branches or exceptions that occur in a program (i.e. CICS handlers or ON ERROR clauses).
The Code Flow Options dialog enables you to set the number of live fall throughs in a system, to allocate the number of characters displayed in each label, and to specify the display of error/exception branches that occur.
Revolve expects there to be at least one section per COBOL program and one paragraph per section. If these are not explicitly labeled, then they are implied in the database. Programs that do not start with a section label or sections that do not start with a paragraph label appear in the flow charts with names that begin with a "#". For implied paragraphs, the names are derived by taking the name of the section containing the implied paragraph and prefixing it with a "#" character. For implied sections, the name is formed by prefixing the name of the program with a "#" character.
The Code Flow view is a graphical way to view the components of a COBOL program. Interpretation can be difficult unless you understand the significance of the symbols used to create the code flow view.
The Source view creates a logical view showing all the integrated files that comprise a module. For a COBOL program, the copybooks and include files are interleaved in the main source file. For JCL, a logical view that integrates all the proclibs with the main job is shown. The Source view displays the source code as it would appear in its source file format. The overview window runs along the right side of the view and provides a representation of the source file. The selected item's location appears as a horizontal bar in the overview window. Highlighted items will also be displayed in their appropriate color in the overview window.
When the Source view is invoked from the Tools menu, an Open Source dialog appears. To find a specific source file, enter the file name into the Match edit box and click Match. Or use the list to find and select multiple files for display in the view. The Select All button selects all of the items in the scroll-able list and opens Source views for each file.
The Data Structure view illustrates the data hierarchy by displaying all the variables in a program, section, or group level.
When the Data Structure view is invoked from the Tools menu, an Open Data Structure dialog appears. To find a specific file, enter the file name into the Match edit box and click Match. Or use the list to find and select multiple files for display in the view. The Select All button selects all of the items in the scroll-able list and opens Data Structure views for each file.
The Screen view creates an image of the BMS or MFS screen as it would be displayed in a production system. Uninitialized fields are shown with "X"s, or "9"s if numeric.
When the Screen view is invoked from the Tools menu, an Open Screen dialog appears. To find a specific BMS or MFS file, enter the file name into the Match edit box and click Match. Or use the list to find and select multiple files for display in the view. The Select All button selects all of the items in the scroll-able list and opens Screen views for each file.
Floating text displays the names of the fields the mouse passes over. You can disable the pop up text on the Utilities > Options... > User tab.
Copyright © 1999 MERANT International Limited. All rights reserved.
This document and the proprietary marks and names
used herein are protected by international law.
| Managing Projects | Browsing Your Project | |