Clustering is an unsupervised data mining technique where similar objects, taken from a large set, are grouped together to form clusters. An object in this case can be anything, as long as:
there is a method for comparing two objects
the comparison produces a useful measure of similarity
Typical examples of objects include documents, points on a graph, questionnaire data, and genetic data.
With clustering, a large set of objects produces a number of clusters, which collectively contain a subset of the objects, possibly leaving outliers behind (that is, objects that are not similar to any others).
Clustering allows you to quickly identify themes or trends in a large set of objects, or get a summary of what the objects are about. It is especially relevant if the set of objects changes regularly, because it is otherwise difficult to find out what it happening in the object set.
Various clustering algorithms are available. The correct one to use depends on the context in which you are using it. Some algorithms aim to place every object in the set into a cluster. Others recognize that some sets contain objects that are largely different from others, and ignore them. Some algorithms also allow objects to be placed in more than one set.
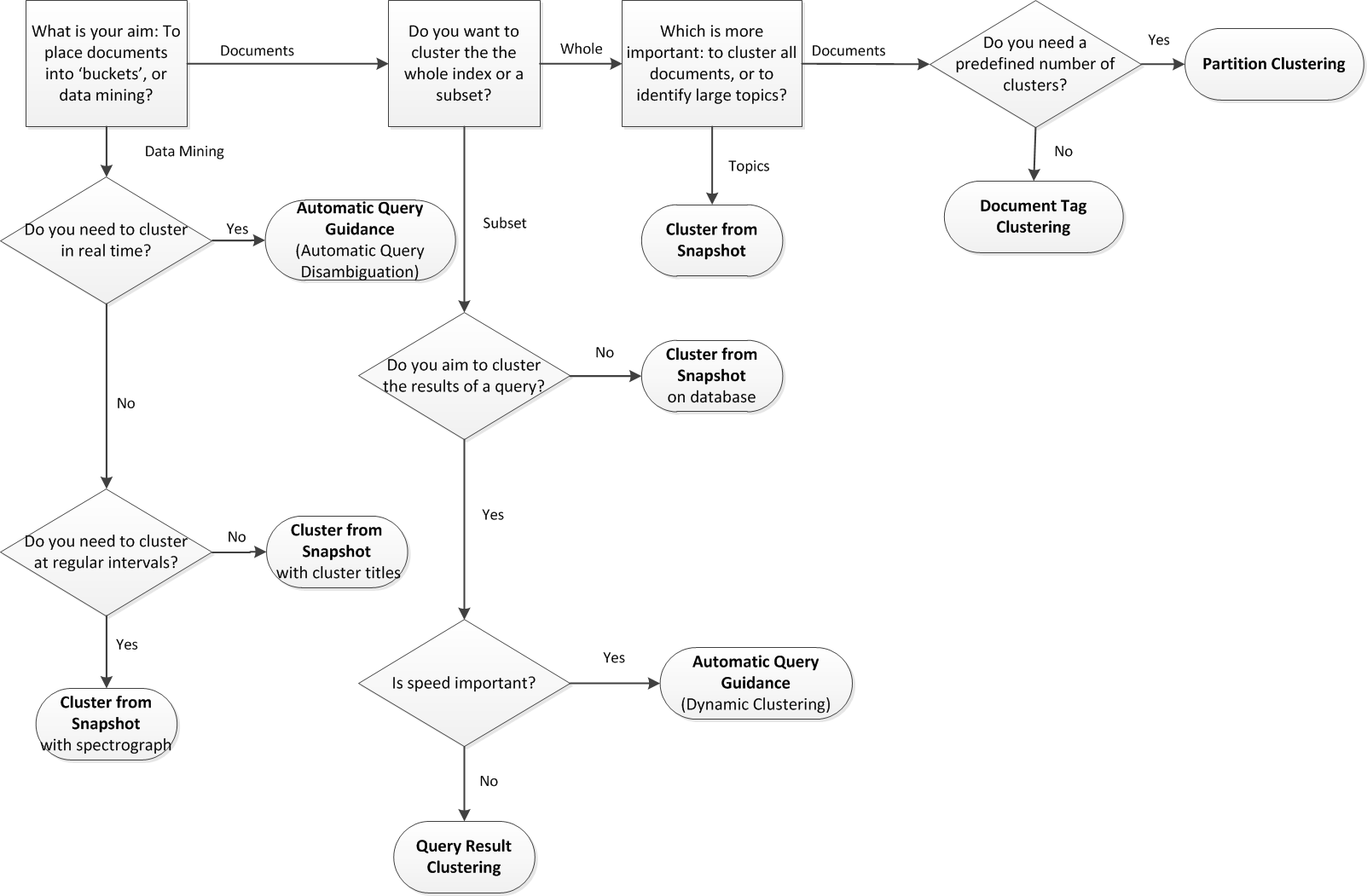
IDOL offers a number of ways to cluster objects, where the objects are usually documents. This section outlines these methods and their uses, and describes how you might decide which method to use. The following sections describe each form of clustering in more detail:
| Skip to: | Cluster from Snapshots |
| Dynamic Clustering | |
| Query Result Clustering | |
| Document Tag Clustering | |
| Partition Clustering | |
| Uses of Clustering for Documents | |
| The Clustering Method to Use |
Main Topic: Cluster from Snapshots
The IDOL Category component can identify clusters, by using representations of the content at a certain point in time. This representation is known as a snapshot.
Clustering from snapshots identifies the largest topic areas in a set of documents. The resulting clusters generally represent a well-defined concept, which you can track over time using a spectrograph, or use as a high-level overview of your content. However, if your set of documents does not contain strong topics, this method might generate few or weak clusters. Additionally, this method does not assign every document to a cluster, because this tends to create poorly-defined groups.
Main Topic: Automatic Query Guidance
Dynamic clustering is a type of automatic query guidance, in which IDOL Server clusters the best terms and phrases in query results. With dynamic clustering, you return the document IDs that the best terms occur in, so that the documents can be considered as clusters.
This method is ideal for real-time analysis of a relatively small set of documents, such as query results. It gives an excellent overview of the document set, by extracting representative phrases. You can also use these phrases to cluster the documents.
Main Topic: Query Result Clustering
With query result clustering, IDOL creates clusters immediately from the results of a query. In this case, all the result documents are placed into clusters.
This method is similar to dynamic clustering, in that it acts on small document sets. It analyzes the documents in greater depth than Dynamic Clustering, and so it is somewhat slower, and less frequently used for query result analysis.
Main Topic: Document Tag Clustering
Document tag clustering allows you to cluster the documents in your index, by using an index action. You can specify the set of documents to cluster.
This method forms an in-depth analysis of a set or subset of documents, and finds similarity at a conceptual level. It tends to form tight clusters that represent precise topics, and so it is ideal for grouping near-duplicate documents, or for a one-time partitioning of static document sets into groups of similar documents.
Partition Clustering rapidly partitions sets of documents into clusters by conceptual similarity. Unlike snapshot clustering, it places all documents into a cluster, however dissimilar. This means that the clusters generated are relatively broad, and might represent a number of topics.
When you have identified clusters, you can use them in a number of interesting and useful ways:
Document sorting. You can use an interesting cluster to create a category, which you can use at index time to categorize and sort new documents.
Document retrieval. Creating categories from clusters allows you to retrieve result documents that match its characteristics.
Data visualization. Identifying the clusters present in a specified time frame allows you to create cluster maps and spectrographs: visual representations of the set of data at a particular moment. Spectrographs also allow you to view how clusters and trends evolve and change.
Document analysis. You can easily retrieve cluster results, and examine the documents in each cluster for patterns or traits. You can also use the cluster titles as a quick summary of your data set.
Query refinement. Some query terms have multiple uses, and dynamic clustering analyzes the query to suggest topics, which you can use to refine the query.
The term Apollo might refer to the space missions, or the Greek or Roman god.
Duplicate content detection. If your index might contain nearly identical content with different references, document tag clustering allows you to identify duplicate instances. See also: Remove Duplicates.
The following flow diagram describes the decision process you must use to decide on the appropriate clustering method for your purposes.
|
|