Importing is the process of converting information that exists in a repository into documents. Documents contain the content and metadata from files or objects in a repository, in a format that IDOL Server can process. Importing information allows IDOL server to use the information in the repository, without needing to process the information in its native format.
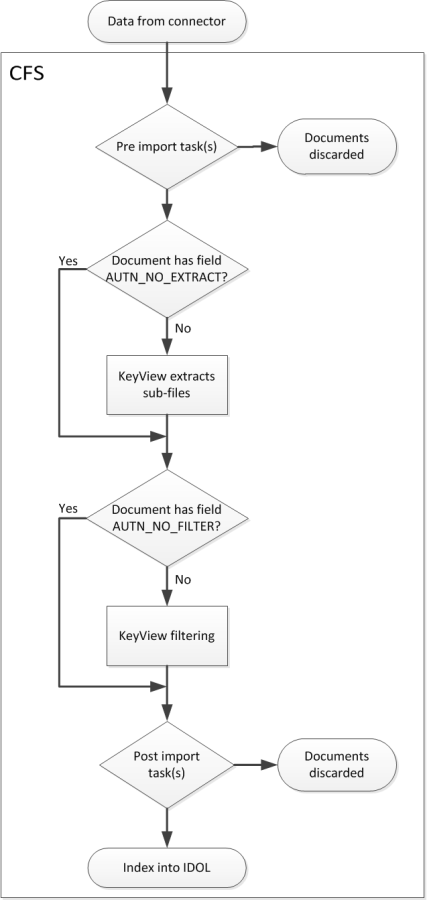
The following diagram shows the steps involved in the import process.
Connectors retrieve information from repositories, and send the information to a Connector Framework Server (CFS). When connectors send documents to CFS, they contain only metadata extracted from the repository, such as the location of a file or record that the connector has retrieved.
CFS uses KeyView to extract sub-files from container files. Sub-files include attachments contained within e-mail messages, and files stored in compressed archives. CFS then uses KeyView to extract the content and metadata from the files and records, and writes it to the documents.
When CFS has finished processing the information, it indexes the documents into IDOL.
During the import process, you can manipulate the documents that are created. To do this, use Import Tasks. Import tasks are processing tasks that are run on documents by CFS. CFS includes import tasks to write documents to disk in IDX or XML format, manipulate and enrich documents, and run Lua scripts. You can run import tasks before and after information is extracted by KeyView. For more information about the import tasks that you can run, refer to the Connector Framework Server Administration Guide.
You can use import tasks to discard documents that you do not want to index. CFS includes import tasks to identify documents that do not contain useful content. Documents are also discarded whenever you run a Lua script and the script's handler function returns false.
Some import tasks can be configured to index failed documents into an IDOL Error Server. Failed documents do not contain valid content. For example, document content might be created by running optical character recognition on an image, and the OCR task might fail to extract any useful information. You can therefore intercept the document and index it into an IDOL Error Server, a content engine that has been configured to store failed documents so that you can review them. You can use an IDOL Error Server to identify failed documents, and then use a connector to retrieve those documents again. For more information about IDOL Error Server, refer to the IDOL Error Server Technical Note.
You can customize the import process by adding the fields AUTN_NO_FILTER and AUTN_NO_EXTRACT to documents. If a document contains the field AUTN_NO_FILTER, CFS does not extract content or metadata from the file or object. If a document contains the field AUTN_NO_EXTRACT, CFS does not extract sub-files. For information about other document fields that you can use to customize processing, see Document Fields that Control Processing.
|
|