

| Concepts of the COBOL Language | Introduction to Compilation Group Definition | |

Some of the "red-tape" statements required by the ANSI Standard COBOL specifications are optional when using this COBOL system. It is, however, possible to have your COBOL system output warning messages when such statements are found to be missing by use of the FLAG directive. Such statements are identified as optional in this manual by enclosing them between brackets which have boxes around them. The symbols next to these boxes indicate the dialect in which these features are optional.
A full list of reserved words is given in the appendix Reserved Words.
The external repository stores information specified in program definitions, class definitions and interface definitions.
The information stored about these source units must consist of all information required for activation and checking conformance. This information includes
This information about a source unit, excluding the externalized name of the source unit, is called its signature.
If a REPOSITORY directive is specified with the ON phrase, the compiler puts this information into the external repository as it compiles each compilation unit.
If a REPOSITORY directive is specified with the CHECKING phrase, either explicitly or by default, the compiler issues a warning when these characteristics of definitions and prototypes do not exactly match the information, if any, in the external repository for the associated definition.
The details on the association of the name of a source unit with information in the external repository are specified in the section REPOSITORY paragraph in the chapter Environment Division.
A CALL prototype is a program declaration or skeleton program which serves to define the characteristics of a called subprogram. These characteristics include the number of parameters required, the type of these parameters and the calling convention. If a source element contains a CALL statement referring to a subprogram for which a prototype exists, the CALL statement is checked against the prototype. If there is an explicit mismatch, an error is given. If the CALL statement leaves some characteristics (such as the call convention) undefined, this is derived from the prototype.
The CALL prototype is defined as a complete program in which the EXTERNAL clause is specified in the PROGRAM-ID paragraph. The program structure should consist only of an IDENTIFICATION DIVISION with a PROGRAM-ID paragraph, a DATA DIVISION with a LINKAGE SECTION, a PROCEDURE DIVISION header, and optional ENTRY statements. These CALL prototypes are placed before the other types of compilation units in a similar way to multi-program source files.
Note that you must include a copy of the CALL prototype for every subprogram to which you want your CALL statements checked before the IDENTIFICATION DIVISION header of your compilation unit containing the CALL statements.

A file connector is a storage area which contains information about a file and is used as the linkage between a file-name and a physical file and between a file-name and its associated record area.
If the words sequential file or sequential organization are used in this chapter without specifying LINE or RECORD, then the sentence applies to both forms. The default behavior for sequential files is sensitive to the SEQUENTIAL Compiler directive.
Record sequential I/O allows the programmer to access records of a file in an established sequence. The sequence is established as a result of writing the records to the file.
Line sequential I/O allows the programmer to access records of a text file in an established sequence. Line sequential files are identical in format to those files produced by your operating system editor. The records are stored with trailing spaces removed.
Sequential files are organized such that each record in the file except the first has a unique predecessor record, and each record except the last has a unique successor record. These predecessor-successor relationships are established by the order of WRITE statements when the file is created. Once established, the predecessor-successor relationships do not change except in the case where records are added to the end of the file.
The only access available for sequential files is sequential access mode; the sequence in which records are accessed is the order in which the records were originally written.
Relative I/O allows the programmer to access records within a mass storage file in either a random or sequential manner. Each record in a relative file is identified by an integer value greater than zero which specifies the record's ordinal position in the file.
Rela tive file organization is permitted only on disk devices. A relative file consists of records which are identified by relative record numbers. The file can be thought of as being composed of a serial string of areas, each capable of holding a logical record. Each of these areas has a relative record number. Records are stored and retrieved via this number. For example, ten denotes the tenth record area.
In sequential access mode, records are accessed in the ascending order of the relative record numbers of those records which currently exist within the file.
In random access mode, the programmer controls the sequence in which records are accessed. The desired record is accessed by placing its relative record number in a relative key data item.
In dynamic access mode, the programmer can change at will between sequential access and random access, using the appropriate forms of input-output statements.
Indexed input-output allows the programmer to access records within a mass storage file in either a random or sequential manner. Each record in an indexed file is identified by the value of one or more keys within that record.
An indexed file is a mass storage file in which data records can be accessed by the value of a key. A record description can include one or more key data items, each of which is associated with an index. Each index provides a logical path to the data records, according to the contents of a data item within each record which is the record key for that index.
The data item named in the RECORD KEY clause of the file control entry for a file is the prime record key for that file. For purposes of inserting, updating and deleting records in a file, each record is identified solely by the value of its prime record key. This value should, therefore, be unique and must not be changed when updating the record.
The data item named in the ALTERNATE RECORD KEY clause of the file control entry for a file is an alternative record key for that file. The value of an alternative record key can be non-unique if the DUPLICATES phrase is specified. These keys provide alternative access paths for retrieval of records from the file.
Your COBOL system provides an
extension which allows the key field to be a split key. A sp
lit key is a key comprising two or more data items, which may or
may not be contiguous, in the record description.
In sequential access mode, records are accessed in the ascending order of the record key values. Records within a set of records which have duplicate record key values are retrieved in the order in which the records were written into the set.
In random access mode, the programmer controls the sequence in which records are accessed. The desired record is accessed by placing the value of its record key in the record key data item.
In dynamic access mode, the programmer can change at will between sequential access and random access, using appropriate forms of input-output statements.
The sharing mode indicates whether a file is to participate in file sharing and record locking, and specifies the degree of file sharing (or non-sharing) to be permitted for the file. The sharing mode specifies the types of operations that may be performed on the shared file through other file connectors throughout the duration of this OPEN.
The SHARING phrase on an OPEN statement overrides the SHARING clause in the file control entry for establishing the sharing mode. If there is no SHARING phrase on the OPEN statement, the sharing mode is completely determined by the SHARING clause in the file control entry. If no specification is made in either location, the sharing mode is determined by the first of the following conditions that is satisfied:
The rules are the same for a given standard sharing mode whether the sharing mode is specified on the open statement, specified in the file control paragraph, or determined from the list above.
COBOL file sharing does not interoperate with other file sharing facilities in the environment.
A shared file must reside on disk.
Before access to a shared file is allowed through an OPEN statement, the sharing mode and the open mode shall be allowed by all other file connectors that are currently associated with the file. Additionally, the sharing mode for the current OPEN statement shall permit all of the sharing modes and open modes that exist for all other file connectors that are currently associated with the file. (See I-O status; OPEN statement; and table 14-3 , Opening available shared files that are currently open by another file connector.)
The sharing mode controls access to a file as follows:
Multiple paths of access may exist in the same runtime element, contained elements, separate runtime modules within the same run unit, or different run units. The file sharing conflict condition can exist regardless of the location of the file connector that holds the file lock of the file to be opened.
The setting of a file lock is part of the atomic operation of an I-O statement.
The file lock and all record locks established for a file connector are removed by an explicit or implicit CLOSE statement executed for that file connector.
An object is a runtime element that consists of its own data and shares the methods defined in its class definition. An object is defined by a class. The class definition describes the characteristics of the data and the methods that may be invoked on each of the objects of the class.
Every class also has a single factory object with its own unique set of data and methods. The factory object is typically used to create object instances, and to maintain data common to all instances of the class.
An object reference is an implicitly- or explicitly-defined data item containing a value -- an object reference value -- that uniquely references an object for the lifetime of the object. . Implicitly-defined object references are the predefined object references and object references returned from an object property. Explicitly-defined object references are data items defined by a data description entry specifying a USAGE OBJECT REFERENCE clause.
No two distinct objects have the same object reference value and every object has at least one object reference.
It is permitted to have more than one object reference for any given object provided the requirements of this standard are fully met, but it is sufficient that a given object has precisely one object reference.
A predefined object reference is an implicitly-generated data item
referenced by one of the identifiers NULL, SELF,
SELFCLASS, and SUPER. Each
predefined object reference has a specific meaning, as described in Predefined
Object Identifiersin the chapter Concepts of the COBOL Language.
The procedural code in an object is placed in methods. Each method has its own method-name and its own data division and procedure division. When a method is invoked, the procedural code it contains is executed. A method is invoked by specifying an identifier that references the object and the name of the method. A method may specify parameters and a returning item.
The procedural code in a method is executed by invoking the method with
an INVOKE statement, referencing a
verb-signature, or
referencing an object property. The method implementation that is bound to
the invocation depends on the class, at runtime, of the object on which
the method is invoked. In particular, it is not necessarily the class
specified statically in the definition of the object reference; it is the
class of the actual object referenced runtime that is used in resolving a
method invocation to a particular method implementation.
If an invocation specifies the object using an object reference, then:
If an invocation specifies the object using a class name, the factory object of the specified class is used as the object on which the method is invoked, and the method invocation will resolve to a factory method.
Method resolution proceeds by applying the first one of the following rules that is applicable:
The term "conformance" is used in this document with several different meanings. In the context of object orientation, the term "conformance" is used to describe a relationship between object interfaces, and it is the basis of such fundamental features as inheritance, interface definitions, and conformance checking.
Note: Conformance checking is done at compile time only, except when using an object modifier and when invoking a method using a universal object reference.
Conformance for objects allows an object to be used according to an interface other than the interface of its own class. Conformance is a unidirectional relation from one interface to another interface and from an object to an interface.
Every object has an interface consisting of the names and parameter specifications for each method supported by the object, including inherited methods. Each class has two interfaces: an interface for the factory object and an interface for the objects.
Interfaces may also be defined independently from a specific class by specifying method prototypes in an interface definition.
An interface interface-1 conforms to an interface interface-2 if and only if
If the description of the returning item of a method in interface-1 directly or indirectly references interface-2, the description of the returning item of the corresponding method in interface-2 shall not directly or indirectly reference interface-1.
When using a parameterized class or interface, the class or interface is treated as if the actual parameter classes or interfaces were substituted for the parameters throughout the class definition or interface definition.
Polymorphism is a feature that allows a given statement to do different things. In COBOL, the ability for a data item to contain various objects of different classes means that a method invocation on that data item can be bound to one of many possible methods. Sometimes the method can be identified before execution, but in general, the method cannot be identified until runtime.
A data item can be declared to contain objects of a given class or any sub-class of that class; it can also be declared to contain objects that conform to a given interface. When a given interface is used, the classes of the objects may be completely unrelated.
Class inheritance is a mechanism for using the interface and implementation of a class as the basis for another class. The inheriting class, also known as a subclass, inherits from a class, known as a superclass. The subclass has all the methods defined for the inherited class definition, including any methods that the inherited definition inherited. The subclass has all the data definitions defined for the inherited class, including any data definitions that the inherited class inherited. These inherited data definitions define inherited data for every object of the subclass and for its factory. The inherited object data are initialized when an object is created. The inherited factory data are allocated independently from the factory data of the inherited class or classes and are initialized when the factory of the subclass is created. The inherited factory data are visible only to factory methods defined in the class that declared the data. The inherited object data are visible only to object methods defined in the class that declared the data. The subclass may define new methods and additional data augmenting the set of inherited methods and the inherited data.
The interface of a subclass shall always conform to the interface of the inherited class, although the subclass may override some of the methods of the inherited class to provide different implementations.
User-defined words in an inherited class are not inherited in the subclass, and may be used in the subclass definition as if they were not defined in the inherited class.
Interface inheritance is a mechanism for using an interface definitions as the basis for another interface. The inheriting interface has all the method specifications defined for the inherited interface definition, including any method specifications that the inherited definition inherited. The inheriting interface may define new methods augmenting the set of inherited method specifications. The inheriting interface must always conform to the inherited interface.
A parameterized class is a generic or skeleton class, which has formal parameters that will be replaced by one or more class-names or interface-names. When it is expanded by substituting specific class-names or interface-names as actual parameters, a class is created that functions as a non-parameterized class.
The life cycle for a parameterized class is defined in Life cycle for parameterized classes later in this chapter.
A parameterized interface is a generic or skeleton interface, which has formal parameters that will be replaced by one or more class-names or interface-names. When it is expanded by substituting specific class-names or interface-names as actual parameters, an interface is created that functions as a non-parameterized interface.
The life cycle for a parameterized interface is defined in Life cycle of parameterized interfaces later in this chapter.
The life cycle for an object begins when it is created and ends when it is destroyed.
A factory object is created before it is first referenced by a run unit.
A factory object is destroyed after it is last referenced by a run unit.
An object is created as the result of the NEW method being invoked on a factory object.
An object is destroyed as the result of the
FINALIZE method being invoked
on an object or when the run unit terminates, which ever occurs first.
An expansion of a parameterized class is treated in all respects the same as if it were a class that is not a parameterized class.
When a parameterized class is specified in the REPOSITORY paragraph, a new class (an instance of a parameterized class) is created based on the specification of the parameterized class. This class has its own factory object and is completely separate from any other instance of the same parameterized class.
Within a run unit, two classes with the same externalized class-name that are created by expanding the same parameterized class with the same actual parameters are the same class instance. If two classes expand a parameterized class with different actual parameters, they are not the same class instance and shall not have the same externalized class-name.
An expansion of a parameterized interface is treated in all respects as if it were an interface that is not parameterized.
When a parameterized interface is specified in the REPOSITORY paragraph, a new interface (an instance of a parameterized interface) is created based on the specification of the parameterized interface.
Within a run unit, two interfaces with the same externalized interface-name that are created by expanding the same parameterized interface with the same actual parameters are the same interface instance. If two interfaces expand a parameterized interface with different actual parameters, they are not the same interface instance and shall not have the same externalized interface-name.
A common program is one which, despite being directly contained in another program, can be called by any program directly or indirectly contained in that other program. The common attribute is attained by specifying the COMMON clause in a program's Identification Division. The COMMON clause facilitates the writing of subprograms which are to be used by all the programs contained in a program.
An initial program is one whose program state is initialized when the program is called. During the process of initializing an initial program, that program's internal data is initialized as described in State of a method, object or program later in this chapter. The initial attribute is attained by specifying the INITIAL clause in the program's Identification Division.
Two runtime elements in a run unit can reference common data in the following circumstances:
Two runtime elements in a run unit can reference common file connectors in the following circumstances:
The Data Division is subdivided into the following sections:
Thread-Local-Storage
Section
Object-Storage Section
Local-Storage Section
 Screen Section.
Screen Section. The File Section defines the structure of data files. Each file is defined by a file description entry and one or more record descriptions. Record descriptions are written immediately following the file description entry.
The Working-Storage Section describes records and noncontiguous data items which are not part of external data files but are developed and processed internally. It also describes data items whose values are assigned in the source text and do not change during execution.
The Thread-Local-Storage
Section describes data which is unique to each thread, and is persistent
across calls. Thread-local-storage can be viewed as thread-specific
working-storage. This is useful for resolving contention problems in most
reentrant programs. In many cases, a non-file-handling program can be made
completely reentrant by simply changing the WORKING-STORAGE section header
to a THREAD-LOCAL-STORAGE section header.
The Object-Storage Section
describes class object data and instance object data. Its structure is the
same as the Linkage and Working-Storage Sections.
The Local-Storage Section identifies a
program as eligible for recursion. The Local-Storage Section can also be
specified in a method, which is also eligible for recursion. A separate
copy of the Local-Storage Section is created each time the runtime element
is activated and exists only during the lifetime of that runtime element.
The Linkage Section appears in a source element that can be activated by another source element. It describes data items that are to be referred to by both the activating and the activated elements. Its structure is the same as the Working-Storage Section.
The Communication Section describes the data item in the source program that will serve as the interface between the Message Control System (MCS) and the program.
The Report Section contains one or more report description entries (RD entries), each of which forms the complete description of a report.
The Screen Section defines the
attributes of the screens. It offers the facility to specify the exact
location of fields when they are displayed on the screen as well as to
control certain console features during an ACCEPT or DISPLAY operation.
Data records and items that
are described in the same way have the same type. The descriptions of such
items can be conveniently manipulated by declaring a type definition. A
type definition can appear in the Working-Storage and Linkage Sections. A
type definition in a call prototype may be referenced in a program
definition.
There are three kinds of internal data items and file connectors: automatic, initial, and static. The designation of automatic, initial, and static items relates to their persistence and the persistence of their contents during the execution of a run unit.
Data items and file connectors have an initial and last-used state. The initial state of a data item depends on the presence or absence of a VALUE clause in its data description entry, the section in which the data item is described, and the description of the data item. The initial state of a file connector is that it is not in an open mode.
Last-used state means that the content of the data item or file connector is that of the last time it was modified.
Automatic items are set to their initial state any time a method or program is activated, and each instance of the method or program has its own copy of the item. An automatic item is an item described in the local-storage section.
Initial items are set to their initial state any time an initial program is activated. All data items and file connectors in an initial program are initial items. Also, an attribute of a screen item in an initial program is treated as an initial item.
Static items are set to their initial state any time a method, object, or program is set to its initial state. (See State of a method, object, or program later in this chapter.) A static item is an item described in the communication, file, or working-storage section of a source element that is not an initial program. Also, an attribute of a screen item in a source element that is not an initial program is treated as a static item.
The state of a method or program at any point in time in a run unit may be active or inactive. When a method or program is activated, its state may also be initial or last-used.
A method or program may be activated recursively. Therefore, several instances of a method or program may be active at once.
An instance of a method is placed in an active state when it is successfully activated and remains active until the execution of a STOP statement or an implicit or explicit EXIT METHOD statement within this instance of this method.
An instance of a program is placed in an active state when it is successfully activated by the operating system or successfully called from a runtime element. An instance of a program remains active until the execution of one of the following:
Whenever an instance of a method or program is activated, the control mechanisms for PERFORM statements contained in that instance of the method or program are set to their initial states and the GO TO statements referred to by ALTER statements are set to their initial states.
When a method or program is activated, the data within is in either the initial state or the last-used state.
Automatic data and initial data is placed in the initial state every time the method or program in which it is described is activated.
Static data is placed in the initial state:
When data in a method or program is placed in the initial state, the following occurs:
Static and external data are the only data that are in the last-used state. External data is always in the last-used state except when the run unit is activated. Static data is in the last-used state except when it is in the initial state as defined above.
The initial state of an object is the state of the object immediately after it is created. Internal data, internal file connectors, and the attributes of screen items are initialized in the same manner as when data in a method or program is placed in the initial state, in accordance with Initial state earlier in this chapter.
A data-name names a data item. A file-name names a file connector. These names are classified as either global or local.
A global name can be used to refer to the item with which it is associated either from within the source element in which the global name is declared, or from within any other source element which is contained in the source element which declares the global name.
A local name, however, can be used only to refer to the item with which it is associated from within the source element in which the local name is declared. Some names are always global; other names are always local; some other names are either local or global depending upon specifications in the source element in which the names are declared.
A record-name is global if the GLOBAL clause is specified in the record description entry by which the record-name is declared or, in the case of record description entries in the File Section, if the GLOBAL clause is specified in the file description entry for the file-name associated with the record description entry.
A data-name is global if the GLOBAL clause is specified either in the data description entry by which the data-name is declared or in another entry to which that data description entry is subordinate.
A condition-name declared in a data description entry is global if that entry is subordinate to another entry in which the GLOBAL clause is specified. However, specific rules sometimes prohibit specification of the GLOBAL clause for certain data description, file description, or record description entries.
A file-name is global if the GLOBAL clause is specified in the file description entry for that file-name.
If a data-name, a file-name, or a condition-name declared in a data description entry is not global, the name is local.
Global names are transitive across source elements contained within other source elements.
Accessible data items usually require that certain representations of data be stored. File connectors require that certain information concerning files be stored. The storage associated with a data item or a file connector can be external or internal.
External and internal items can have either global or local names.
A data record described in the Working-Storage Section is given the external attribute by the presence of the EXTERNAL clause in its data description entry. Any data item described by a data description entry subordinate to an entry describing an external record also attains the external attribute. If a record or data item does not have the external attribute, it is inte rnal.
A file connector is given the external attribute by the presence of the EXTERNAL clause in the associated file description entry. If the file connector does not have the external attribute, it is internal.
The data records described subordinate to a file description entry which does not contain the EXTERNAL clause or a sort-merge file description entry, as well as any data items described subordinate to the data description entries for such records, are always internal. If the EXTERNAL clause is included in the file description entry, the data records and the data items attain the external attribute.
Data records, subordinate data items, and various associated control information described in the Local-Storage, Linkage, Communication, Report and Screen Sections are always internal. Special considerations apply to data described in the Linkage Section whereby an association is made between the data records described and other data items accessible to other runtime elements.
If a data item or file connector is external, the storage associated with that item is associated with the run unit rather than with any particular runtime module within the run unit. An external item can be referenced by any runtime module in the run unit that describes it. References to external items from different runtime modules using separate descriptions of the data item or file connector are always to the same item. In a run unit, there is only one representation of an external item.
If a data item or file connector is internal, the storage associated with it is associated only with the runtime module that describes it.
Execution begins with the first statement of the Procedure Division, excluding declaratives. Statements are then executed in the order in which they occur in the source element, except where the rules indicate some other order.
A statement is a syntactically valid combination of words and symbols beginning with a COBOL verb.
A sentence consists of one or more statements and is terminated by a period followed by a space.
There are four types of statements:
Delimited scope statements.
There are three types of sentences:
A conditional statement specifies that the truth value of a condition is to be determined and that the subsequent flow of control is dependent on this truth value.
A conditional statement is one of the following:
EVALUATE,
IF, SEARCH or RETURN statement
 An ON statement
An ON statement
or ON EXCEPTION
phrase
 An ACCEPT or DISPLAY
statement that specifies the ON EXCEPTION phrase.
An ACCEPT or DISPLAY
statement that specifies the ON EXCEPTION phrase. A conditional sentence is a conditional statement, optionally preceded by an imperative statement, terminated by a separator period followed by a space.
A COBOL system-directing statement consists of a dire cting verb and its operands. The directing verbs are described in the chapter Compiler-Directing Statements:
A COBOL system directing statement causes your COBOL system to take a specified action during creation of the object code.
A COBOL system-directing sentence is a single directing statement terminated by a period followed by a space.
Compiler directives give you options to control the actions of the Compiler. They allow you to enable language features, choose run-time behavior, choose compile-time options, create debugging information, control the format of data files, optimize the object code, and choose SQL options.
 The compiler directives provided by the
standard are described in the section Compiler Directivesin the
chapter Compiler-Directing Statements of this document
The compiler directives provided by the
standard are described in the section Compiler Directivesin the
chapter Compiler-Directing Statements of this document
The syntax of the directives
and a description of each directive provided by this implementation are
given in your On-Line Reference.
An imperative statement indicates a specific unconditional action to be taken . An imperative statement is any statement that is neither a conditional statement nor a COBOL system directing statement. An imperative statement can consist of a sequence of imperative statements, each possibly separated from the next by a separator.
The imperative verbs are:
| ACCEPT1 | ENABLE | RELEASE |
| ADD2 | EXIT | REWRITE3 |
| ALTER | GO TO | SEND |
| CALL4 | INSPECT | SET |
| CANCEL | MERGE | SORT |
| CLOSE | MOVE | START3 |
| COMPUTE2 | MULTIPLY2 | STOP |
| DELETE3 | OPEN | STRING4 |
| DISABLE | PERFORM | SUBTRACT2 |
| DISPLAY1 | READ5 | UNSTRING4 |
| DIVIDE2 | RECEIVE6 | WRITE7 |
| 1 | Without the optional ON EXCEPTION phrase. |
| 2 | Without the optional SIZE ERROR phrase. |
| 3 | Without the optional INVALID KEY phrase. |
| 4 | Without the optional ON OVERFLOW or ON EXCEPTION phrase. |
| 5 | Without the optional AT END phrase or INVALID KEY phrase. |
| 6 | Without the optional NO DATA phrase. |
| 7 | Without the optional INVALID KEY phrase or END-OF-PAGE phrase. |
The additional ANSI'85
imperative verbs are:
| CONTINUE | INITIALIZE | PURGE |
The additional ISO2000 imperative verbs
are:
INVOKE
The additional OS/VS COBOL
impera
tive verbs are:
| EXAMINE | EXHIBIT | GOBACK |
| TRANSFORM |
 The VS COBOL II imperative
verb is:
The VS COBOL II imperative
verb is:
GOBACK
The additional imperative
verbs available to this COBOL system are:
| CHAIN | EXHIBIT | GOBACK |
| NEXT SENTENCE |
When "imperati ve-statement" appears in the general format of statements, "imperative-statement" refers to that sequence of consecutive imperative statements that must be ended by a period or by any phrase associated with a statement containing that "imperative-statement".
Either the connective word "THEN"
or the connective word "AND" can optionally be placed between
any two imperative statements which appear in a single sequence of
imperative statements.
An imperative sentence is an imperative statement terminated by a period followed by a space.
A delimited scope statement is a statement (for example, an IF statement) which is terminated by (that is, has its end-point determined by) a matching explicit scope terminator (in this case END-IF). Thus, all the statements between a delimited scope statement and its paired explicit scope ter minator are deemed to be contained within that delimited scope statement.
Delimited scope statements can be nested, in which case each explicit scope terminator encountered is considered to pair with the nearest preceding unpaired matching delimited scope statement.
Scope delimited statements can also be implicitly terminated, either at the end of a procedural sentence (where all unterminated statements are terminated by the separator period), or by the termination of any containing delimited scope statement.
Note: Not all statements are scope delimitable in this fashion; those statements that are scope delimitable are termed delimited scope statements only if they are explicitly terminated by an explicit scope delimiter.
See the section Explicit And Implicit Scope Terminators in the chapter Concepts of the COBOL Language for further information.
| Category |
Verbs |
|---|---|
| Arithmetic | ADD COMPUTE DIVIDE INSPECT (TALLYING) MULTIPLY SUBTRACT EXAMINE (TALLYING) |
Conditional |
ADD (SIZE ERROR) CALL (OVERFLOW) COMPUTE (SIZE ERROR) DELETE (INVALID KEY) DIVIDE (SIZE ERROR) GO TO (DEPENDING) IF MULTIPLY (SIZE ERROR) READ (END or INVALID KEY) RECEIVE (NO DATA) RETURN (END) REWRITE (INVALID KEY) SEARCH START (INVALID KEY) STRING (OVERFLOW) UNSTRING (OVERFLOW) WRITE (INVALID KEY or END-OF-PAGE) EVALUATE ON |
Data Movement |
ACCEPT (DATE, DAY or TIME) ACCEPT MESSAGE COUNT INSPECT (REPLACING) MOVE STRING UNSTRING EXAMINE TRANSFORM INITIALIZE INSPECT (CONVERTING) SET (TO TRUE) SET (TO FALSE) SET (ADDRESS OF) SET (POINTER) SET (object reference) SET (ADDRESS OF) SET (POINTER) SET (object reference) |
Ending |
EXIT METHOD EXIT PROGRAM  GOBACK GOBACKSTOP |
Input-Output |
ACCEPT (identifier) CLOSE COMMITDELETE DISABLE DISPLAY ENABLE OPEN READ RECEIVE REWRITE ROLLBACKSEND START STOP (literal) UNLOCKWRITE  EXHIBIT EXHIBITPURGE SET (TO ON or TO OFF) |
Inter-Program |
CALL CANCEL CHAIN ENTRY EXEC INVOKE SERVICE SERVICE |
Null Operation |
EXIT CONTINUE |
Ordering |
MERGE RELEASE RETURN SORT |
Procedure Branching |
ALTER CALL EXIT PERFORM/EXIT
PARAGRAPH/EXIT SECTIONGO TO NEXT SENTENCEPERFORM |
Scope Delimiting |
END-ACCEPT END-ADD END-CALL END-DELETE END-DISPLAYEND-DIVIDE END-EVALUATE END-IF END-INVOKEEND-MULTIPLY END-PERFORM END-READ END-RECEIVE END-RETURN END-REWRITE END-SEARCH END-START END-STRING END-SUBTRACT END-UNSTRING END-WRITE |
COBOL System Directing |
BASIS DELETE INSERT $DISPLAY $ELSE $END $IF COPY ENTER USE REPLACE ENTRY EJECT SKIP1 SKIP2 SKIP3 TITLE NOTE ++INCLUDE -INC |
Table Handling |
SEARCH SET |
IF and ON are verbs in the COBOL sense; it is recognized that they are not verbs in English.
The whole of this section refers to fixed format only. Your COBOL system also accepts compilation groups written in free format. See the chapter Introduction to the COBOL Language for details of free format source.
The reference format, which provides a standard method for describing C OBOL source text, is described in terms of character positions in a line on an input-output medium. Your COBOL system accepts source text written in reference format and produces an output listing using reference format. (See the chapter Introduction for a sample source program.)
The rules for spacing given in the discussion of the reference format take precedence over all other rules for spacing.
See also the section Free
Format in the chapter Introduction to the COBOL Language.
The reference format for a line is represented as in Figure 3-1.
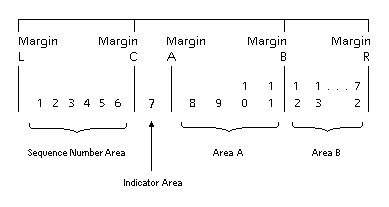
Figure 3-1: Reference Format for a COBOL Source Line
Margin R is immediately to
the right of the 72nd character position of a line. A line can extend up
to the 80th character position, but any characters occupying positions
73 to 80 are ignored by your COBOL system. The sequence number area occupies six character positions (1-6), and is between Margin L and Margin C.
The in dicator area is the 7th character position of a line.
Are a A occupies character positions 8, 9, 10 and 11, and is between margin A and margin B.
A rea B occupies character positions 12 through 72 inclusive; it begins immediately to the right of Margin B and terminates immediately to the left of Margin R.
The program text area consists of both
area A and area B. Text-words can begin anywhere in the program text area.
A se quence number, normally consisting of six digits, can be placed in the sequence area and can be used to label a source line. This sequence number is usually in ascending numeric order on each successive source line.
This sequence number is the
one used by the BASIS mechanism (see the chapter Compiler-Directing
Statements) for line-editing, in which case it must be both numeric
and in ascending order through the program.
The ascending order of sequence numbers can be optionally verified by your COBOL system by using the S EQCHK Compiler di rective.
There is no requirement for
the content of this area to be numeric, or even unique.
If the first character
position of the sequence number field contains an asterisk, or any
non-printing control character (less than the character SPACE in the ASCII
collating sequence), then the line is treated as co
mment, and is not output to the listing file or device. This
facility allows an output li
sting file to be used as a source file to a subsequent compile.
This support is sensitive to the MFCOMMENT Compiler directive.
Whenever a sentence, entry, phrase, or clause requires more than one line, it can be continued by starting subsequent line(s) in area B. These subsequent lines are called the continuation line(s). Any word, literal
or PICTURE character-string
can be broken in such a way that part of it appears on a continuation line.
A hyphen in the indicator area of a line indicates that the first nonblank character in area B of the current line is the successor of the last nonblank character of the preceding line
excluding intervening comment
or blank lines
without any intervening space. However, if the continued line contains a nonnumeric literal without closing quotation mark, the first nonblank character in area B on the continuation line must be a quotation mark, and the continuation starts with the character immediately after that quotation mark. All spaces at the end of the continued line are considered part of the literal. Area A of a continuation line must be blank.
If there is no hyphen in the indicator area of a line, it is assumed that the last character in the preceding line is followed by a space. Both characters composing the separator "==" must be on the same line.
Characters X" and G"
must be on the same line.
Characters H" must be on
the same line.
 Characters N" must be
on the same line.
Characters N" must be
on the same line.
Characters *> must be on
the same line.
Characters >> must be on the same
line.
A blank line is one that is blank from margin C to margin R, inclusive. A blank line can appear anywhere in the source text.
The text words and the separator space comprising pseudo-text can start in either area A or area B. If, however, there is a hyphen in the indicator area of a line which follows the opening pseudo-text delimiter, area A of the line must be blank; and the normal rules for continuation of lines apply to the formation of text words. (See the chapter Compiler-Directing Statements.)
The division header must start in area A. (See Figure 3-1.)
It may start in Area B.
The section header must start in area A. (See Figure 3-1.)
It may start in Area B.
A section consists of zero, one, or more paragraphs in the Environment Division or Procedure Division or zero, one or more entries in the Data Division.
A paragraph consists of a paragraph-name followed by a period and a space, and by zero, one or more sentences, or a paragraph header followed by one or more entries. Comment entries can be included within a paragraph. The paragraph header or paragraph-name starts in area A of any line following the first line of a division or a section.
The first sentence or entry in a paragraph begins either on the same line as the paragraph header or paragraph-name, or in area B of the next nonblank line that is not a comment line. Successive sentences or entries begin either in area B of the same line as the preceding sentence or entry, or in area B of the next nonblank line that is not a comment line.
Sentences can begin anywhere in area A
or area B unless the AREACHECK directive is specified.
When the sentences or entries of a paragraph require more than one line, they can be continued as described in the section Continuation Of Lines earlier in this chapter.
Each Data Division entry begins with a level indicator or a level-number, followed by a space, followed by its associated name
if any
, followed by a sequence of independent descriptive clauses. The last clause is always terminated by a period followed by a space.
There are two types of Data Division entry; those which begin with a level indicator and those which begin with a level-number.
A level indicator is any of the following:
In those Data Div ision entries that begin with a level indicator, the level indicator begins in area A followed by a space and followed in area B
or area A
with its associated name and appropriate descriptive information.
Those Data Division entries that begin with level-numbers are called data description entries.
A level-number has a value taken from the set of values 1 through 49, 66, 77
, 78
and 88. Level-numbers in the range 1 through 9 can be written either as a single digit or as a zero followed by a significant digit. At least one space must separate a level-number from the word following the level-number.
In those data description entries that begin with level-number 01 or 77, the level-number begins in area A followed by a space and followed in area B
or area A
by its associated record-name or item-name and appropriate descriptive information.
Successive data description entries can have the same format as the first and are indented according to level-number. Indentation does not affect the magnitude of a level-number.
When level-numbers are to be indented, each new level-number can begin any number of spaces to the right of margin A. The extent of indentation to the right is determined only by the width of the physical medium.
Data descriptions and level numbers
other than 01 and 77 can also begin in area A.
The key word DECLARATIVES and the key words END DECLARATIVES that precede and follow, respectively, the declaratives portion of the Procedure Division must each appear on a line by themselves. Each must begin in area A and be followed by a separator period (see Figure 3-1).
A comm ent line is any line with an asterisk (*) in the continuation indicator area of the line. A comment line can appear as any line in a source element after the Identification Division header. Any combination of characters from the computer's character set can be included in area A and area B of that line (see Figure 3-1). The asterisk and the characters in area A and area B will be produced on the listing but serve as documentation only.
A comment line can appear
before the Identification Division header.
A second form of comment line represented as above but with a slash (/) (instead of an asterisk) in the indicator area of the line causes page ejection prior to printing the comment.
Successive comment lines are allowed. Continuation of comment lines is permitted, except that each continuation line must contain an asterisk in the indicator area.
An in-line comment begins with the two contiguous characters "*>" preceded by a separator space, and ends with the last character position of the line. It allows free-form commentary to appear on the same line as character-strings and/or separators. An in-line comment can appear anywhere a separator space can appear in a COBOL compilation group or in a library text of a COBOL library. For the purpose of evaluating library text, pseudo-text and source text, an in-line comment has the value of a single space character. An in-line comment cannot be continued onto another line.
Copyright © 1998 Micro Focus Limited. All rights reserved.
This document and the proprietary marks and names
used herein are protected by international law.
| Concepts of the COBOL Language | Introduction to Compilation Group Definition | |