

| Introduction to the COBOL Language | Concepts of a Compilation Group | |
The most basic and indivisible unit of the language is the character. The set of characters used to form COBOL character-strings and separators includes the letters of the alphabet, digits and special characters, and is defined below:
 Lowercase letters can be used in character strings
and text words; except when used in nonnumeric literals and except for
some picture symbols, each lowercase letter is equivalent to the
corresponding uppercase letter.
Lowercase letters can be used in character strings
and text words; except when used in nonnumeric literals and except for
some picture symbols, each lowercase letter is equivalent to the
corresponding uppercase letter.
This COBOL implementation is restricted to the above character set, but the content of nonnumeric literals, comment lines, comment entries and data can include any of the characters available under the character encoding scheme used for the COBOL compilation group. (See the appendix Character Sets and Collating Sequences.)
The individual characters of the language are concatenated to form character-strings and separators. A separator can be concatenated with another separator or with a character-string. A character-string can be concatenated only with a separator. The concatenation of character-strings and separators forms the text of a compilation group.
A separator is a string of one or more punctuation characters. The rules for formation of separators are:
a list of function arguments, reference
modifiers,
arithmetic expressions, or conditions.
 The two contiguous characters 'G"', 'H"',
'N"' and 'X"' and
The two contiguous characters 'G"', 'H"',
'N"' and 'X"' and
the punctuation character quotation mark are separators. These separators must be immediately preceded by a space, left parenthesis or opening pseudo-text delimiter. The closing quotation mark paired with these separators must be immediately followed by one of the separators space, comma, semicolon, period, right parenthesis or closing pseudo-text delimiter. Separators immediately preceding the opening separator are not part of the opening separator. Separators immediately following the closing quotation mark are not part of the closing separator quotation mark.
 The punctuation character apostrophe is a
separator which can be used throughout a compilation group in place of
the quotation mark character.
The punctuation character apostrophe is a
separator which can be used throughout a compilation group in place of
the quotation mark character.
Both the quotation mark and the apostrophe can
appear within the same source element. If they do, they must be in
balanced pairs.
The space immediately preceding the opening
pseudo-text delimiter can be omitted.
Pseudo-text delimiters can appear only in balanced pairs delimiting pseudo-text
and verb-signatures
. (See the chapters Compiler-Directing Statements and ect COBOL Language Extensions.)
Any punctuation character which appears as part of the specification of a PICTURE character-string (see the chapter Data Division - Data Description) or numeric literal is not considered to be a punctuation character, but rather a symbol. PICTURE character-strings are delimited only by the separators space, comma, semicolon, or period.
The rules established for the formation of separators do not apply to the characters which comprise the contents of nonnumeric literals, comment-entries, or comment lines.
A character-string is a character or a sequence of contiguous characters forming a COBOL word, a literal, a PICTURE character-string, or a comment-entry. A character-string is delimited by separators.
A COBOL word is a character-string of not more than
30 characters which forms a compiler-directive word, a context-sensitive
word, user-defined word, a system-name, a reserved word, or
an intrinsic-function-name.
Each character of a COBOL word that is not a special character word is
selected from the set of letters, digits, the hyphen
 and the underscore.
and the underscore.
The hyphen
or the underscore
may not appear as the first or last character in such words. Each
lowercase letter is considered to be equivalent to its corresponding
uppercase letter.
The character-string may contain 31 characters.
Within a source element the following apply:
User-Defined Words: A user-defined word is a COBOL word that must be supplied by the user to satisfy the format of a clause or statement.
The types of user-defined words are:
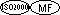 class-name for object orientation class-name for truth value propositionconstant-namefunction-prototype-nameinterface-namemethod-nameparameter-nameproperty-nameroutine-name
class-name for object orientation class-name for truth value propositionconstant-namefunction-prototype-nameinterface-namemethod-nameparameter-nameproperty-nameroutine-name  screen-name split-key-namesymbolic-charactertypedef-name user-function-name
screen-name split-key-namesymbolic-charactertypedef-name user-function-nameWithin a given source element the following user-defined words are grouped into the following disjoint sets:
class-names for object orientation class-names for truth value proposition constant-names, property-names, split-key-names, typedef-namesfunction-prototype-namesinterface-namesmethod-namesparameter-namesroutine-names screen-namessymbolic-charactersuser-function-namesAll user-defined words, except segment-numbers and level-numbers, can belong to one and only one of these disjoint sets. Furthermore, all user-defined words within a given disjoint set must be unique, except as specified in the section Uniqueness Of Reference of this chapter.
With the exception of paragraph-name, section-name, level-number and segment-number, all user-defined words must contain at least one alphabetic character
or one occurrence of the hyphen character .
Segment-numbers and level-numbers need not be unique; a given specification of a segment-number or level-number can be identical to any other segment-number or level-number and can even be identical to a paragraph-name or section-name.
The following user-defined words are externalized to the operating environment:
class-names, function-prototype-names,interface-names, and method-names user-function-names
EXTERNAL attribute.If a literal is specified in place of or in addition to one of these names, the content of the literal is the name that is externalized to the operating environment in a case-sensitive manner. If no literal is specified, the externalized name is created by folding the name to upper case. The Compiler directive FOLD-CALL-NAME can be used to control the case of externalized class-names, interface-names and program-names. The F and U options of the Compiler directive OOCTRL can be used to control the case of externalized method-names. +F and -U cause method-names to be folded to lower case, which is the default.
System-Names: A system-name is a COBOL word that is used to communicate with the operating environment.
System-names must contain at least one alphabetic character
or one occurrence of the hyphen character.
There are three types of system-names:
Within a given implementation these three types of system-names form disjoint sets; a given system-name can belong to one and only one of them.
The system-names listed above are individually defined in The Glossary.
Intrinsic-function-names:
An intrinsic-function-name
is a word that is one of a specified list of words which can be used in
COBOL source elements. The same word, with the exception of LENGTH, RANDOM
and SUM, in a different context, can appear in a source element as a
user-defined word or a system-name. (See the section Definitions
of Functions in the chapter Procedure Division - Intrinsic
Functions.)
Reserved Words: A reserved word is a COBOL word that is one of a specified list of words which can be used in COBOL compilation groups, but which must not appear in the compilation groups as user-defined words or system-names. Reserved words can be used only as specified in the general formats. (See the appendix Reserved Words.)
The types of reserved words are:
predefined object identifiers.
Context-sensitive Words: A context-sensitive word is a
COBOL word that is reserved only in the general formats in which it is
specified. The same word may also be used as an
intrinsic-function-name, a
user-defined word or a system-name. Context-sensitive words and the
contexts in which they are reserved are specified in the appendix Context-sensitive
Words.
When source elements are directly or indirectly contained within other source elements, each source element can use identical user-defined words to name items independent of the use of these user-defined words by other elements. (See the section User-defined words earlier in this chapter.) When identically named items exist, a source elements's reference to such a name, even when it is a different type of user-defined word, is to the item which that source element describes rather than to the item possessing the same name, described in another source element.
The following types of user-defined words can be referenced only by statements and entries in the source element in which the user-defined word is declared:
The following types of user-defined words can be referenced throughout a compilation group:
The following types of names, when declared in a Configuration Section, can be referenced only by statements and entries either in the source element that contains that Configuration Section or in any source element contained within that source element:
Specific conventions, for declarations and references, apply to the following types of user-defined words when the conditions listed above do not apply:
class-name (for object orientation) function-prototype-nameinterface-name method-name screen-name typedef-name user-function-name
The program-name of a program is declared in the Program-ID paragraph of
the program`s Identification Division. A program-name can be referenced
only by the CALL statement,
the CHAIN statement,
the CANCEL statement,
the SET statement
and the END PROGRAM header. If two programs in a run unit are identically
named, at least one of those two programs must be directly or indirectly
contained within a separate program which does not contain the other of
those two programs.
The following rules regulate the scope of a program-name:
When condition-names, data-names, file-names, record-names, report-names
and
typedef-names
are declared in a source element, they can be referenced only by that
source element unless one or more of the names is global and the source
element contains other source elements.
The requirements governing the uniqueness of the names declared by a
single source element to be condition-names, data-names, file-names,
record-names, report-names and
typedef-names
are explained in the section User-Defined Words earlier in this
chapter.
A source element cannot reference any condition-name, data-name,
file-name, record-name, report-name, or
typedef-name
declared in any source element it contains.
A global name can be referenced in the source element in which it is declared or in any source elements which are directly or indirectly contained within that source element.
When a source element, source element B, is directly contained within
another source element, source element A, both source elements can define
a condition-name, a data-name, a file-name, a record-name, a report-name
or a
typedef-name
using the same user-defined word. When such a duplicate-name is
referenced in source element B, the following rules are used to determine
the referenced item:
If a data item possessing the global attribute includes a table described with an index-name, that index-name also possesses the global attribute. Therefore, the scope of an index-name is identical to that of the data-name which names the table whose index is named by that index-name and the scope of name rules for data-names apply.
Index-names cannot be qualified.
 Index-names can be qualified.
Index-names can be qualified.
The class-name of a class referenced within a source element must be
either the name of the containing class definition or declared in the
REPOSITORY paragraph or the
CLASS-CONTROL paragraph
of that or a containing source element.
Within a compilation group, there must be at most one Class Definition for a given class-name.
The interface-name of an interface referenced within a source element must be either the name of the containing interface definition or declared in the REPOSITORY paragraph of that or a containing source element.
Within a compilation group, there must be at most one interface definition for a given interface-name.
A class-name or interface-name declared in the CLASS-CONTROL paragraph or the REPOSITORY paragraph of a source element may be used in that source element and any nested source element.
A method-name of a method is declared in the METHOD-ID paragraph. A method-name must be referenced only by the INVOKE statement and the end method header.
The methods declared in a Class Definition shall have unique method-names within that Class Definition. The methods declared in a child class may have the same name as a method in the parent class, subject to the conditions for the METHOD-ID paragraph.
The methods declared in an interface definition must have unique method-names within that interface definition. The methods declared in an inheriting interface can have the same name as a method in the inherited interface, subject to the conditions stated for the METHOD-ID paragraph.
Function-prototype-names referenced within a source element shall be either the name of the containing function definition or declared in the REPOSITORY paragraph of that or a containing source element.
If a function prototype is specified in a REPOSITORY paragraph and the function prototype declaring the same function-prototype-name is also specified within the same compilation group, the function prototype specification is used and the information in the external repository for this prototype is ignored.
a user-defined word which references a constant
value Every literal belongs to one of two types; nonnumeric or numeric.
A nonnumeric literal is a character-string delimited at both ends by quotation marks
or apostrophes
and consisting of any allowable character in the computer's character set. Nonnumeric literals may be of 1 to 160 characters in length. Whether quotation marks
or apostrophes
are used as delimiters, the presence of that delimiter within a nonnumeric literal can be represented by two contiguous occurrences. The presence of the character that is not serving as the delimiter is represented by a single occurrence. The value of a nonnumeric literal in the runtime element is the string of characters itself, except:
All other punctuation characters are part of the value of the nonnumeric literal rather than separators; all nonnumeric literals are category alphanumeric. (See the section The PICTURE Clause in the chapter Data Division - Data Description.)
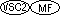 In addition, hexadecimal binary values can be
attributed to nonnumeric literals by expressing literals as: X"nn",
where each n is a hexadecimal digit in the set 0-9 A-F; nn
can be repeated up to 160 times, but the number of hexadecimal digits must
be even.
In addition, hexadecimal binary values can be
attributed to nonnumeric literals by expressing literals as: X"nn",
where each n is a hexadecimal digit in the set 0-9 A-F; nn
can be repeated up to 160 times, but the number of hexadecimal digits must
be even.
The number of hexadecimal digits may be odd.
Numeric literals can be either fixed-point or floating-point numbers.
A numeric literal is a character-string whose characters are selected from the digits "0" through "9" , the plus sign, the minus sign, and the decimal point. This implementation allows for numeric literals of 1 to 18 digits in length. The rules for the formation of numeric literals are as follows:
If a literal conforms to the rules for the formation of numeric literals, but is enclosed in quotation marks, it is a nonnumeric literal and is treated as such by your COBOL system.
The size of a numeric literal in standard data format characters is equal to the number of digits specified by the user.
In addition, hexadecimal binary values can be
attributed to numeric literals by expressing literals as: H"nn",
where each n is a hexadecimal digit in the set 0-9
A-F; nn can be repeated up to 8 times, but the
number of hexadecimal digits must be even.
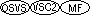
A floating-point literal is written in the form:

The sign is optional before the mantissa and the exponent: if you omit the sign, the system assumes a positive number.
The mantissa can contain between 1 and 16 digits. A decimal point must be included in the mantissa.
The exponent is represented by an E followed by an optional sign and one or two digits.
The magnitude of a floating-point literal value must fall between 0.54E-78 and 0.72E+76. For values outside this range, a diagnostic will be produced and the value will be replaced by 0 or 0.72E+76 respectively. You must not use a floating-point literal when an integer literal is required.
Figurative constant values are generated by your COBOL system and referenced through the use of the reserved words given below. These words must not be bounded by quotation marks when used as figurative constants. The singular and plural forms of figurative constants are equivalent and can be used interchangeably.
The figurative constant values and the reserved words used to reference them are shown in Table 2-1.
Table 2-1: Figurative Constants and Their Reserved Words
| Constant | Representation |
|---|---|
| ZERO ZEROS ZEROES |
Represents the value "0", or one or more of the character "0" depending on the context. |
| SPACE SPACES |
Represents one or more of the character space from the computer's character set. |
| HIGH-VALUE HIGH-VALUES |
Represents one or more of the character that has the highest ordinal position in the program collating sequence. (x"FF" for the extended ASCII character set.) |
| LOW-VALUE LOW-VALUES |
Represents one or more of the character that has the lowest ordinal position in the program collating sequence. (x"00" for the ASCII character set.) |
| QUOTE QUOTES |
Represents one or more of the character """. The word QUOTE or QUOTES cannot be used in place of a quotation mark in a source program to bound a nonnumeric literal. Thus QUOTE ABD QUOTE is incorrect as a way of stating "ABD". |
| ALL literal | Represents one or more characters of the string of characters comprising the literal. The literal must be either a nonnumeric literal or a figurative constant other than ALL literal. When a figurative constant is used, the word ALL is redundant and is used for readability only. |
|
NULL NULLS |
Represents one or more unset pointer
values. A data item with USAGE POINTER
and with a value of NULL is guaranteed not to represent the address of any data item
The NULL value varies between environments and is generally consistent with the equivalent value used in non-COBOL languages for each environment. |
When a figurative constant represents a string of one or more characters, the length of the string is determined by your COBOL system from context according to the following rules:
Use of figurative constants in Format 3 DISPLAY
statements has specific effects, described in the General Rules for
that statement.
A figurative constant can be used wherever a literal appears in a format, except that whenever the literal is restricted to having only numeric characters in it, the only figurative constant permitted is ZERO (ZEROS, ZEROES).
When the figurative constants HIGH-VALUE(S) or LOW-VALUE(S) are used , the actual character associated with each figurative constant depends upon the program collating sequence specified. (See the sections The OBJECT-COMPUTER Paragraph and The SPECIAL-NAMES Paragraph in the chapter Environment Division.)
Each reserved word that is used to reference a figurative constant value is a distinct character-string, with the exception of the construction "ALL literal" which is composed of two distinct character-strings.
The value associated with the
QUOTE/QUOTES figurative constant is sensitive to the
APOST and
QUOTE directives.
The figurative constant ALL literal, when associated
with a numeric or numeric edited item, and when its length is greater than
one, is classed as an obsolete element in the ANSI'85 standard and is
scheduled to be deleted from the next full revision of the ANSI Standard.
All dialects within this COBOL implementation fully
support this obsolete ALL literal syntax. The FLAGSTD directive can be
used to detect all occurrences of this syntax.
 Although this obsolete ALL literal syntax is a part
of the standard COBOL definition, this syntax is explicitly excluded from
the X/Open COBOL language definitions and should not be used in a
conforming X/Open COBOL source program.
Although this obsolete ALL literal syntax is a part
of the standard COBOL definition, this syntax is explicitly excluded from
the X/Open COBOL language definitions and should not be used in a
conforming X/Open COBOL source program.
Constant-names are user-defined words described in the DATA DIVISION in level-78 data description entries. A constant-name may be used wherever a literal appears in a format. Its effect is as if the literal in the VALUE clause of its data description had been written instead. A constant-name with an integer value can also be used wherever a format requires an integer; for example, as a level number or segment number, or in a PICTURE character-string.
A constant-name can only be used after it has been described; that is, it cannot be the object of a forward reference.
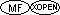
A concatenation expression consists of two operands separated by the concatenation operator.

Special registers are data items or transient values generated by your COBOL system and referred through the use of their associated names or expressions (see Table 2-2). These special registers are subject to special rules of reference and have implicit data descriptions (PICTUREs), as individually described. See the section COBOL Words earlier in this chapter.
Table 2-2 : Special Registers
| Special Register name or expression | Implicit Data Description Picture | Usage |
|---|---|---|
|
ADDRESS OF data-name-1 |
USAGE IS POINTER | The expression generates a pointer value representing
the address of data-name-1. The expression is explicitly shown in the
general format for statements in which it can be used. Data-name-1 shall
be a data item declared in the Linkage Section with a level number or 01
or 77
|
|
CURRENT-DATE1 |
X(8) | The CURRENT-DATE special register contains the value
of the current date (as supplied by the COBOL
execution environment), in the form:MM/DD/YY where MM is the month number, DD
is the day of the month, and YY is the year number
(from 1900). CURRENT-DATE is valid only as the sending area of a MOVE
statement. |
|
LENGTH OF data-name-22 |
9(9) | The expression generates a value representing the
current number of bytes of storage used by data-name-2. The expression can be used wherever a numeric data item can be used except as a subscript or a reference modifier.
|
|
RETURN-CODE3 |
S9(4) COMP
|
The RETURN-CODE special register can:
A program's RETURN-CODE is set to zero when that program is first entered. The RETURN-CODE is valid as a data-name in a Procedure Division statement wherever an elementary data item can be referenced. |
 SHIFT-IN SHIFT-IN |
X(1) | Used to switch the character representation from double byte characters (DBCS) back to single byte characters (SBCS) in environments where this is applicable. |
|
SHIFT-OUT |
X(1) | Used to switch the character representation from single byte characters (SBCS) to double byte characters (DBCS) in environments where this is applicable. |
|
SORT-CONTROL
|
X(8) S9(8) COMP |
These items can be referenced in the Procedure Division but will contain either zeros (for numeric registers) or spaces (for alphanumeric registers). |
|
SORT-RETURN |
S9(4) COMP | SORT-RETURN can be used to cause an abnormal termination of a SORT procedure. If a value of 16 is moved into this field, the SORT operation will be terminated after the next RELEASE or RETURN. |
 TALLY TALLY |
9(5) COMP | The TALLY special register contains information produced by the EXAMINE...TALLYING statement. It is valid as a data-name in a Procedure Division statement wherever an elementary data item can be referenced. |
|
TIME-OF-DAY |
9(6) DISPLAY | The TIME-OF-DAY special register contains the value of
the current time of day (24-hour clock) (as supplied by the COBOL
execution environment), in the form:hhmmsswhere hh =hour, mm=minutes,
and ss=seconds. TIME-OF-DAY is valid only as the
sending area of a MOVE statement. |
|
WHEN-COMPILED |
X(20) | The WHEN-COMPILED special register contains the time
and date that the COBOL compilation
group was submitted to your COBOL system, in the form:hh.mm.ssMMM DD, YYYYwhere hh=hours (24-hour clock), mm=minutes,
ss=seconds, MMM=month name
(first 3 characters), DD=day of month, and YYYY=year.
WHEN-COMPILED is valid only as the sending area of a MOVE statement. |
|
WHEN-COMPILED |
X(20) | The WHEN-COMPILED special register contains the time
and date that the COBOL compilation group was submitted to your COBOL
system, in the form:MM/DD/YYhh.mm.sswhere DD, hh, mm and ss are
as above. YY=year in century and MM=month
in year.
WHEN-COMPILED is valid only as the sending area of a MOVE statement. |
Notes: Certain special registers are sensitive to Compiler directives and dialects.
| Predefined Object Identifier | Usage |
|---|---|
|
SELF |
References the object on which the current method is executing. May be used in the Procedure Division of a method. References the object that was used to invoke the method in which SELF appears. If SELF is specified for a method invocation, the search for the method includes all methods declared for the object. |
|
SELFCLASS |
References the object that is the class object of the current object (SELF). If SELF is itself a class object, SELFCLASS is the system class BEHAVIOR. The class object BEHAVIOR terminates this self-reference. (i.e., If SELF is the BEHAVIOR of class, so is SELFCLASS.) |
|
SUPER |
References the object on which the current method is executing. May be used in the Procedure Division of a method. May be the object used to invoke a method with the INVOKE statement. References the object that was used to invoke the method in which SELF appears. If SUPER is specified for a method invocation, the search for the method ignores all the methods defined in the same class as the executing method. |
|
NULL |
References the null object reference value, which is a unique value that is guaranteed to never reference an object. NULL is implicitly described as class object and category object reference, and is not a universal object reference. NULL must not be specified as a receiving operand. |
A PICTURE character-string consists of certain combinations of characters in the COBOL character set, used as symbols. See the section The PICTURE Clause in the chapter Data Division - Data Descriptionfor the PICTURE character-string and for the rules that govern its use.
Any punctuation character that appears as part of the specification of a PICTURE character-string is not considered to be a punctuation character, but a symbol used in the specification of that PICTURE character-string.
A comm ent-entry is an entry in the Identification Division that can be any combination of characters from the computer's character set. A comment-entry is for documentary purposes only, may extend over more than one line and is terminated upon encountering a division, section or paragraph name that is a reserved word
or encountering any character
in area A of a line. The continuation of a comment-entry by the use of the hyphen in the indicator area is not permitted.
A general format is the specific arrangement of the elements of a clause or a statement. Throughout this document a format is shown adjacent to information defining the clause or statement. When more than one specific arrangement is permitted, the general format is separated into numbered formats. Clauses must be written in the sequence given in the general formats. (Clauses that are optional must appear in the sequence shown if they are used.) In certain cases, stated explicitly in the rules associated with a given format, the clauses can appear in sequences other than that shown. Applications, requirements or restrictions are shown as rules.
Syntax rules are those rules that define or clarify the order in which words or elements are arranged to form larger elements, such as phrases, clauses, or statements. Syntax rules also impose restrictions on individual words or elements.
These rules are used to define or clarify how the statement must be written; that is, the order of the elements of the statement and restrictions on what each element may represent.
General rules are those rules that define or clarify the meaning or relationship of meanings of an element or set of elements. They are used to define or clarify the semantics of the statement and the effect that it has on either execution or on the way intermediate code is produced.
Elements which make up a clause or a statement consist of uppercase words, lowercase words, level-numbers, brackets, braces, connectives and special characters.
To make data as computer-independent as possible, the characteristics or properties of the data are described in relation to a standard data format rather than to an equipment-oriented format. This standard data format is oriented to general data processing applications and uses the decimal system to represent numbers (regardless of the radix used by the computer) and the remaining characters in the COBOL character set to describe nonnumeric data items.
A level concept or hierarchy is inherent in the structure of a logical data record. This concept arises from the need to specify subdivisions of a record for the purpose of data reference. Once a subdivision has been specified, it can be further subdivided to permit more detailed data referral.
The most basic subdivisions of a record, that is, those not further subdivided, are called elementary items; consequently, a record is said to consist of a sequence of elementary items, or the record itself can be an elementary item.
In order to refer to a set of elementary items, the elementary items are combined into groups. Each group consists of a named sequence of one or more elementary items. Groups, in turn, can be combined into groups of two or more groups, and so on. Thus, an elementary item can belong to more than one group.
A system of level-numbers shows the organization of elementary items and group items. Since records are the most inclusive data items, level-numbers for records start at 01. Less inclusive data items are assigned higher (not necessarily successive) level-numbers not greater in value than 49. A maximum of 49 levels in a record is allowed. There are special level-numbers, 66, 77
, 78
and 88 which are exceptions to this rule (see below). Separate entries are written for each level-number used.
A group includes all group and elementary items following it until a level-number less than or equal to the level-number of that group is encountered. All items which are immediately subordinate to a given group item should be described using identical level-numbers greater than the level-number used to describe that group item
; this rule is not insisted upon.
Example
| Correct |
Incorrect but Permitted |
|---|---|
01 A.
05 C-1.
10 D PICTURE X.
10 E PICTURE X.
05 C-2.
|
01 A.
05 C-1.
10 D PICTURE X.
10 E PICTURE X.
04 C-2.
|
Four types of entries exist for which there is no true concept of level. These are:
Entries that specify constant-names. Entries describing items by means of RENAMES clauses for the purpose of regrouping data items have been assigned the special level-number 66.
Entries that specify noncontiguous data items, which are not subdivisions of other items, and are not themselves subdivided, have been assigned the special level-number 77.
Entries that specify condition-names, to be associated with particular values of a conditional variable, have been assigned the special level-number 88.
Entries that specify constant-names, to be
associated with the value of a particular literal, have been assigned the
special
level-number 78.

Figure 2-1: Example of Level-numbers Representing a Data Hierarchy
Note that indentation of COBOL source code is a readability convention only and is not part of the language.
Elementary items are by definition those items without any subordinate entries (entries without numerically greater level-numbers) following, and must have a storage definition associated with them (see the sections The PICTURE Clause and The USAGE Clause in the chapter Data Division - Data Description).
Note that only elementary items (marked with an asterisk, "*", above) and FILLER items (marked with a "#" sign above) will have storage explicitly reserved for them (in accordance with the associated PICTURE clause); non-elementary items have implicit storage associated with them of size determined by their subordinate items plus any FILLER bytes needed for synchronization (see the section The SYNCHRONIZED Clause in the chapter Data Division - Data Description).
Level-numbers need not be consecutively ascending or descending as shown above for clarity; thus, the next subordinate level after 01 could be 05, and the next level 10, and so on.
The above data descriptions would produce storage allocation in the following manner:

Figure 2-2: Data Record Storage Allocation
where:
| R-E-I | is Record-Entry-Item |
| M-G-I | is Major-Group-Item |
| R-G-I | is Regular-Group-Item |
| S-G | is Sub-Group |
| EI | is Elementary-Item |
| NEI | is Noncontiguous Elementary-Item |
Every elementary data item, every literal, and every function has a
class and a category. The class and category of a data item are defined by
its picture character string, by the BLANK WHEN ZERO clause, or by its
usage;
the class and category of an intrinsic function are
specified by the definition of that intrinsic function (see the chapter
Procedure Division - Intrinsic Functions);
and the class and category of a literal are defined in the section Literals
earlier in this chapter.
The category of a group item is alphanumeric.
The following table depicts the relationship of categories to classes of data for elementary items.
Table 2-3: Category and class relationships for elementary items
| Class | Category |
|---|---|
| Alphabetic | Alphabetic |
| Alphanumeric | Numeric Edited Alphanumeric Edited Alphanumeric DBCS |
| Index | Index |
| Numeric | Numeric Internal Floating-point External Floating-point |
| Object |
Object-reference |
| Pointer |
Data-pointer Program-pointer Program-pointer |
Algebraic signs fall into two categories:
The SIGN clause permits the programmer to state explicitly the location of the operational sign. The clause is optional; if it is not used, operational signs will be represented as described in the section Selection of Character Representation and Radix.
Editing signs are inserted into a data item through the use of the sign control symbols of the PICTURE clause.
The standard rules for positioning data within an elementary item depend on the category of the receiving item. These rules are:
If the receiving data item is external
floating-point, the leftmost non-zero digit, if one exists, is aligned
on the leftmost digit position: the exponent is adjusted accordingly.
If the JUSTIFIED clause is specified for the receiving item, these standard rules are modified as described in the section The JUSTIFIED Clause in the chapter Data Division - Data Description.
Some computer memories are organized so that natural addressing boundaries exist in the computer memory (for example, word boundaries, half-word boundaries, byte boundaries). The way in which data is stored need not respect these natural boundaries.
However, certain uses of data (for example, in arithmetic operations or in subscripting) can be facilitated if the data is stored so as to be aligned on these boundaries. Specifically, additional machine operations in the runtime element can be repeated for the accessing and storage of data if portions of two or more data items appear between adjacent natural boundaries, or if certain natural boundaries divide a single data item.
Data items which are aligned on these natural boundaries in such a way as to avoid additional machine operations are defined to be synchronized. A synchronized item is assumed to be introduced and carried in that form; conversion to synchronized form occurs only during the execution of a statement (other than READ or WRITE) which stores data in the item.
Synchronization can be accomplished in two ways:
By use of the SYNCHRONIZED clause, the use of special types of alignment within a group can affect the results of statements in which the group is used as an operand. The effect of the implicit FILLER and the semantics of any statement referencing these groups is described later in this chapter.
The value of a numeric item (defined as numeric by its PICTURE, see the section The PICTURE Clause - Numeric Data Rules in the chapter Data Division - Data Description) can be represented in the computer's storage in either binary or decimal form depending on the USAGE clause of the declaration (see the section The USAGE Clause in the chapter Data Division - Data Description). These numeric formats are:
 COMPUTATIONAL-3,
COMP-3 or
COMPUTATIONAL-5,
COMP-5,
COMPUTATIONAL-X or
COMP-X
COMPUTATIONAL-1,
COMPUTATIONAL-2, FLOAT-SHORT or FLOAT-LONG
POINTER
PROCEDURE-POINTER
COMPUTATIONAL-3,
COMP-3 or
COMPUTATIONAL-5,
COMP-5,
COMPUTATIONAL-X or
COMP-X
COMPUTATIONAL-1,
COMPUTATIONAL-2, FLOAT-SHORT or FLOAT-LONG
POINTER
PROCEDURE-POINTER
An alphanumeric function is always represented in
the standard data format. Its size is determined by the definition of the
function.
The representation of integer and numeric functions is as follows:
Integer and numeric functions can be used only in arithmetic expressions, and represent the value resulting from the evaluation of the function without the restriction on composite of operands and/or receiving data items.
When a computer provides more than one means of representing data, the standard data format must be used for data items
other than integer and numeric functions,
if not otherwise specified by the data description.
The COBOL digit characters from 0 to 9 that represent the number value are held in radix 10, one digit character per byte of computer storage. This is the standard data format of the COBOL language. If the data item is signed and the sign is not specified as SEPARATE (see the section The SIGN Clause in the chapter Data Division - Data Descriptionand the NUMERIC SIGN clause in the section The Special-Names Paragraph in the chapter Environment Division) the numeric sign is incorporated into either the leading or trailing digit, according to the LEADING or TRAILING phrase in the SIGN clause. Signed data is incorporated into the requisite digit as shown in Table 2-4 below. (Effectively, bit 6 (hexadecimal value "40" ) of the character is set from 0 to 1 if the number has a negative value.) If the data item is signed and the sign is specified as SEPARATE, then the sign is held as a separate single COBOL character, additional to the digits, either plus (+) or minus (-) as necessary. If the data item is signed and no SIGN clause applies, the numeric sign is incorporated into the trailing digit, unless the NUMERIC SIGN clause is specified in the Special-Names paragraph. If the SIGN clause is specified in a data description entry, the NUMERIC SIGN clause, if specified, is ignored for that entry.
In the following table, the numbers in brackets represent the hexadecimal encoding for the COBOL character. On some systems, the encoding can be varied by the CHARSET and SIGN Compiler directives.
Table 2-4 : DISPLAY Non-SEPARATE Sign-Digit Characters
| Leading or trailing value digit before sign incorporation | Sign Digit Character for: | |||||
|---|---|---|---|---|---|---|
| Positively-signed values | Negatively-signed values | |||||
| Charset (ASCII) | Charset (EBCDIC) | Charset (ASCII) | Charset (EBCDIC) | |||
| Sign (ASCII) | Sign (EBCDIC) | Sign (EBCDIC) | Sign (ASCII) | Sign (EBCDIC) | Sign (EBCDIC) | |
| 0 1 2 3 4 5 6 7 8 9 |
0(30) 1(31) 2(32) 3(33) 4(34) 5(35) 6(36) 7(37) 8(38) 9(39) |
{(7B) A(41) B(42) C(43) D(44) E(45) F(46) G(47) H(48) I(49) |
{(C0) A(C1) B(C2) C(C3) D(C4) E(C5) F(C6) G(C7) H(C8) I(C9) |
p(70) q(71) r(72) s(73) t(74) u(75) v(76) w(77) x(78) y(79) |
}(7D) J(4A) K(4B) L(4C) M(4D) N(4E) O(4F) P(50) Q(51) R(52) |
}(D0) J(D1) K(D2) L(D3) M(D4) N(D5) O(D6) P(D7) Q(D8) R(D9) |
Storage character position requirements for DISPLAY data items are thus equal to the number of "9"s in the PICTURE clause plus one if the sign is specified as SEPARATE. The SYNCHRONIZED clause has no effect on DISPLAY format data declarations.
This format holds numeric data items in computer storage in pure binary two's complement representation. In this format, number values are held in radix of 2 where each computer bit in the representation starting from the right (least-significant) end represents the presence or absence of an increasingly significant power of 2 in that value. Negative numbers are represented by complementing (inverting all the bit values of) their positive counterpart, and then adding one to the whole. Storage requirements depend on the number of "9"s in the PICTURE clause, and whether the numeric data item is signed or unsigned (see the sections The PICTURE Clause, The COMPUTATIONAL Clause, and The SIGN Clause in the chapter Data Division - Data Description); also your COBOL system will assign storage for COMPUTATIONAL items in one of two modes; byte-storage and word-storage. Byte-storage is the default storage-assignment mode for this COBOL implementation.
Computer Memory Natural Boundaries: The fundamental natural boundaries of a modern computer's memory are usually based on an eight-bit character, known as a byte. Within this fundamental framework, machines fall into two broad categories; those with no other natural boundaries, called here byte-storage computers, and those with other natural boundaries based upon multiples of the fundamental boundary of the byte, called here word-storage computers.
In byte-storage mode, COBOL assigns numeric storage so that each numeric item occupies the minimum number of bytes (see the section Selection Of Character Representation And Radix in this chapter); the SYNCHRONIZED clause has no meaning in the context and hence has no effect.
Within word-storage computers, natural boundaries can occur at 2-byte, 4-byte and/or 8-byte boundaries. The COBOL language can provide such data item storage-assignment and synchronization when the COMPUTATIONAL clause and possibly the SYNCHRONIZED clause are used. This word-storage assignment of COMPUTATIONAL format data is controlled by the Compiler directive IBMCOMP.
Table 2-5 : COMP(UTATIONAL) Format Data Item Character-Position (Byte) Storage Assignment
| Number of Digits (9s) in PICTURE Representation | Character-Positions (Bytes) of Storage-Assigned | ||
|---|---|---|---|
| Signed | Unsigned | Byte-Storage Mode | Word-Storage Mode |
| 1-2 3-4 5-6 7-9 10-11 12-14 15-16 17-18 19-21 22-23 24-26 27-28 29-31 32-33 34-35 36-38 |
1-2 3-4 5-7 8-9 10-12 13-14 15-16 17-19 20-21 22-24 25-26 27-28 29-31 23-33 34-36 37-38 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
2 2 4 4 8 8 8 8 16 16 16 16 16 16 16 16 |
Synchronization: If a data item description contains the SYNCHRONIZED clause, and word-storage mode is enabled, the position of that item within the computer storage is aligned so that the right-hand (least-significant) end is on a natural boundary of the computer's storage. Extra character positions (bytes) of computer storage are reserved adjacent to synchronized items to achieve this alignment; these bytes, known as padding bytes or implicit FILLER bytes, are normally inaccessible to the computer program except as part of a group item.
Each elementary data item that is described as SYNCHRONIZED is aligned to the natural storage boundary that corresponds to its data item storage assignment (according to Table 2-5 above). Thus, in word-storage mode, a numeric data item with a PICTURE description of S9(5) would be assigned 4 bytes of storage (being 1 padding byte and 3 data bytes). If SYNCHRONIZED was specified, it would be aligned to the next nearest 4-byte boundary (that is, with the total (4-byte) storage assignment aligned such that the number of bytes from the beginning of the record containing that item to the left-hand (most-significant) end of that item was a multiple of four). If the previous item does not end on a 4-byte boundary, implicit FILLER assignments are necessary to achieve this.
Other such implicit FILLER bytes can be generated by the use of SYNCHRONIZED items in non-elementary data descriptions containing an OCCURS clause (see the section The OCCURS Clause in the chapter Data Division - Data Description). This is because further bytes may need to be reserved for each group item occurrence in order that the second or subsequent occurrences have the same alignment to the natural boundaries of the computer storage as did the first occurrence.
Implicit Synchronization: With word-storage mode enabled, all record-level data descriptions are automatically synchronized to a full 8-byte boundary.
Where automatic alignment is enabled, it is
sensitive to the
ALIGN
directive.
Example of Implicit FILLER Assignments: The following COBOL data description will produce the computer storage allocation shown in Figure 2-3. An explanation of the symbols used is given below the figure.
01 UNSYNCHRONIZED-RECORD.
02 UNSYNCHRONIZED-DATA-1 PIC 9(3) DISPLAY.
02 UNSYNCHRONIZED-DATA-2 PIC X(2).
01 COMPOUND-REPEATED-RECORD.
02 ELEMENTARY-ITEM-1 PIC X(2).
02 GROUP-ITEM OCCURS 3 TIMES.
03 ELEMENTARY-ITEM-2 PIC X.
03 ELEMENTARY-ITEM-3 PIC S9(2) COMP SYNC.
03 ELEMENTARY-ITEM-4 PIC S9(4)V9(2) COMP SYNC.
03 ELEMENTARY-ITEM-5 PIC X(5).

Figure 2-3: Sample Computer Storage Allocation
where:
Truncation: In data items of USAGE COMP, data is held in binary format as described in the previous sections. The storage allocated for an item can have space for larger numbers than specified by the PICTURE clause. For example, an item described as PIC 99 COMP is normally assigned one byte, which can hold numbers up to 255.
To conform with the rules of ANSI COBOL, numbers behave as decimal numbers, regardless of their format. If, in an arithmetic statement, the result is bigger than the PICTURE clause of a receiving item allows, a size error occurs, and if the ON SIZE ERROR phrase is specified the result is not stored in the receiving item. In a non-arithmetic statement, if this situation occurs, the decimal value is truncated on the left, to the number of digits specified in the PICTURE clause.
However, data in USAGE COMP items can be forced to
behave as binary data, that is, truncation occurs only if it is necessary
in order for the data to fit the space allocated. The behavior of USAGE
COMP items is controlled by the setting of the COBOL Compiler
directive
TRUNC. This directive selects whether the decimal value is
truncated to the picture size, or the binary value is truncated to the
space available. It distinguishes between results of arithmetic
statements, and data being moved by non-arithmetic statements.
Regardless of the setting of any directive,
an arithmetic statement gives the size error condition if the result has more decimal digits than specified in the PICTURE clause of a receiving item.
Example of Truncation: The
TRUNC Compiler
directive can change the results of some operations, as
demonstrated in the following examples in which item A is described as PIC
99 COMP.
| Operation | Result | ||
|---|---|---|---|
| TRUNC | NOTRUNC | TRUNC"ANSI" | |
| MOVE 163 TO A | 63 | 163 | 63 |
| MOVE 263 TO A | 63 | 7 | 63 |
| MOVE 13 TO A, ADD 150 TO A |
63 | 163 | undefined results |
| MOVE 13 TO A, ADD 250 TO A |
63 | 7 | undefined results |
Notes:
These formats are used for internal floating-point data items. Such data items can be used in all syntax where a numeric data item can be used and where the syntax is a part of the ANSI'74, ANSI'85, ISO2000, OSVS, or VSC2 COBOL language definition. Such data items cannot be used where integer data items are required unless explicitly allowed by the rules for a specific COBOL verb. An internal floating-point data item cannot be used in other syntax unless a specific rule allows it.
The internal storage format can differ from operating system to operating system. In all storage formats, four pieces of information are encoded:
USAGE FLOAT-SHORT is equivalent to USAGE COMPUTATIONAL-1. USAGE FLOAT-LONG is equivalent to USAGE COMPUTATIONAL-2.
Items that are USAGE COMPUTATIONAL-1 (COMP-1) are usually referred to as single precision floating-point items while items that are USAGE COMPUTATIONAL-2 (COMP-2) are usually referred to as double precision floating-point items. Depending on the operating system or mathematical support libraries available to this COBOL system, different constraints can exist for single and double precision floating-point items. There can be constraints on the maximum exponent sizes, on the maximum mantissa sizes, or both. See your operating system or mathematical library floating-point support documentation for additional information.
COMPUTATIONAL-1 and COMPUTATIONAL-2 are equivalent to Single Format and Double Format, respectively, for operating systems that conform to ANSI/IEEE Std 754-1985, IEEE Standard for Binary Floating-Point Arithmetic.
It is important to understand that internal floating-point representation is not a continuous numeric spectrum. Internal floating-point representations are not standard from operating system to operating system. For example, in one representation of internal floating-point values, the following shows internal to decimal equivalence:
| Internal (Hexadecimal) Storage |
Decimal Value (Scientific Notation) |
|---|---|
| x"AD17E148" | -0.12345673E-23 |
| x"AD17E149" | -0.12345810E-23 |
Therefore, any application which tested for or expected an internal floating-point item with an exact decimal value of -0.12345678E-23, would never find it, while in some other system of internal floating-point storage, that value might be found while the values listed above would never exist. Therefore, any application which tests for exact equivalence between internal floating-point items and other numeric values (including external floating-point items and floating-point literals) cannot be portable and may result in different logic flow even when using the same input data.
For internal floating-point items, the size of the item in storage is determined by its USAGE clause. USAGE COMPUTATIONAL-1 reserves 4 bytes of storage for the item; USAGE COMPUTATIONAL-2 reserves 8 bytes of storage.
When the IBMCOMP Compiler directive is on, padding
bytes can be generated before an internal floating-point item with a SYNC
clause; these bytes are not part of the item, and are never affected by
data stored in the item.
Within the COBOL system, COMP-1 items are accurate
to 7 decimal digits and COMP-2 items to 16 decimal digits. However, for
mainframe compatibility the DISPLAY statement will show 8 decimal places
for COMP-1 and 18 for COMP-2. Any operations using floating-point items
should take the limits of accuracy into account, and should disregard
decimal places beyond the limits of accuracy.
This format, commonly called binary-coded-decimal format, represents numeric data items in radix 10, but with each digit of the value held in only one half of one computer character, as described in Table 2-6 below. The sign is held in a separate trailing digit (half-character) position; that is, at the right-hand or least significant end of the item.
Any unused half bytes will be set to zero.
Table 2-6: COMPUTATIONAL-3 Digit Representation
| Digit Value | Digit Representation in Hexadecimal | |
|---|---|---|
| Left Half-Character (odd digit) | Right Half-Character (even digit) | |
| 0 | x"00" | x"00" |
| 1 | x"10" | x"01" |
| 2 | x"20" | x"02" |
| 3 | x"30" | x"03" |
| 4 | x"40" | x"04" |
| 5 | x"50" | x"05" |
| 6 | x"60" | x"06" |
| 7 | x"70" | x"07" |
| 8 | x"80" | x"08" |
| 9 | x"90" | x"09" |
Note: Count even and odd starting from the right.
Table 2-7 shows the sign digit used for COMPUTATIONAL-3; storage requirements for this format depend only on the number of "9s" in the PICTURE clause of the data item as shown in Table 2-8.
Table 2-7: COMPUTATIONAL-3 Sign Digit Representation
| Sign Convention in the PICTURE Clause | Sign of Data Item Value | Sign Half-character, in Hexadecimal |
|---|---|---|
| Unsigned | n/a | x"0F" |
| Signed | + | x"0C" |
| Signed | – | x"0D" |
Table 2-8: Numeric Data Storage for the COMP(UTATIONAL)-3
or PACKED-DECIMAL
PICTURE Clause.
| Bytes Required | Number of Digits (Signed or Unsigned) |
|---|---|
| 1 | 1 |
| 2 | 2-3 |
| 3 | 4-5 |
| 4 | 6-7 |
| 5 | 8-9 |
| 6 | 10-11 |
| 7 | 12-13 |
| 8 | 14-15 |
| 9 | 16-17 |
| 10 | 18-19 |
| 11 | 20-21 |
| 12 | 22-23 |
| 13 | 24-25 |
| 14 | 26-27 |
| 15 | 28-29 |
| 16 | 30-31 |
| 17 | 32-33 |
| 18 | 34-35 |
| 19 | 36-37 |
| 20 | 38 |

where F represents the non-printing plus sign.

where C represents the plus sign.

where D represents the minus sign.
The SYNCHRONIZED clause (with or without the LEFT or RIGHT phrase) has no effect on COMPUTATIONAL-3 data declarations.
These formats are as for COMPUTATIONAL format except for the differences given below. See the section COMPUTATIONAL, BINARY, Or COMPUTATIONAL-4 Format earlier in this chapter.
They both differ in the following ways from the COMPUTATIONAL format:
The storage of COMPUTATIONAL-5 items is operating system specific. In some operating systems COMPUTATIONAL-5 items are stored in the same format as COMPUTATIONAL-X items and in others they are stored with the low-order bytes stored at the lowest addresses and successively higher-order bytes stored at successively higher addresses. For example, under operating systems which store numeric items in reverse order, a PIC X(5) COMPUTATIONAL-5 item with a numeric internal value of:
h "12 34 56 78 9A"
would be stored as:
9A 78 56 34 12
while a COMPUTATIONAL-X item (or a COMPUTATIONAL-5 item on an operating system without reverse numeric storage) would be stored as:
12 34 56 78 9A
The result of a statement attempting to store a negative value in an unsigned COMPUTATIONAL-5 item is sensitive to the COMP-5 Compiler directive.
The POINTER format holds a value that represents the memory address of an available data item. If the data item becomes unavailable (for example, because it is in a program that has been canceled) then the POINTER format is considered to hold a value that is incompatible with the format.
The default amount of storage allocated for the POINTER format may vary depending on the operating environment but will be at least four bytes. The method of representation of the memory address varies between environments and will in general be consistent with the representation used in non-COBOL languages.
When the IBMCOMP system directive is on, padding bytes can be generated before a pointer data item with a SYNC clause; these bytes are not part of the data item and are never affected by data stored in the item.
The PROCEDURE-POINTER format holds a value that represents the memory address of an available procedure. If the procedure becomes unavailable (for example, because it is in a program that has been canceled) then the PROCEDURE-POINTER format is considered to hold a value that is incompatible with the format.
The default amount of storage allocated for the PROCEDURE-POINTER format may vary depending on the operating environment but will be at least four bytes. If the COBOL370 directive is specified, then eight bytes of storage are allocated. The method of representation of the memory address varies between environments and will in general be consistent with the representation used in non-COBOL languages.
When the IBMCOMP system directive is on, padding bytes can be generated before a procedure-pointer data item with a SYNC clause; these bytes are not part of the data item and are never affected by data stored in the item.
Every user-specified name that defines an element in a COBOL source element.
and is referenced in that source element
must be unique, either because no other name has the identical spelling and hyphenation, or because the name exists within a hierarchy of names such that references to the name can be made unique by mentioning one or more of the higher levels of the hierarchy. The higher levels are called qualifiers and the process that specifies uniqueness is called qualification. Enough qualification must be mentioned to make the name unique; however, it may not be necessary to mention all levels of the hierarchy.
In the Data Division, all data-names used for qualification must be associated with a level indicator or a level-number. Therefore, two identical data-names must not appear as entries subordinate to a group item unless they are capable of being made unique through qualification
or unless they are never referenced
. In the Procedure Division, two identical paragraph-names must not appear in the same section.
In the hierarchy of qualification, names associated with a level indicator are the most significant, followed by those names associated with level-number 01, followed by names associated with level-number 02 through 49. A section-name is the highest (and the only) qualifier available for a paragraph-name. Thus, the most significant name in the hierarchy must be unique and cannot be qualified. Subscripted or indexed data-names and conditional variables, as well as procedure-names and data-names, can be made unique by qualification. The name of a conditional variable can be used as a qualifier for any of its condition-names. Regardless of the available qualification, no name can be both a data-name and procedure-name.
Qualification is performed by following a data-name, a condition-name, a paragraph-name, or a text-name by one or more phrases composed of a qualifier preceded by IN or OF, which are logically equivalent.
When the resource named is a function, the function
definition may require the user to specify in the reference to the
function a value or set of values for one or more parameters which
determine the value of the function for that particular reference. This is
accomplished through the specification of arguments as described in the
section Function-Identifier later in this chapter.
The general formats for qualification are:
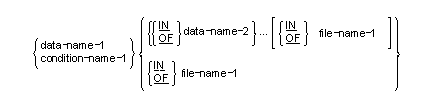

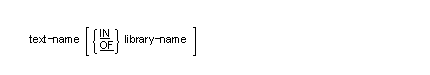

The rules for qualification are as follows:
if it is explicitly referenced within the source
unit.
Neither a paragraph-name nor a section-name need
be unique, or capable of being made unique, unless explicitly
referenced.
Qualified data-names can have up to five qualifiers.
Up to fifty qualifiers are permitted.
This restriction is not enforced.
Subscripts can be used only when reference is made to an individual element within a list or table of like elements that have not been assigned individual data-names (see the section The OCCURS Clause in the chapter Data Division - Data Description).
The subscript can be represented either by a numeric literal that is an integer, by a data-name, or by a data-name followed by the operator "+" or "–" , followed by an unsigned integer numeric literal. The data-name must be a numeric elementary item that represents an integer, and the whole subscript must be delimited by the balanced pair of separators, left-parenthesis and right-parenthesis.
The subscript data-name can be signed and, if signed, must be positive. The lowest possible subscript value is 1. This value points to the first element of the table. The next sequential elements of the table are pointed to by subscripts whose values are 2, 3, ... . The highest permissible subscript value, in any particular case, is the maximum number of occurrences of the item as specified in the OCCURS clause.
The subscript, or set of subscripts, that identifies the table element is delimited by the balanced pair of separators, left parenthesis and right parenthesis following the table element data-name. The table element data-name appended with a subscript is called a subscripted data-name or an identifier. When more than one subscript is required, they are written in the order of successively less inclusive dimensions of the data organization. Up to 3 subscripts are permitted.
Up to 7 subscripts are permitted.
Up to 16 subscripts are permitted.
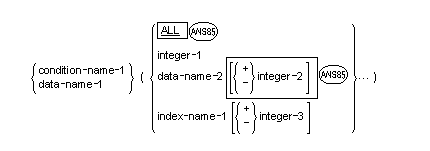
The subscript
ALL can be used only when the subscripted identifier is used as
a function argument and cannot be used when condition-name-1 is
specified. (See the section Arguments in the chapter Procedure
Division - Intrinsic Functions.)
The mixing of subscripts and indices in the same
identifier is illegal.
The mixing of subscripts and indices in the same
identifier is legal.
If the NOBOUND Compiler directive is specified,
these General Rules are not applicable at run time.
If the subscript is a floating-point data item,
the value will be rounded to the nearest integer, otherwise any
fractional part will be truncated.
integer-2 or
integer-3 is specified, the value of the subscript is determined by incrementing by the value of
integer-2 or
integer-3 (when the operator "+" is used) or by decrementing by the value of
integer-2 or
integer-3 (when the operator "-" is used),
either
the occurrence number represented by the value of the index referenced by index-name-1
or the value of the data item referenced by
data-name-2.
References can be made to individual elements within a table of like elements by specifying indexing for that reference. An index is assigned to that level of the table by using the INDEXED BY phrase in the definition of a table. A name given in the INDEXED BY phrase is known as an index-name and is used to refer to the assigned index. The value of an index corresponds to the occurrence number of an element in the associated table or any other table. An index-name must be initialized before it is used as a table reference. An index-name can be given an initial value by a SET statement.
Unlike a subscript, which is simply a numeric data item or literal, an index is a special type of item and holds a representation of an occurrence number. The form of this representation can vary; the contents of an index cannot be regarded as a numeric value.
Direct indexing is specified by using an index-name in the form of a subscript. Relative indexing is specified when the index-name is followed by the operator "+" or "–", followed by an unsigned integer numeric literal, all delimited by the balanced pair of separators left parenthesis and right parenthesis following the table element data-name. The occurrence number resulting from relative indexing is determined by incrementing (where the operator "+" is used) or decrementing (where the operator "–" is used), by the value of the literal, the occurrence number represented by the value of the index. When more than one index-name is required, they are written in the order of successively less inclusive dimensions of the data organization.
A table can be indexed only by the index described in its INDEXED BY phrase.
An index described for some other table can be
used instead provided the two tables have elements of the same size.
At the time of execution of a statement which refers to an indexed table element, the value contained in the index used to index it must neither correspond to a value less than one nor to a value greater than the highest permissible occurrence number of an element of the associated table. This restriction also applies to the value resulting from relative indexing.
If the NOBOUND Compiler directive is specified, this
rule is not applicable at run time.
Up to 3 index-names can be used with a data-name.
Up to 7 index-names can be used with a data-name.
Up to 16 index-names can be used with a data-name.
The general format for indexing is included in the general format for subscripting earlier in this chapter.
A function-identifier references the unique data item that results from the evaluation of a function.
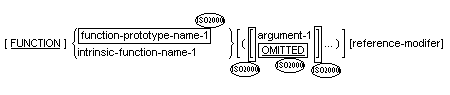
intrinsic-function-name-1 is specified in the
repository paragraph, or
function-prototype-name-1 is specified.
Function-prototype-name-1 must be a function
prototype specified in the repository paragraph.
The word OMITTED must not be specified if
intrinsic-function-name-1 is specified.
and for user-defined functions in the section Conformance
for Parameters and Returning Items of the chapter Procedure
Division.
If the word OMITTED is specified, the OPTIONAL
phrase must be specified for the corresponding formal paramtter.
If function-prototype-name-1 is specified and the
formal parameter corresponding to argument-1 is specified with a BY
VALUE phrase, argument-1 must be of class numeric, object or pointer.
If function-prototype-name-1 is specified, the
rules for conformance specified in the section Conformance for
Parameters and Returning Items of the chapter Procedure Division
shall apply.
or national.
Note: For a function that may be referenced either with or without arguments, such as the RANDOM function, careful coding is necessary to ensure correct interpretation. For example, in the following:
FUNCTION MAX (FUNCTION RANDOM (A) B)
'A' is treated as an argument to the RANDOM function. If 'A' is instead meant to be a second argument to the MAX function, different coding is necessary - either:
FUNCTION MAX (FUNCTION RANDOM () A B) or
FUNCTION MAX ( (FUNCTION RANDOM) (A) B) or
FUNCTION MAX (FUNCTION RANDOM A B)
If intrinsic-function-name-1 is specified, the temporary data item is an elementary data item whose description and category are specified by the definition of that intrinsic function in the chapter Procedure Division - Intrinsic Functions.
If function-prototype-name-1 is specified, the
description, class, and category of the temporary data item is that
specified by the description in the linkage section of the item
specified in the RETURNING phrase of the procedure division header of
the function prototype identified by function-prototype-name-1.
for user-defined functions in the sections The
PROCEDURE DIVISION Header and Conformance for Parameters and
Returning Items in the chapter Procedure Division.
If a function is expecting an integer argument,
then if a floating-point argument is provided, the value will be
rounded to the nearest integer, otherwise any fractional part will be
truncated.
If function-prototype-name-1 is specified, the
function to be activated is identified by function-prototype-name-1 in
accordance with the rules specified in the section REPOSITORY
paragraph in the chapter Environment Division, and
function-prototype-name-1 is used to determine the characteristics of
the activated function.
If function-prototype-name-1 is specified, the
manner used for passing each argument is determined as follows:
If function-prototype-name-1 is specified,
the rules are specified in the sections Scope of Names and
Conventions for Function-prototype-names and
Program-prototype-names of this chapter. Additional rules are
given in the section REPOSITORY paragraph of the chapter
Environment Division.
If function-prototype- name-1 is specified
and the function to be activated is a COBOL function, its
execution is described in the section The PROCEDURE DIVISION
Header of the chapter Procedure Division.
If intrinsic-function-name-1 is specified, its execution is described in the chapter Procedure Division - Intrinsic Functions.
If function-prototype-name-1 is specified
and the function to be activated is not a COBOL function, the
execution is defined your COBOL system documentation on
interfacing.
Reference modification defines a unique data item by specifying an identifier, a leftmost position and a length.
identifier-1 ( leftmost-position : [length] )
external floating-point,
numeric edited, alphabetic, or alphanumeric edited, it is operated upon for purposes of reference modification as if it were redefined as an alphanumeric data item of the same size as the data item referenced by identiifer-1.
The results are rounded if the expression
is in floating-point, and truncated if the expression is in
fixed-point.
The results are rounded if the expression
is in floating-point, and truncated if the expression is in
fixed-point.
and external floating-point
are considered class and category alphanumeric, and
the category national-edited is considered
class and category national.If the
OSVS Compiler
directive is set,
reference modification cannot be used in conditional expressions
(see the chapter Procedure Divisionfor a description of
conditional expressions). An identifier is a sequence of character-strings and separators used to reference data uniquely.
When a data item other than a
function or
object-property
is being referenced,
identifier is a term used to reflect that a data-name, if not unique in a source element, must be followed by a syntactically correct combination of qualifiers, subscripts,
necessary for uniqueness of reference.

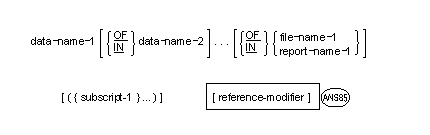
property-name-1 OF identifier-1
Subscript-1 represents either subscripting (see the section Subscripting earlier in this section) or indexing (see the section Indexing earlier in this section).
Object properties provide a special syntax to get information out of and pass information back into an object. The mechanisms for accessing object properties are get property methods and set property methods. A get property method is a method explicitly defined with the GET PROPERTY phrase or a method implicitly generated for a data item described with the PROPERTY clause; a set property method is a method explicitly defined with the SET PROPERTY phrase or a method implicitly generated for a data items described with the PROPERTY clause.
Each condition-name must be unique, or be made unique through qualification and/or indexing, or subscripting. If qualification is used to make a condition-name unique, the associated conditional variable can be used as the first qualifier. The hierarchy of names associated with the conditional variable or the conditional variable itself must be used to make the condition-name unique.
If references to a conditional variable require indexing or subscripting, references to any of its condition-names require the same combination of indexing or subscripting.
The format and restrictions on the combined use of qualification, subscripting, and indexing of condition-names are exactly those of "identifier" except that data-name-1 is replaced by condition-name-1.
In the general formats, "condition-name" refers to a condition-name qualified, indexed or subscripted, as necessary.
There are four types of explicit and implicit spe cifications that occur in COBOL source elements:
Explicit and implicit scope terminators. A COBOL source element can reference data items either explicitly or implicitly in P rocedure Division statements. An explicit reference occurs when the name of the referenced item is written in a Procedure Division statement or when the name of the referenced item is copied into the Procedure Division by the processing of a COPY statement
, a REPLACE statement
, a -INC statement, or ++INCLUDE statement
. An implicit reference occurs when the item is referenced by a Procedure Division statement without the name of the referenced item being written in the source statement.
An implicit reference also occurs during the execution of a PERFORM statement, when the index or data item referenced by the index-name or identifier specified in the VARYING, AFTER or UNTIL phrase is initialized, modified, or evaluated by the control mechanism associated with that PERFORM statement. Such an implicit reference occurs if and only if the data item contributes to the execution of the statement.
The flow of control mechanism transfers control from statement to statement in the sequence in which they were written unless an explicit transfer of control overrides this sequence or there is no next executable statement to which control may be passed. The transfer of control from statement to statement occurs without the writing of an explicit procedure division statement, and, therefore, is an implicit transfer of control.
COBOL provides both an explicit and an implicit means of altering the implicit control transfer mechanism.
In addition to the implicit transfer of control between consecutive statements, implicit transfer of control occurs when the normal flow is altered without the execution of a procedure branching statement. COBOL provides the following types of implicit control flow alterations which override the statement-to-statement transfers of control:
Note: Another implicit transfer of control occurs after execution of the declarative section, as described in item 1. above.
In any file operation (including OPEN and CLOSE),
if a file does not have a FILE STATUS data item declared for it and the
file is not explicitly covered by a USE statement, then it is covered by
an implicit USE statement. The implied USE procedure is equivalent to:
USE AFTER ERROR PROCEDURE ON file-name. IF status-key-1 >= 3 DISPLAY error-message UPON CONSOLE STOP RUN.
See your Error Messages for a definition of error messages.
An explicit transfer of control consists of an alteration of the implicit control transfer mechanism by the execution of a procedure branching, ending or conditional statement. An explicit transfer of control between statements can be caused only by the execution of a procedure branching or conditional statement. An explicit transfer of control between sentences can be caused only by the execution of the NEXT SENTENCE phrase of an IF or SEARCH statement.
The execution of the procedure branching statement ALTER does not in itself constitute an explicit transfer of control, but affects the explicit transfer of control that occurs when the associated GO TO statement is executed. The procedure branching statement EXIT PROGRAM causes an explicit transfer of control only when the statement is executed in a called program.
The term "next executable sentence" is used to refer to the next COBOL sentence to which control is either implicitly transferred according to the rules above, or explicitly transferred as a result of execution of the NEXT SENTENCE phrase. The next executable sentence is the first sentence following the separator period that terminates the current sentence. There is no next executable sentence when there is no next executable statement as described below.
The term "next executable statement" is used to refer to the next COBOL statement to which control is transferred according to the rules above and the rules associated with each language element in the Procedure Division.
There is no next executable statement following:
, GOBACK statement
, EXIT METHOD
, EXIT FUNCTION
or EXIT PROGRAM statement that transfers control outside the COBOL source element
Attributes can be implicitly or explicitly specified. Any attribute which has been explicitly specified is called an explicit attribute. If an attribute has not been specified explicitly, then the attribute takes on the default specification. Such an attribute is known as an implicit attribute.
For example, the usage of a data item need not be specified, in which case a data item's usage is DISPLAY
 , unless the PICTURE character-string contains a "G"
or an "N", in which case a data item's usage is DISPLAY-1.
, unless the PICTURE character-string contains a "G"
or an "N", in which case a data item's usage is DISPLAY-1.
Scope terminators delimit the scope of certain Procedure Division statements (delimited scope statements), and are of two types: explicit and implicit.
The explicit scope terminators are listed below:
END-ADD
END-PERFORM
END-ACCEPT
END-CALL
END-CHAIN
END-COMPUTE
END-DELETE
END-DISPLAY
END-DIVIDE
END-EVALUATE
END-IF
END-MULTIPLY
END-READ
END-RETURN
END-REWRITE
END-SEARCH
END-START
END-STRING
END-SUBTRACT
END-UNSTRING
END-WRITE
Note: In some cases the delimited scope statement with which an explicit scope delimiter is paired, is determined differently for different COBOL language specifications.
Implicit scope termination occurs:
Copyright © 2000 MERANT International Limited. All rights reserved.
This document and the proprietary marks and names
used herein are protected by international law.
| Introduction to the COBOL Language | Concepts of a Compilation Group | |