

| Concepts of a COBOL Program | Identification Division | |
This chapter describes the base COBOL language definition. This language definition provides a basic capability for the internal processing of data in the basic structure of the four divisions of a program.
Material is thus presented in four segments; the Identification Division, Environment Division, Data Division and Procedure Division, shown by the thumb tabs. Within these segments, material is presented according to COBOL sections, shown by the headers. Clauses, including intrinsic functions and COBOL verbs, are listed in alphabetical order, for ease of use.
Additional language features such as DBCS, Report Writer, Communication and SQL are supported, and are described in your companion manual, Language Reference - Additional Topics.
A COBOL source program is a syntactically correct set of COBOL statements.
 A COBOL source program may
contain other COBOL source programs and these contained programs may
reference some of the resources of the programs within which they are
contained.
A COBOL source program may
contain other COBOL source programs and these contained programs may
reference some of the resources of the programs within which they are
contained.
With the exception of COPY
and REPLACE statements and the
end
program header
, the statements, entries, paragraphs, and sections of a COBOL source program are grouped into four divisions which are sequenced in the following order:
The end of a COBOL source program is indicated by
either the end program header,
if specified, or by
the absence of further source program lines.
The following gives the general format and order of presentation of the entries and statements which constitute a COBOL source program. The generic terms identification-division, environment-division, data-division, procedure-division
and end-program-header
represent a COBOL identification division, a COBOL environment division, a COBOL data division, a COBOL procedure division
and a COBOL end program header
respectively.
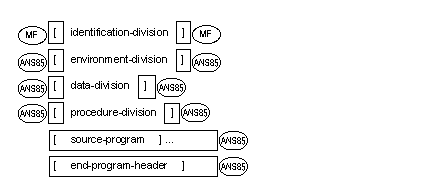

End-program-header must be
present if:

An Identification Division
header which indicates the start of another source program.
The END PROGRAM header.
The end program header indicates the end of the named COBOL source program.
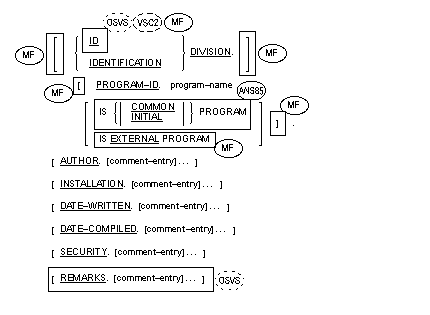
 The program-name can be a
nonnumeric literal. The content of the literal must follow the rules for
formation of program-names.
The program-name can be a
nonnumeric literal. The content of the literal must follow the rules for
formation of program-names.
A COBOL source program can contain other COBOL source programs, and these contained programs can reference some of the resources of the programs in which they are contained.
When a program, program B, is contained in another program, program A, it can be directly or indirectly contained. Program B is directly contained in program A if program A doesn't contain a program that also contains program B. Program B is indirectly contained in program A if program A contains a program that also contains program B.
A program is in the initial state:
OR CHAIN
statement referencing a program that possesses the initial attribute,
and that directly or indirectly contains the
program.
All such data items are filled
with the value found in the
DEFAULTBYTE Compiler
directive.
A CALL prototype is a program declaration or skeleton program which serves to define the characteristics of a called subprogram. These characteristics include the number of parameters required, the type of these parameters and the calling convention. If a program contains a CALL statement referring to a subprogram for which a prototype exists, the CALL statement is checked against the prototype. If there is an explicit mismatch, an error is given. If the CALL statement leaves some characteristics (such as the call convention) undefined, this is derived from the prototype.
The CALL prototype is defined as a complete program in which the EXTERNAL clause is specified in the PROGRAM-ID paragraph. The program structure should consist only of an IDENTIFICATION DIVISION with a PROGRAM-ID paragraph, a DATA DIVISION with a LINKAGE SECTION, a PROCEDURE DIVISION header, and optional ENTRY statements. These CALL prototypes are placed before the program definitions in a similar way to multi-program source files.
Note that you must include a copy of the CALL prototype for every subprogram to which you want your CALL statements checked before the IDENTIFICATION DIVISION header of your program containing the CALL statements. Similarly, you must copy in or include the call prototype for a subprogram in every call program for which you want the CALL statements validated.
A file connector is a storage area which contains information about a file and is used as the linkage between a file-name and a physical file and between a file-name and its associated record area.
A data-name names a data item. A file-name names a file connector. These names are classified as either global or local.
A global name can be used to refer to the object with which it is associated either from within the program in which the global name is declared, or from within any other program which is contained in the program which declares the global name.
A local name, however, can be used only to refer to the object with which it is associated from within the program in which the local name is declared. Some names are always global; other names are always local; some other names are either local or global depending upon specifications in the program in which the names are declared.
A record-name is global if the GLOBAL clause is specified in the record description entry by which the record-name is declared or, in the case of record description entries in the File Section, if the GLOBAL clause is specified in the file description entry for the file-name associated with the record description entry.
A data-name is global if the GLOBAL clause is specified either in the data description entry by which the data-name is declared or in another entry to which that data description entry is subordinate.
A condition-name declared in a data description entry is global if that entry is subordinate to another entry in which the GLOBAL clause is specified. However, specific rules sometimes prohibit specification of the GLOBAL clause for certain data description, file description, or record description entries.
A file-name is global if the GLOBAL clause is specified in the file description entry for that file-name.
If a data-name, a file-name, or a condition-name declared in a data description entry is not global, the name is local.
Global names are transitive across programs contained within other programs.
Accessible data items usually require that certain representations of data be stored. File connectors usually require that certain information concerning files be stored. The storage associated with a data item or a file connector can be external or internal to the program in which the object is declared.
A data item or file connector is external if the storage associated with that object is associated with the run unit rather than with any particular program within the run unit. An external object can be referenced by any program in the run unit which describes the object. References to an external object from different programs using separate descriptions of the objects are always to the same object. In a run unit, there is only one representation of an external object.
An object is internal if the storage associated with that object is associated only with the program which describes the object.
External and internal objects can have either global or local names.
A data record described in the Working-Storage Section is given the external attribute by the presence of the EXTERNAL clause in its data description entry. Any data item described by a data description entry subordinate to an entry describing an external record also attains the external attribute. If a record or data item does not have the external attribute, it is part of the inte rnal data of the program in which it is described.
A file connector is given the external attribute by the presence of the EXTERNAL clause in the associated file description entry. If the file connector does not have the external attribute, it is internal to the program in which the associated file-name is described.
The data record described subordinate to a file description entry which does not contain the EXTERNAL clause or a sort-merge file description entry, and any data items described subordinate to the data description entries for such records, are always internal to the program describing the file-name. If the EXTERNAL clause is included in the file description entry, the data records and the data items attain the external attribute.
Data records, subordinate data items, and various associated control information described in the Linkage, Communication, and Report Sections of a program are always considered to be internal to the program describing that data. Special considerations apply to data described in the Linkage Section whereby an association is made between the data records described and other data items accessible to other programs.
Record sequential I/O allows the programmer to access records of a file in an established sequence. The sequence is established as a result of writing the records to the file.
Sequential files are organized such that each record in the file except the first has a unique predecessor record, and each record except the last has a unique successor record. These predecessor-successor relationships are established by the order of WRITE statements when the file is created. Once established, the predecessor-successor relationships do not change except in the case where records are added to the end of the file.
Line sequential I/O allows the programmer to access records of a text file in an established sequence. Line sequential files are identical in format to those files produced by your operating system editor. The records are stored with trailing spaces removed.
If the words sequential file or sequential organization are used in this chapter without specifying LINE or RECORD, then the sentence applies to both forms. The default behavior for sequential files is sensitive to the SEQUENTIAL Compiler directive.
The only access available for sequential files is sequential access mode; the sequence in which records are accessed is the order in which the records were originally written.
Relative I/O allows the programmer to access records within a mass storage file in either a random or sequential manner. Each record in a relative file is identified by an integer value greater than zero which specifies the record's ordinal position in the file.
Rela tive file organization is permitted only on disk devices. A relative file consists of records which are identified by relative record numbers. The file can be thought of as being composed of a serial string of areas, each capable of holding a logical record. Each of these areas has a relative record number. Records are stored and retrieved via this number. For example, ten denotes the tenth record area.
In sequential access mode, records are accessed in the ascending order of the relative record numbers of those records which currently exist within the file.
In random access mode, the programmer controls the sequence in which records are accessed. The desired record is accessed by placing its relative record number in a relative key data item.
In dynamic access mode, the programmer can change at will between sequential access and random access, using the appropriate forms of input-output statements.
Indexed input-output allows the programmer to access records within a mass storage file in either a random or sequential manner. Each record in an indexed file is identified by the value of one or more keys within that record.
An indexed file is a mass storage file in which data records can be accessed by the value of a key. A record description can include one or more key data items, each of which is associated with an index. Each index provides a logical path to the data records, according to the contents of a data item within each record which is the record key for that index.
The data item named in the RECORD KEY clause of the file control entry for a file is the prime record key for that file. For purposes of inserting, updating and deleting records in a file, each record is identified solely by the value of its prime record key. This value should, therefore, be unique and must not be changed when updating the record.
The data item named in the ALTERNATE RECORD KEY clause of the file control entry for a file is an alternative record key for that file. The value of an alternative record key can be non-unique if the DUPLICATES phrase is specified. These keys provide alternative access paths for retrieval of records from the file.
Your COBOL system provides an
extension which allows the key field to be a split key. A sp
lit key is a key comprising two or more data items, which may or may not
be contiguous, in the record description.
In sequential access mode, records are accessed in the ascending order of the record key values. Records within a set of records which have duplicate record key values are retrieved in the order in which the records were written into the set.
In random access mode, the programmer controls the sequence in which records are accessed. The desired record is accessed by placing the value of its record key in the record key data item.
In dynamic access mode, the programmer can change at will between sequential access and random access, using appropriate forms of input-output statements.
Copyright © 1998 Micro Focus Limited. All rights reserved.
This document and the proprietary marks and names
used herein are protected by international law.
| Concepts of a COBOL Program | Identification Division | |