
| Advanced Language Features | |
The information in this chapter is designed to help you produce programs that run as efficiently as possible. It includes information on the following:
The information in this chapter applies to programs compiled to native code not intermediate code unless otherwise stated.
The section Performance Programming is generic to the DOS, Windows, Windows NT, OS/2, and UNIX environments. The remaining sections are specific to DOS, Windows, Windows NT and OS/2.
This section gives some guidelines which, if followed, enable your COBOL system to optimize fully the native code produced for your programs. This results in smaller and faster applications.
This COBOL system, or an equivalent, is available from Micro Focus for many environments, including DOS, Windows, OS/2, Windows NT and most variants of UNIX. Programs written on one system can be moved to other systems provided certain portability rules are followed.
The run-time system and native code generators are tailored separately to each environment. However, they are based on one of three technologies, according to the type of addressing that the operating system uses:
This section contains information for making your program efficient with both of these technologies. Where information differs between technologies, this is shown.
Do remember that these are only guidelines; programs that do not conform to these guidelines still run correctly, just less efficiently.
This section identifies items in the Data Division which affect the size and performance of your program, and suggests the most efficient ways of using them.
Using the correct data-type is important to get the greatest efficiency from operations, particularly arithmetic operations. For details of how each data-type is stored refer to your Language Reference.
If the ON SIZE ERROR clause is used, or if the data item is non-integer, the above ordering does not apply. For example, arithmetic on such items uses packed decimal registers inside the run-time system. In this non-optimized mode the order is:
COMP-3
DISPLAY
COMP
COMP-X
COMP-5
However, individual cases might behave differently.
16-bit:
In the 16-bit COBOL system, the fastest and smallest code is produced
for operations on items that contain up to four digits, or two bytes
for binary items. The next fastest code is produced for operations on
items that contain up to nine digits, or up to four bytes for binary
items.
32-bit:
In 32-bit COBOL systems, the fastest and smallest code is produced
for operations on items that contain up to nine digits, or four bytes
for binary items.
Operations on numeric items containing more than nine digits, or more than four bytes for binary items, produces the slowest and largest code.
64-bit:
In 64-bit COBOL systems, the fastest and smallest code is produced
for operations on items that contain up to eighteen digits, or eight
bytes for binary items. However the impact of exceeding this limit is
not as great as on the 16-bit and 32-bit systems.
To ensure all items in a table are correctly aligned, check that the size of an occurrence in the table (the stride of the table) is a multiple of two or four bytes as required. Pad the table as necessary. For example:
01 a occurs 10.
03 b pic x(4) comp-5.
03 c pic x.
03 filler pic x(3).
A three-byte filler has been added to each occurrence in the table to ensure that the numeric data item is always aligned on a four-byte boundary.
The REF Compiler directive can be used to find out how data items are aligned.
16-bit:
The 16-bit COBOL system supports the segmented addressing architecture
used by DOS, Windows and OS/2 V1 on Intel 80x86 chips. Under this
architecture, Data Divisions larger than 64 kilobytes (64K) introduce
efficiency problems. Every time a data item is referenced, additional code
is executed to ensure that the correct data segment is being referenced.
The best way to avoid this is to ensure the size of your Data Division is
less than 64K:
This section identifies items in the Procedure Division which affect the size and performance of your program, and suggests the most efficient ways of using them.
As a general rule, the simpler the operation, the faster it executes and the smaller the compiled code. To get the best performance it is often better to use a number of simple operations rather than one complex operation. The following are general guidelines that result in the fastest and smallest possible code.
To get the best performance from arithmetic statements always use the simplest forms.
The following operations are optimized for COMP-5 and COMP-X data items up to four bytes long.
move a to b
add a to b
subtract a from b
multiply a by b
divide a into b
if a condition b
where:
a
is a numeric literal or data item up to four bytes long
b
is a numeric data item up to four bytes long
On other data items, these simple operations result in faster code than more complex instructions, but the benefits are not so great as with COMP-5 or COMP-X items.
More complex forms of these instructions, involving more than two operands, might not produce code as efficient as the simple form.
move a to c
add b to c
rather than:
add a to b giving c
32-bit and 64-bit:
Statements containing the GIVING phrase are optimized on 32-bit and
64-bit COBOL systems provided the operands are all of the same type.
COMPUTE is defined to evaluate its result in a temporary field of the largest possible significance to hold the result. This temporary field might be of a larger significance than is actually required, causing the operations to be slower. The temporary field is stored in the target field with any necessary truncation. This also applies to IF statements involving expressions. For example:
if a + b < c
It is often better to define a temporary data item of the required size and use that to hold the result of the arithmetic, as follows:
move a to temp
add b to temp
if temp < c
On the 16-bit COBOL system, intermediate code reports run-time
error 163 ("Illegal character in numeric field").
Generated code gives unpredictable results. You can use the
CHECKNUM Compiler directive to make generated code give the same
results as intermediate code.
On 32-bit and 64-bit COBOL systems, intermediate code reports
run-time error 163 ("Illegal character in numeric field").
Generated code gives unpredictable results.
Results are unpredictable.
To avoid these problems, all numeric items should be initialized to numeric values before use.
item (literal:)
item (literal:literal)
item (literal:variable)
item (variable:variable)
item (variable + literal:literal)
item (variable - literal:literal)
item (variable + literal:variable)
item (variable - literal:variable)
Other forms of reference modification are inefficient.
16-bit:
On the 16-bit COBOL system, the optimal size for a subscript is two
bytes.
32-bit and 64-bit:
On 32-bit and 64-bit COBOL systems, the optimal size for a subscript
is four bytes.
01 a pic xx occurs 10.
01 b pic xx occurs 10.
01 c pic xx occurs 10.
01 d pic xx occurs 10.
. . .
move a(i) to b(i)
if c(i) = d(i)
display "pass"
end-if
would result in the subscript i being evaluated only
once, although it is used four times in two statements. The stride of
each of these tables is the same: two.
If you are using USAGE DISPLAY subscripts, the BOUNDOPT directive (also switched on by NOBOUND) can give performance improvements. For example:
. . .
01 array pic x occurs 20.
01 array-index pic 9(5) value 2.
. . .
move "a" to array(array-index).
. . .
If the program is compiled without BOUNDOPT, all five digits of
array-index are used to evaluate the subscript. If
BOUNDOPT is specified, only the last two digits of array-index
are used, as only two digits are needed to access all elements of a 20
element table.
16-bit:
On the 16-bit COBOL system, certain simple EVALUATE statements are
compiled into a GO TO ... DEPENDING ON statement, which is very
efficient.
A number of COBOL System Library Routines (call-by-name) are available to perform bitwise logical operations on data items. These are described in the chapter Advanced Language Features. They perform operations such as bitwise AND, OR and XOR.
The Compiler recognizes calls to these routines and, if possible, optimizes them to produce in-line code rather than calls to the run-time system. In-line code is native code which performs the function directly without making any calls. The alternative is a call to a generic run-time routine which must allow for many cases.
16-bit:
On the 16-bit COBOL system, the calls are optimized if the length
parameter is a literal and no more than eight.
32-bit and 64-bit:
On 32-bit and 64-bit COBOL systems, the calls are optimized if the length
is specified as a literal.
Logical AND and logical OR operations can also be carried out using the VALUE clause. See your Language Reference for details.
Using PERFORM is generally very efficient, and is a very good way of keeping the size of your program down as well as giving it an easy-to-maintain structure. The following rules enable you to use it in the most efficient ways.
Apart from being good coding practice, this saves space. It is often beneficial even on single statements; for example, edited moves, subprogram calls or file I/O
The range of an out-of-line PERFORM statement should not contain the end of another perform range. If it does, the program is said to trickle ; that is execution is allowed to go past the end of a perform range. Applying the rule above ensures that this does not occur.
If your program does not trickle you can compile it with the directive NOTRICKLE which causes the Compiler to produce more efficient code, PERFORM being implemented as a machine code CALL instruction with a corresponding RET at the end of the perform range. If NOTRICKLE is used where two perform ranges overlap, results are unpredictable. Refer to your Object COBOL User Guide for details of the NOTRICKLE directive.
For example, do not use code in the form:
procedure division.
perform a thru c
perform b thru d
stop run.
a.
display "a".
b.
display "b".
c.
display "c".
d.
display "d".
Use the TRICKLECHECK directive when you compile your program to determine if your program trickles. When you execute a program compiled with this directive, a run-time error is produced whenever it attempts to trickle.
32-bit and 64-bit:
On 32-bit and 64-bit COBOL systems, all optimization is done
automatically.
For example, the following produces very inefficient code for the first PERFORM because the end of the range of the second PERFORM lies within the range of the first PERFORM.
perform a thru e
perform b thru d
stop run
a.
. . .
b.
. . .
c.
. . .
d.
. . .
e.
. . .The presence of an ALTER statement in a program prevents optimization of PERFORM statements.
call "literal" using ...
Avoid making many references to linkage items. These include items defined in the Linkage Section, items set to CBL_ALLOC_MEM allocated memory, and items defined as EXTERNAL .
Accessing linkage items is always slower than accessing Working-Storage Section items. If a Linkage Section item is used frequently, it is faster to move it into a Working-Storage Section item when the program is entered and move it back to the Linkage Section if necessary before exiting to the calling program. The Working-Storage Section item should then be accessed throughout the program rather than the item in the Linkage Section.
If a linkage parameter is optional you can detect its presence using a statement of the form:
if address of linkage-item not = null
If you use input and output procedures with a file sort in your program it is important that you write them efficiently as they are executed once for each record you are sorting. Inefficient input and output procedures can make the sort process appear to be very slow.
16-bit:
On the 16-bit COBOL system, the run-time system defaults to a fast
sort algorithm. The size of files that can be sorted under this
method is limited, but is enough for most files. The alternative method
which can handle the sorting of very large files, but is slower, can be
enabled by the run-time switch B2. (See your Object COBOL User
Guide for details on this switch.)
16-bit:
The 16-bit COBOL system supports the segmented addressing architecture
used by DOS, Windows and OS/2 V1.x on Intel 80x86 chips. Under
this architecture, code segments are limited in size to 64K. Do not let
the Compiler decide where to break your program into segments. Instead
segment the program manually, that is, by using the segment number on a
section header, so you can choose where to split it. Avoid inter-segment
PERFORM and GO TO statements.
If appropriate the memory needed can be reduced by manually segmenting a Procedure Division which is smaller than 64K. As the RTS can segment-swap procedural code this is rarely necessary.
See the section Large Programs later in this chapter for more information.
A number of Compiler directives can be used to make the native code for a program better optimized. Some of these directives must be used with care; ensure that the behavior you get with them is acceptable.
In general, always use the following directives when compiling your programs to native code:
16-bit:
On the 16-bit COBOL system:
NOALTER
ALIGN"2"
NOANIM
NOBOUND
NONESTCALL
OPTSIZE
32-bit and 64-bit:
On 32-bit and 64-bit COBOL systems:
NOALTER
ALIGN"4" (32-bit systems)
ALIGN"8" (64-bit systems)
COMP
NOBOUND
NOCHECKDIV
NONESTCALL
NOODOSLIDE
NOQUAL
NOSEG
NOTRUNC
16-bit:
On the 16-bit COBOL system use the following Compiler directives with
care:
NOTRICKLE
DEFAULTCALLS"4"
NOPARAMCOUNTCHECK
Other suggestions (to help prevent inefficient coding):
REMOVE "UNSTRING"
REMOVE "STRING"
REMOVE "GIVING"
REMOVE "ROUNDED"
REMOVE "COMPUTE"
REMOVE "ERROR"
REMOVE "ALTER"
REMOVE "INITIALIZE"
REMOVE "CORRESPONDING"
REMOVE "TALLYING"
REMOVE "THRU"
REMOVE "THROUGH"
By removing these reserved words you prevent the possibility that code using these inefficient constructs will be added to the program.
There are many directives you can use to optimize for speed. In some cases, the defaults for Compiler directives are the ones that provide speed optimization. This section points out directives that need to be changed from their default values to provide for speed optimization.
For efficiency reasons, you should not use ALTER statements in programs. It is recommended that you avoid them altogether, and compile with NOALTER, to prevent the Compiler from having to produce code to look for them.
The BOUND directive does boundary checking on table items.
Your applications can be made faster (and smaller) by compiling with NOBOUND. Otherwise, the Compiler inserts extra code to do boundary checking on all references to table items.
During testing, you should use the BOUND directive until you are satisfied that your program is not referencing data beyond your table limits. For production, NOBOUND gives you the desired efficiency.
The BOUNDOPT directive can be used to optimize your code if the following apply:
When BOUNDOPT is specified, digits in a USAGE DISPLAY subscript above the size of the table are ignored. For example, a PIC 9(3) subscript would be treated as PIC 9(2) for a table with less than 100 entries.
We recommend that you do not use USAGE DISPLAY subscripts.
16-bit:
On the 16-bit COBOL system, CHIP"16" is the default, indicating
segment addressing of 16 bits.
FLAG-CHIP tells you when data items cross these segments (64K
boundaries).
During the development process, you should compile with CHIP"16" and FLAG-CHIP. You are told, on your listing, which data items cross 64K boundaries.
You should then change the Data Division and insert FILLER items before these data items. If you do not do this, the Compiler inserts extra code to handle the situation, resulting in a program that is both larger than it could be and slower at execution time.
Alternately, you could specify the 01SHUFFLE directive which changes the addresses of level-01 items in the Working-Storage Section so that they do not cross 64K segment boundaries. The use of this directive can cause an increase in the size of the data segment of a program. The directive is not valid for nested programs.
The COMP directive prevents code checking for numeric overflow. This produces highly compact and efficient code.
COMP changes the behavior of arithmetic on data items defined as USAGE COMP. It produces more efficient code, but the behavior does not conform to the ANSI standard.
If used with the proper care, COMP can improve the speed of your programs.
16-bit:
On the 16-bit COBOL system the FASTLINK directive prevents code being
produced to check the order of parameters in the Linkage Section against
USING or ENTRY clauses.
FASTLINK only works when compiling to .obj files.
Naturally, FASTLINK only applies to called subprograms that have parameters passed to them via the Linkage Section. FASTLINK can only be of value under the following circumstances:
You should usually test with NOFASTLINK, then switch to FASTLINK at production time.
16-bit:
On the 16-bit COBOL system the LITLINK directive forces an application to
be
statically linked. The size of the resultant executable (.exe)
module is smaller than the sum of all the modules (main module and
subroutines) linked separately. Also, the execution speed increases,
because called modules are already in memory.
However, the entire application is loaded in memory at the same time. If your application is too large for the memory size of the machines it runs on, memory problems result. In these cases, you should run dynamically, using NOLITLINK, and use CALL and CANCEL for subroutine branching.
The NESTCALL directive enables nested programs to appear in your program. If you know you have no nested calls in your program, specifying NONESTCALL enables the Compiler to generate slightly more efficient code.
16-bit:
On the 16-bit COBOL system the OPT directive sets the level of
optimization performed by the second pass of the Compiler. It affects both
the size and speed of the resulting module.
The OPT directive can be set to 0, 1 or 2. The default is 2, which produces the fastest code, being native machine code with additional optimization.
Because some of these optimizations might result in the removal of unnecessary instructions, OPT"2" might produce code that does not correspond directly to the source code. For example, consider the following code sequence:
perform dummy-para 100000 times.
. . .
. . .
dummy-para.
exit.
You might have included code such as this in your program to act as a delay loop. However, OPT"2" recognizes that this code actually does nothing and removes it from the native code. Therefore, if your programs rely on the removed instructions, you should compile with OPT"1", or recode your delay to use an alternative mechanism.
16-bit:
On the 16-bit COBOL system the OPTSPEED directive instructs the Compiler
to give priority to execution
speed of the module at the expense of the size of the module.
However, you can probably achieve better results by looking at other
directives and programming techniques.
16-bit:
On the 16-bit COBOL system the REALOVL directive only affects segmented
programs. It causes separate overlays to be created for each independent
segment in your program.
REALOVL is only used for .obj files on DOS. If the .obj files are to be used on Windows or OS/2, you must always specify NOREALOVL.
A program that uses overlays (segmentation) is slower, but uses less memory, than a program that does not use overlays.
16-bit:
On the 16-bit COBOL system the TARGET directive is useful if you know
that your code is only going to be used on a particular chip-set. By
default, the Compiler produces code that executes on all of the Intel
80x86 family.
TARGET"286" produces code that contains instructions that only executes on the Intel 80286 chip or any chip that includes the Intel 80286 instruction set (such as the Intel 80386).
TARGET"386-16" includes instructions that can only be used on the Intel 80386 chip or later. This does not include 32-bit instructions - only those instructions that execute in 16-bit mode.
TARGET"386-32" is much like TARGET"386-16" but includes a small number of 32-bit instructions to speed up certain arithmetic operations.
16-bit:
On the 16-bit COBOL system the TRICKLE directive makes the Compiler
enforce all the rules of ANSI Standard COBOL for PERFORM statements.
NOTRICKLE tells the Compiler that nowhere in your program should control
trickle from one perform range into another. Specifying NOTRICKLE enables
the Compiler to generate slightly more efficient native code.
The TRUNC directive causes the Compiler to create code to determine whether USAGE COMP data items need to be truncated or not.
If you are certain that you do not need truncation of USAGE COMP data items, NOTRUNC causes the creation of more efficient code.
There are many directives you can use to optimize for size. In some cases, the defaults for Compiler directives are the choices that provide size optimization. This section points out directives that need to be changed from their default values to provide for size optimization.
This directive specifies the boundary on which level-01 and level-77 items start. This boundary should always be a power of two, such as two, four or eight. For the 16-bit COBOL system use a minimum of ALIGN"2". For 32-bit COBOL systems use a minimum of ALIGN"4". Use ALIGN"8" if you are using a 64-bit operating system. Higher powers of two retain efficiency, but increase the amount of unused space between data records.
16-bit:
On the 16-bit COBOL system the OPT directive sets the level of
optimization performed by the second pass of the Compiler. It affects both
the size and speed of the resulting module.
The OPT directive can be set to 0, 1 or 2. The default is 2.
OPT"0" produces an .obj file that contains the intermediate code produced by the first pass of the Compiler, instead of native code. This type of .obj must be linked with the shared run-time system (COBLIB).
Although an .obj file produced using OPT"0" generally runs much slower than native code (especially in computational intensive programs), it is often much smaller than an .obj file containing equivalent native code.
If you need the speed of native machine code, use OPT"2" as it provides additional optimization and usually creates a smaller file. However, beware of the possible side effects of this optimization. These are described in the section Using Directives to Optimize for Speed, earlier in this chapter.
16-bit:
On the 16-bit COBOL system, if your primary concern is the size of the
application on disk, use the OPTSIZE directive.
This directive tells the Compiler to give priority to the size of
the application at the expense of efficiency. However, you can probably
achieve better results by looking at other directives and programming
techniques.
16-bit:
On the 16-bit COBOL system, if you are linking your application so it
runs dynamically then you should use the /ST:2 linker option when you link
all the dynamically loadable executable files within your application.
This saves you about 2K on each dynamic executable file.
This should only be done for dynamic executable files since they inherit their stack from the root executable.
16-bit:
This section refers specifically to the 16-bit system.
You can see the native code produced for your program, by using the Compiler directives ASMLIST"" and SOURCEASM to produce a .grp file containing the assembler and source listing in the same file.
If the Compiler considers a statement for native code optimization, but finds that it does not conform to the necessary guidelines, the word "BADCODE" appears next to the statement, on the right-hand side of the listing. Some statements that have generated inefficient code are not identified in this way; you can find these by looking for a single statement that has generated a lot of assembler code.
Try to eliminate or at least reduce the inefficient statements in your program. But be aware, as you improve the efficiency of your program, you eventually reach a point where a lot of extra effort gives only small further gains.
You might get unexpected results from arithmetical operations involving floating point calculations, as COBOL does not round numbers by default. For example, say WS02 is defined as a COMP-2 data item, and the following operations are performed:
accept ws02 compute ws02 = ws01 display ws01
If you enter a value of 2.3 when requested by the program, the value displayed will be 2.29.
If you want values to be rounded you must specify the ROUNDED clause. The example above would be rewritten as:
accept ws02 compute ws02 rounded = ws01 display ws01
You can specify that all data-items in a program are rounded or truncated using the compiler directive FP-ROUNDING. See your Object COBOL User Guide for details.
16-bit:
On the 16-bit COBOL system the modules cobfp87.dle
and cobfp87d.lib
for DOS, cobfp87.dlw
and cobfp87w.lib
for Windows and cobfp87.dll
and cobfp87o.lib
for OS/2 provide
IEEE
floating-point support. This support is either via an emulation
module or by use of the
i87 math
coprocessor. The modules automatically detect the presence of an
i87 coprocessor at run time. If there is one they use it. Otherwise they
use an internal emulation of the i87 coprocessor.
If the NO87 environment variable is set, software emulation is used even if an i87 coprocessor is present. The value in NO87 can be used to inform the user of the forced emulation, as it is displayed on the screen at initialization. A value of space forces emulation but no message is displayed at run time.
For example:
set no87=Coprocessor present but emulation forced.
or
set no87=space
where space is one or more space characters.
However:
set no87=
when the "=" is not followed by a space unsets NO87.
The two COBOL floating-point data types provide full IEEE floating-point precision for all values that lie within the ranges:
| COMP-1 from | 8.43E-37 |
through | 3.37E38 |
-8.43E-37 |
through | -3.37E38 |
|
| COMP-2 from | 4.19E-307 |
through | 1.67E308 |
-4.19E-307 |
through | -1.67E308 |
Note: Although the underlying floating point support used by this COBOL system does support the above ranges, this COBOL system only supports 2 digit exponents.
The following table shows the relationship between storage size and significance.
| Type
|
Size
|
Significant digits
|
|---|---|---|
| COMP-1 | 4 bytes | 6-7 |
| COMP-2 | 8 bytes | 15-16 |
The exponent for an external floating-point data item cannot be more than two digits long. When a floating-point data item is referenced in an ACCEPT or DISPLAY statement, data is transferred via an implicit external floating-point data item.
The Compiler validates floating-point literals to ensure their values are compatible with the mainframe environment. Literal values that do not lie within the following range will cause a compile-time error:
| from | 0.54E -78 | through | 0.72 E +76 |
| and from | -0.54 E -78 | through | -0.72 E +76 |
32-bit and 64-bit:
32-bit and 64-bit COBOL systems provide IEEE floating-point support. The
following sections describe the range of values and the accuracy available
using floating-point support.
The range of values available with each of the two COBOL binary floating-point data types is as follows:
| COMP-1 from | 8.43E-37 | through | 3.37E38 |
| -8.43E-37 | through | -3.37E38 | |
| COMP-2 from | 4.19E-307 | through | 1.67E308 |
| -4.19E-307 | through | -1.67E308 |
Note: Although the underlying floating point support used by this COBOL system does support the above ranges, this COBOL system only supports 2 digit exponents.
The following table shows the relationship between storage size and significance.
| Type
|
Size
|
Significant digits
|
|---|---|---|
| COMP-1 | 4 bytes | 6-7 |
| COMP-2 | 8 bytes | 15-16 |
The compiler validates floating point literals to ensure their values are compatible with the mainframe environment. Literal values that do not lie within the following range will cause a compile-time error:
| from | 0.54 E -78 | through | 0.72 E +76 |
| and from | -0.54 E -78 | through | -0.72 E +76 |
All IEEE format binary floating-point values consist of:
If the value is non-zero, the exponent has a constant subtracted to give the starting value of the mantissa. Thus, the value of a double precision (COMP-2) item in terms of its mantissa (m) would be:
1*(2**m) + mb0*(2**(m-1)) + mb1*(2**(m-2)) + mb2*(2**(m-3)) + ... + 1*(2**(m-52))
where the mantissa bit (in this example, mb0 through mb51) can be 0 or 1. For COMP-1 (single precision) fields, this becomes an issue when the difference between the maximum and the minimum powers of 2 is greater than 23; for COMP-2 fields, the issue might arise when the difference between the maximum and minimum powers of 2 is greater than 52.
For example, if a COMP-2 field is expressed with one mantissa bit multiplied by 2**56, and another mantissa bit multiplied by 2**2, then the value in the field would need to be approximated, because 56 - 2 = 54, which is greater than 52. This would be true in any floating point implementation on any hardware platform. Additionally, the internal storage format of floating point numbers can differ from operating system to operating system; see page 2-40 of your Language Reference manual. These discrepancies can occur because of variations in the internal storage of floating point numbers between operating systems.
Binary floating point can only represent powers of 2 (both positive and negative), and combinations of these powers of 2. For example, a fractional decimal number is represented by adding together the combination of values from the sequence 1/2, 1/4, 1/8, 1/16, 1/32, and so on, that comes closest to the required value. Thus, a value such as 0.625 (i.e., 1/2 + 1/8) can be represented exactly, whereas other values are represented by an approximation (which might be slightly above or slightly below the true value). Similarly, an integer is represented by adding together the combination of values from the sequence 1, 2, 4, 8, 16, and so on, that comes closest to the required value. Thus, a value such as 625 ( which can be made up from 1 + 16 + 32 + 64 + 512) can be represented exactly, whereas other values are represented by an approximation.
This section looks at how you can handle large programs; that is, programs with Data Division and/or Procedure Division larger than 64K. The 16-bit COBOL system handles large programs differently from the 32-bit and 64-bit COBOL systems. 32-bit and 64-bit COBOL systems do not have the restrictions of the 16-bit COBOL system, and so handle large programs better.
16-bit:
This section looks at various problems associated with large programs on
the 16-bit COBOL system. It also shows some ways of overcoming these
problems.
This COBOL system supports the segmented addressing architecture used by DOS, Windows and OS/2 V1 on Intel 80x86 chips. The 32-bit flat addressing architecture used by OS/2 V2, Windows NT and by UNIX is not supported by the 16-bit COBOL system.
Under segmented addressing memory is organized in segments. No segment can be larger than 64K. To enable programs with code and/or data bigger than 64K to run, the Compiler automatically splits the code and data into segments and produces code to handle any data that crosses segment boundaries.
It is possible, using this COBOL system, to create and run programs that use more memory than is physically present in your personal computer. There are two ways you can do this:
The following sections look at these topics.
If the Data Division in a COBOL program is larger than 64K, the Compiler creates more than one data segment in which to store the entire Data Division.
The default memory model for this Compiler is MODEL " LARGE". This means that, in any one program, more than one data segment is allowed. However, MODEL "LARGE" implies that no individual data item crosses a segment boundary; that is, no data item starts in one data segment and ends in a different data segment. Therefore, if the Data Division in your program is larger than 64K, the Compiler automatically assumes MODEL " HUGE". This forces the Compiler to generate additional boundary crossing code to handle operations on any data item that crosses a segment boundary.
Crossing segment boundaries:
Operations on data items that cross
segment
boundaries are much slower than operations on items that fit
entirely in one data segment. Where possible, it is preferable for data
items that cross segment boundaries to be moved so that they no longer
cross a boundary. We recommend you use the 01SHUFFLE
Compiler directive to automatically move data items so that none
cross segment boundaries.
If you prefer, you can move items manually to give the same result. To help you do this, use the Compiler directives REF, CHIP"16" and FLAG-CHIP. When these directives are specified, the Compiler issues a warning message for any data item that crosses a segment boundary. The listing from the compilation includes the hexadecimal offset within the Data Division of the data item. You can use this to calculate the size of a FILLER item to insert before each offending data item to ensure that it does not cross a segment boundary.
For example, consider the following listing, produced by compiling with the REF, CHIP"16" and FLAG-CHIP directives:
1 $set ref chip"16" flag-chip 2 working-storage section 0 3 01 a. 160 4 03 b pic x(64500). 160 5 03 c pic x(1000). FD54 *460------------------------------ ( 0)--- FD54 ** Previous item crosses 64K boundary. FD54 Segment checking code produced. 5 procedure division. 0
The numbers down the right-hand side of the listing are the hexadecimal
offsets of the data items within the Data Division. You can see that
c starts at offset h"FD54" and crosses the segment
boundary. Although operations on c are handled correctly by
the Compiler, they are slower than if c did not cross the
boundary. To obtain the most efficient code, c should be
moved into the next data segment; that is, to offset h"010000".
To do this, a FILLER item of size:
h"010000" - h"FD54" = h"02DC" = 732 decimal
needs to be inserted before c. As a result, the program
becomes:
$set ref chip"16" flag-chip working-storage section. 01 a. 03 b pic x(64500). 03 filler pic x(732). 03 c pic x(1000). procedure division.
c is now entirely contained in the second data segment.
The problem with this approach is that it is sensitive to small changes
in the structure of the Data Division before c. To avoid
this, the above calculation to determine the number of FILLER bytes can be
performed automatically at compilation time, as follows:
$set reg chip"16" flag-chip
working-storage section.
01 a.
03 b pic x(64500)
78 filler-required value 65536 - next.
03 filler pic x(filler-required).
03 c pic x(1000).
When this program is compiled, the level-78 (constant) filler-required
is defined to be 65536 minus the address of the next data item to be
allocated. Thus the definition of the FILLER goes exactly up to the 64K
boundary, and c is at the start of the next segment. If the
structure of the DATA DIVISION before c is now changed such
that its size changes slightly, the size of the FILLER is automatically
adjusted so that c is still at the start of the next
segment.
If the data description for b contains an OCCURS clause,
you must insert a FILLER item with PIC X immediately before the level 78
item in order that the value of next corresponds to the end
of the table rather than the end of the first entry in the table.
Calls from large programs:
There is one other case to be considered. Suppose a program has a Data
Division containing more than 64K of data and contains a call to another
program with
parameters that cross
segment
boundaries.
For example, program Main contains the statement:
call "sub-prog" using c a b
where a, b and c all cross
segment boundaries.
Program Sub-prog contains the following:
linkage section. 01 a pic x(10). 01 b pic 9(4). 01 c pic zz9. procedure division using c a b.
When Sub-prog is compiled, the Compiler does not know that a,
b and c cross segment boundaries. By default,
it generates non-segment boundary crossing code for any operation on the
parameters. For those parameters that cross boundaries, this results in
incorrect action. Therefore, the Compiler needs to be told that some or
all of the parameters can cross segment boundaries so that it can generate
correct code.
There are two ways to instruct the Compiler to generate boundary crossing code for parameters:
For example, if in the above program, only a and
c can cross a boundary and b is guaranteed
never to cross a boundary, Sub-prog can be compiled with the directive
SEGCROSS"1,3", indicating that Linkage Section items 1 and 3
(a and c) cross segment boundaries. This
ensures that the fastest possible code is produced for all access to
b.
These directives are only needed if the Data Division of Sub-prog is less than 64K. If Sub-prog contains more than 64K of data, NOSMALLDD is turned on by default and so boundary crossing code is generated for all parameters.
If a program contains more than 64K of generated Procedure Division code, the Compiler can be instructed to split the code automatically to form multiple code segments . By default, if a code segment becomes greater than 64K, the Compiler gives a fatal error during the code generation stage:
* R009 - Segment too large. Try SEGSIZE(<65536)
If this happens, you have two options:
To get the best performance, we recommend you split the code into multiple segments yourself. By doing this, you can minimize the number of inter-segment PERFORM or GO TO operations (these are very slow).
Making the Compiler split code:
To make the Compiler split the code into multiple code segments, you
should specify the directive
SEGSIZE with a parameter specifying the maximum possible size of a
code segment. For example:
SEGSIZE"65000"
results in no code segment being greater than 65000 bytes in size. For most purposes, a value of 65535 is sufficient. The Compiler splits the code at the section immediately preceding the point at which the code becomes greater than 64K. If a section produces more than 64K of code, the following error is issued by the Compiler:
* R001 - No suitable place in code to segment on
(If you used the ANIM directive when compiling, this error message shows the line number of the source line that it was processing when the 64K limit was passed.)
In this case, to force the Compiler to split the section into separate code segments, you need to specify the directive 64KSECT. The Compiler then attempts to split the code at the paragraph immediately preceding the point at which the code becomes greater than 64K.
If a single paragraph produces more than 64K of code, the above error is issued by the Compiler. In this case, use the 64KPARA directive to force the Compiler to split the paragraph into separate code segments.
The Compiler has no knowledge of the structure of the program and might not split the code to form multiple code segments at the best point. Even if a program that is automatically segmented has satisfactory performance now, this might not be the case in the future as different code generation techniques change the size of the generated code and so cause the code to split at a different point. This might result in PERFORM and GO TO operations that previously referred to routines in the same segment becoming inter-segment PERFORM and GO TO operations and so becoming much slower. Therefore, it is preferable for you to segment your program yourself if possible.
This section describes the segmentation mechanism. You must be careful to choose a program that is ideally suited to segmentation. This form of segmentation applies only to the Procedure Division; as a result you must choose a program with a large Procedure Division. You must also select a program whose procedural code is logically divided into distinct phases. If this is not the case, and the flow of control from one segment to another involves a disk access to load the new segment, performance might be impaired. Consider the example in Figure 1-1 which shows the modular structure of a suitable program.
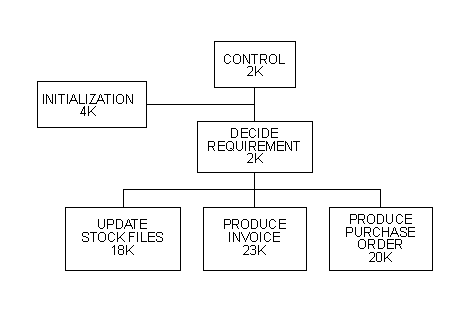
Figure 1-1: Program Flow
The program naturally divides into six logical segments. The "control" and "decide requirements" modules reside in the fixed or permanent segment (also known as the root segment), and the other four modules in transient or independent segments, as shown in Figure 1-2.
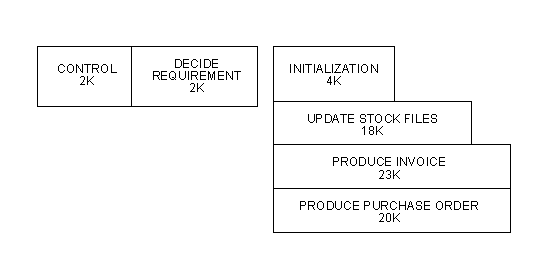
Figure 1-2: Program Divided into Segments
This reduces the memory requirement from 69K plus Data Division to 27K plus Data Division. The overhead is the time taken to access the disk each time control passes from one segment to another.
To segment a program, you must divide it into sections by using SECTION headers. Each group of sections with a common section number then forms a single segment.
For example:
. . .
. . .
section 52.
move a to b.
. . .
. . .
section 62.
move x to y.
. . .
. . .
You can use segmentation only on the Procedure Division. The Identification, Environment and Data Divisions are common to all segments. In addition there might be a common Procedure Division segment called the root segment. All of this common code is known as the permanent segment. See your Language Reference for a complete description of control flow between permanent and independent segments.
32-bit and 64-bit :
The 32-bit and 64-bit COBOL systems enable you to execute statically
linked or dynamically loaded code. Statically linked code is embedded
within the executable file. Dynamically loadable code is a COBOL code file
(.int or .gnt) that is loaded and run only when the file
is called. The code is held in a separate file to the executable file. The
dynamic loader loads COBOL program overlays as needed.
When designing a COBOL application program that is to be dynamically loadable, you want it to make efficient use of the available memory. It is possible, using this COBOL system, to create and run programs that use more memory than is physically present in your computer. You can do this by separating the program into smaller programs and using the COBOL call mechanism (see the section Inter-program Communication (CALL) later in this chapter).
The run-time system also provides another method for creating and running programs that use more memory than is physically present in your computer. It enables you to segment one large COBOL program so that it holds on disk the code that is not being used.
Note: Segmentation is not often required for 32-bit OS/2 V2 or Windows NT as memory management is not usually a problem. However, the facility is available should it be required and so is described here.
This section describes the segmentation mechanism, which enables you to divide a COBOL program with a large Procedure Division into a COBOL program with a small Procedure Division and a number of overlays containing the remainder of the Procedure Division. Segmentation enables all of the Procedure Division to be loaded into the available memory. However, because it cannot be loaded all at once, it is loaded one segment at a time to achieve the same effect in the reduced memory space.
To segment a program, you must divide it into sections by using a SECTION label. Each group of sections with a common section number then forms a single segment in the Procedure Division.
For example:
. . .
. . .
section 52.
move a to b.
. . .
. . .
section 62.
move x to y.
. . .
. . .
You can use segmentation only on the Procedure Division. The Identification, Environment and Data Divisions are common to all segments. In addition there might be a common Procedure Division segment called the root segment. All of this common code is known as the permanent segment. The Compiler allows space for the permanent segment and for the largest independent segment in a segmented program. See your Language Reference for a complete description of control flow between permanent and independent segments.
You can suppress segmentation at compile time using the NOSEG Compiler directive , even if you specify segment numbers. See yourObject COBOL User Guide for details on this directive.
This section looks at the inter-program communication (call) mechanism for creating large applications but avoiding large programs.
The COBOL system enables you to design applications as separate programs at source level. Each program can then be called dynamically from the main application program without first having to be linked dynamically with the other programs. Figure 1-3 shows an example of an application divided up in this way.
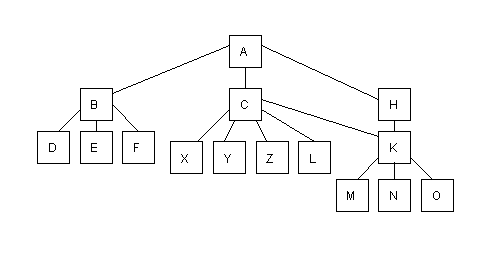
Figure 1-3: Application Divided Using CALL
The main program A, which is permanently resident in memory, calls B, C, or H, which are programs within the same suite. These programs call other specific functions as follows:
| B | calls D, E and F |
| C | calls X, Y, Z, L and K |
| H | calls K |
| K | calls M, N and O. |
Because the functions B, C and H are standalone they do not need to be permanently resident in memory together. You can call them as they are needed, using the same physical memory when they are called. The same applies to the lower functions at their level in the tree structure.
In the figure, you would have to plan the use of CALL and CANCEL operations so that a frequently called subprogram such as K would be kept in memory to avoid load time. On the other hand, because it is called by C or H, it cannot be initially called without C or H in memory; that is, the largest of C or H should call K initially so as to allow space. It is important also to avoid overflow of programs. At the level of X, Y and Z, the order in which they are loaded does not matter because they do not make calls at a lower level.
It is advantageous to leave called programs in memory if they open files, to avoid having to reopen them on every call. The EXIT statement leaves files open in memory. The CANCEL statement closes the files and releases the memory that the canceled program occupies, provided all other programs in the executable file have been canceled or never called.
If you use a tree structure of called, independent programs as shown earlier, each program can call the next dynamically by using the technique shown in the following sample coding:
working-storage section.
01 next-prog pic x(20) value spaces.
01 current-prog pic x(20) value "rstprg".
procedure division.
loop.
call current-prog using next-prog
cancel current-prog
if next-prog = spaces
stop run
end-if
move next-prog to current-prog
move spaces to next-prog
go to loop.
The programs to be run can then specify their successors as follows:
. . .
. . .
linkage-section.
01 next-prog pic x(20).
. . .
. . .
procedure division using next-prog.
. . .
. . .
move "follow" to next-prog.
exit program.
In this way, each independent segment or subprogram cancels itself and changes the name in the CALL statement to call the next one with the USING phrase.
Having decided to use the call mechanism for your application, the following sections look at some of the practical aspects of creating such applications on the 16-bit COBOL system. The following discussion assumes you are linking your application with the static linked run-time system .
The total number of programs which can be loaded in memory as the result of a call is not constant. The number depends on the amount of available memory in your personal computer and the size of the program being called.
There are also other considerations. For example, if the program being called has been linked as a dynamically loaded executable file, its memory requirements are much larger than if the same program has been linked with several other programs into one main program. This is because a dynamically called program has been linked with enough run-time system routines to satisfy its run-time requirements.
It is quite likely that the calling program has also had the same run-time system routines linked into it to satisfy its own run-time requirements, leading to duplication of code and hence greater memory usage. When programs are linked into a single .exe file, they share run-time system modules and there is no duplication of code. One disadvantage here is that programs linked into a single .exe file do not have their memory freed when they are canceled, as do dynamically called programs.
Another consideration regarding dynamically called programs is the amount of memory fragmentation at the time of the call. By calling and canceling dynamically linked subprograms, it is possible to have free areas of memory scattered among blocks of memory allocated to active subprograms. With free memory fragmented into several small blocks, there might not be enough contiguous free memory to load a dynamically linked subprogram. When a program is dynamically called, the following conditions affect its loading:
Having decided to use the call mechanism for your application, the following sections look at some of the practical aspects of creating such applications on the 32-bit and 64-bit COBOL systems.
The total number of programs which can be loaded in memory as the result of a call is not constant. The number depends on the amount of available memory in your computer and the size of the program being called.
On OS/2 V2 and Windows NT, canceling a COBOL program actually frees memory only if the l (lower-case "L") RTS switch is set to 0. If this switch is not set, the program is merely marked as being canceled (a logical cancel). Subsequent calls to a logically canceled program need only initialize the Data Division and mark the program active once more. With l0 set, the program must again be searched for on disk and loaded. If the limit set by the -l switch is exceeded, programs marked as canceled will be physically canceled in order to free memory resource. For full details on the l switch, see your Object COBOL User Guide.
Dynamically called programs have an advantage over programs that have been linked into a single executable file, in that dynamically called programs have their memory freed when they are canceled while the latter do not.
If a program is called and the program is dynamically loaded, the filename is used to identify it. If the program is statically linked then the Program-Id paragraph can be used. See the section Calling COBOL Subprograms for more details.
You can avoid many "program not found" errors by always using the filename without extensions as the program-name in the Program-Id paragraph. This enables flexibility in constructing your executable programs with statically or dynamically called programs.
For details on the Program-ID paragraph, see your Language Reference.
This section describes the various ways in which you can call a program and pass the command line to the main program as a parameter. The main program in a run unit is the first program within it; that is, the program which is called directly by the COBOL system.
As the maximum size, form and contents of the command line vary between operating systems, these issues need to be considered if you want to port your application between environments. For example, to ensure portability, a maximum command line size of 128 characters might be appropriate rather than the system limit. Similarly, only alphabetic and numeric characters with the equals sign (=) and space characters should be used for entering the command line for a program if you want to guarantee portability.
The command line can be accessed from COBOL using the syntax ACCEPT ... FROM COMMAND-LINE. The data-name ACCEPT FROM COMMAND-LINE statement causes the complete contents of the command line to be moved to data-name. See your Language Reference for details.
This section looks in more detail at how to call subprograms. It provides information on writing subprograms and passing parameters between them.
You can write subprograms or your main programs in the COBOL language or in some other language, such as C. You can mix these subprograms freely in an application. However, before you call a non-COBOL subprogram from a COBOL program, you must link it to either the dynamic loader run-time support module or to your statically or dynamically linked COBOL application.
A COBOL subprogram can be statically or dynamically linked, and it can also be dynamically loaded at run time.
A statically linked program is an executable object module, while a dynamically loadable module is either a COBOL intermediate code (.int), COBOL generated code (.gnt) file, or a COBOL dynamic link library (.dll).
A COBOL program can call a COBOL subprogram by using one of the following formats of the CALL statement:
CALL "literal" USING ...
or:
CALL data-name USING ...
For any COBOL programs, the literal string or the contents of the alphanumeric data item must represent the Program-ID, the entry point name, or the basename of the source file (that is, the filename without any extension). The path and filename for a module can also be specified when referencing a COBOL program, but we do not recommend you do this, as unexpected results can occur where the referenced module exists in more than one file, or type of format, or if the application is ported to other environments. For statically linked modules, the native code generator converts calls with literal strings to subroutine calls which refer to external symbols. The Micro Focus COBOL system automatically creates a routine to define the symbol and to load the associated file if it is entered at run time.
Note: Programs that are called at link time must have names that the system assembler and linker can accept; that is, they must not contain characters other than 0-9, A-Z, a-z, underscore (_), or hyphen (-). You must correct any entry point names that use characters other than these so that they are acceptable to the system assembler and linker.
Use a CALL literal statement to call a statically or dynamically linked program directly. If the program is not found a run-time system error is displayed unless the dynamic loader is present, in which case it will attempt to find a dynamically loadable version of the program.
Use either a CALL literal statement, or a CALL data-name statement, to call a dynamically loadable program, and make the dynamic loader run-time support module search for the called program.
DOS, WIndows and OS/2:
On the 16-bit COBOL system the dynamic loader is always present.
UNIX:
On UNIX, you might need to load the dynamic loader using the Cob utility.
See your Object COBOL User Guide for details.
The dynamic loader run-time support module follows this search order to find the named file:
If the dynamic loader run-time support module has to search for a file on disk and no path-name has been specified on the call, the search order followed is:
[;] path-name [;path-name] ...
For example:
set COBDIR=d:\cobol\lbr;d:\cobol\exedll
If you include the optional semicolon (;) at the beginning of the string, the dynamic loader run-time support module assumes the current directory is the first one to be searched
If you specify a directory path on the call, the dynamic loader support module searches for the file only in the named directory.
If you specify a file extension, the dynamic loader run-time support module searches only for a file with a matching extension. However, we recommend that you do not include an explicit extension in the filenames you specify to the CALL statement. If you specify a file without an extension, the dynamic loader run-time support module adds the extension .int to the base-name of the file, and searches the disk for the corresponding intermediate code file. If it cannot find the .int file, the dynamic loader run-time support module adds the extension .gnt to the base-name of the file, and searches for the corresponding .gnt file.
OS/2:
On OS/2, if the file is not found, the run-time system will attempt to
load a .dll file from LIBPATH using the specified base-name.
Windows NT:
On Windows NT, if the file is not found, the run-time system will attempt
to load a .dll file from PATH using the specified base-name.
OS/2:
On OS/2 you must not specify a .dll extension, or any call to a
.dll file that might also have entry points imported into the
application, as this can lead to unpredictable behavior.
The dynamic loader run-time support module always assumes that the first matching program name which it finds is the program you require to CALL.
If no matching program is found an RTS error occurs.
Note that if the first character of a filename which is to be dynamically loaded at run time is the dollar sign ($), the first element of the filename is checked for filename mapping. The first element of the filename consists of all the characters before the first backslash character (\).
See your Programmer's Guide to File Handling for details. For example, if the statement:
CALL "$MYLIB\A"
is found in the source program, the file A is loaded from the path as defined by the MYLIB environment variable at run time.
16-bit:
On the 16-bit COBOL system this functionality is only supported under the
shared run-time system.
You can access non-COBOL subprograms using the standard COBOL CALL ... USING statement. The address of each USING BY REFERENCE or USING BY CONTENT parameter is passed to the argument in the non-COBOL subprogram which has the same ordinal position in the formal parameter declarations. You must thus ensure all formal parameter declarations are pointers.
Note that if you use the CALL...USING BY VALUE form of the CALL...USING statement, the USING parameter is not passed BY VALUE if it is larger than four bytes long. If it is larger than this, it can be passed BY REFERENCE, but no warning is output to inform you of this. If you specify a numeric literal with a CALL...USING BY VALUE statement, it is passed BY VALUE as though it were a four-byte COMP-5 item; that is, it appears in machine-order as a data item and not as a pointer to that data item. If you specify a data item with a CALL...USING BY VALUE statement it must be defined as COMP-5.
You might need to specify a particular calling convention when interfacing to non-COBOL programs - see the chapter The COBOL Interfacing Environment for more information.
The following example shows how C functions can be accessed from a COBOL program:
$set rtncode-size"4"
working-storage section.
01 str.
03 str-text pic x(10).
03 filler pic x value x"00".
* Null terminate string for C function
01 counter pic 9(8) comp-5 value zero.
procedure division.
call-c section.
call "cfunc" using str, counter
if return-code not = zero
* RETURN-CODE set from return () in C
display "ERROR"
else
display "OK"
end-if
stop run.
------------------------------------------------
cfunc (st, c)
char *st;
int *c;
{
...
return(0);
}
When you use the CALL statement from within a COBOL program to access a non-COBOL module as described above, you must ensure that the COBOL run environment is not accidentally damaged. This means, you must ensure that:
The CANCEL statement has no effect when it references a non-COBOL program .
32-bit:
The 32-bit COBOL system traps unexpected signals and returns run-time
system errors:
114 Attempt to access item beyond bounds of memory
115 Unexpected signal
Where C and COBOL modules are linked, these error messages are usually due to an error in the C code which causes a hardware interrupt for such conditions as segmentation violation. If you do receive these run-time system errors, carefully check the C source routines using the system debugger, paying particular attention to the format and byte ordering of parameters passed between the COBOL and C modules.
COBOL programs can contain ENTRY statements. An ENTRY statement identifies a place where execution can begin as an alternative to the Procedure Division if a calling program so specifies.
COBOL fully supports entry points, but the dynamic call loader presents a potential problem. Because the RTE typically defaults to looking for called programs dynamically, there is no way for the RTE to locate a particular entry point embedded in a program on disk. When you execute a call statement like:
call "abc" using ...
the RTE first looks for a program or entry point called abc
in all of the programs and libraries that have already been loaded. If it
does not find the program, the RTE then looks for a file called abc.ext
where .ext is one of the executable file formats
defined in the section Executable Files earlier in this chapter.
If abc represents the name of an entry point contained in
another program, the RTE cannot locate the file on disk, and a "program
not found" message is issued. The RTE does not scan through every
individual executable file on disk to locate an entry point.
Therefore, you must load the program containing the called entry point into the RTE.
One technique that you can use to do this is to create a .lbr file that contains any programs containing entry points that need to be preloaded. You can create the .lbr file (library file), using the Library facility. Once the .lbr file is created, you can issue a call to the .lbr file.
Note: When you call an .lbr file, the RTE does not load every program in the .lbr into the RTE. Instead, the RTE registers the existence of all programs and entry points contained in the called .lbr file, for future reference. Later when one of these programs contained in the .lbr is called, the RTE notes that it is contained in the .lbr and loads it at that point.
Once a program that contains the entry points is loaded into the RTE, all entry points contained in the program are identified to the RTE and are available to be called by any program loaded later. This means that if you need to call entry points in a particular program from another program, you must ensure that the program is loaded first, so the RTE can register these entry points.
The standard COBOL calling convention is:
call progname using ...
or:
call "progname" using ...
where progname (without quotation marks) is a data item
that contains a valid program-name, and "progname"
(with quotation marks) is the actual name of a valid program.
A program-name is a character string representing the program or subprogram to be called. In the RTE, this name is treated as an implicit program-name; that is, there is no filename extension in the program-name.
This means the actual executable file being called might be in any of the following supported executable formats:
When progname.lbr is found, the RTE opens the .lbr file and locates and loads an executable file with the same program-name, for example progname.gnt, progname.int, progname.exe or progname (no extension) from the .lbr file.
An explicit program-name can be specified in the call statement as well:
call "progname.gnt" using ....
This forces the RTE to look for the exact filename specified, in this case progname.gnt. If the exact program-name is not located a "program not found" error message is issued.
Additionally, a program call can be fully qualified with a PC drive/path name:
call "c:\programs\myprog" using ....
or:
call "c:\programs\myprog.gnt" using ...
This forces the RTE to look in the directory you have specified in the path name portion of the program-name.
In the example above, the RTE looks in the c:\programs
directory.
Once started, the RTE sets up a 32-bit addressing virtual storage environment in which it loads and manages all called subprograms. When the RTE locates and loads a called program, it assigns a unique RTE identifier to the program. (This identifier is used internally in the RTE.) The RTE allocates memory (both real and virtual) for the program, and can swap portions of it out to disk as needed.
The RTE records the actual location, drive and path-name as well. Once loaded into the RTE, the RTE uses the same copy of the program unless it is canceled and recalled.
Whenever a COBOL program running under the RTE issues a call to a subprogram, the RTE goes through the following steps:
As described above, the RTE can search for multiple executable files, and can search for these program files in more than one directory on the PC.
Note: The search sequences described below apply to executable files (programs). It does not apply to other file types, for example data files and COBOL source files.
You do not need to be concerned about search conventions if you only have one executable version of your program on disk. This discussion only applies if you have multiple executable files available.
Whenever a COBOL program issues an explicit call to a subprogram, for example:
call "myprog.gnt" using ...
the RTE searches for a file with the specified extension.
In this case, the RTE searches for myprog.gnt. It does not
search for other valid executable formats with the same program-name but
different extension, for example myprog.exe.
When a program issues an implicit call, that is, a call to a program-name without specifying a file extension, the RTE searches for the called program in the order listed below.
When a program issues a call like:
call "proga" using ...
the RTE searches through the following sequence looking for proga:
| 1. | proga.gnt | |
| 2. | proga.int | |
| 3. | proga.lbr | The RTE opens this .lbr file and searches it for an executable name proga.ext where .ext is one of the other executable file types listed here. (except .dll/.dlw files) |
| 4. | proga.exe | DOS only |
| 5. | proga.dlw proga.dll |
Windows V3 only Windows NT and OS/2 |
| 6. | proga | No extension |
If none of the above are found, the RTE issues the message, "program not found".
You can change the order in which the RTE searches for files by setting the I1 run-time switch. This causes the RTE to search for files in the order :
| 1. | proga.int |
| 2. | proga.gnt |
| 3. | proga.lbr |
This is useful for testing when you are typically compiling only to intermediate (.int) code.
When the RTE finds and loads a program, it records the location (drive and path) where the program was first found. If the program issues a later call to another program, the RTE does not look in the current directory for the new program being called. Instead, it defaults back to the same directory where the calling program was first found.
If the RTE cannot find the called program in the same directory that the calling program is in, the RTE begins its standard search sequence to try to locate the called program. This technique, known as inheritance, is the default behavior for the RTE.
16-bit:
You can deactivate inheritance, by setting the
L6 run-time switch off. For example, when you invoke the
Professional COBOL Environment on the DOS or OS/2 command line, enter:
DOS and OS/2:
proco (-L6)
or on Windows:
Windows:
procow (-L6)
This forces the RTE to look first for a called program in the current directory instead of in the directory containing the calling program. More details on the impact of inheritance on the RTE's search sequence are given in the section Searching Through Multiple Directories later in this chapter.
The COBDIR environment variable tells the RTE where to look for called programs. This environment variable is set up by the operating system SET statement. For example:
set cobdir=c:\cobol
The default directory structure for the Setup program divides the Toolset system software into multiple directories on the PC. For example, by default the .exe, .dle, .dlw, and .dll files are installed in a directory named \cobol\exedll. The .lbr and .gnt files are installed in a directory named \cobol\lbr.
This means that COBDIR must be set, as a minimum, to:
set cobdir=d:\cobol\lbr;d:\cobol\exedll
where:
d: |
represents the drive that you install to |
cobol |
represents the directory that you install to. |
16-bit Windows:
On the 16-bit COBOL system you must set the COBDIR environment variable
in DOS before entering Windows, and it cannot be altered while in Windows.
For example, suppose you have your programs in directory d:\programs
and you position to that directory using the Change Directory command:
cd \programs
When you animate or run your programs, the RTE searches for and locates your programs when they are called.
If, however, you have some programs in a directory that is neither the current directory, nor included in the COBDIR environment variable, the RTE cannot find them.
Including this directory in the DOS PATH has no effect because the RTE does not use the PATH to locate programs. This means that you need to include any non-current directories containing programs you want to call in the COBDIR environment setting.
It is also important to understand the way the RTE searches for various executable files through the multiple directories that can be set in the COBDIR environment variable. For example, if your program issues a call to a program like:
call "myprog" using ...
the RTE initially searches its active directory to see if myprog
has already been loaded (and not subsequently canceled).
If it has been loaded, the RTE passes control to myprog.
It does not refresh the program's Data Division unless:
A later call then forces the RTE to locate it again and load a fresh
copy.
The order in which the RTE searches the directories depends on whether the RTE inheritance feature is active. Inheritance is set using the L6 RTE switch, which by default is on. For details on setting switches, see your Object COBOL User Guide.
When inheritance is active, the RTE begins its search sequence in the same directory in which it found the calling program.
If it does not find myprog.gnt there, it then looks for
myprog.int, and then myprog.lbr, and then
myprog.exe under DOS only, and then myprog.dlw
under Windows only, and then myprog.dll under Windows or
OS/2. Lastly, it looks for myprog without any file
extension.
If none of the executable files are found in the directory of the calling program, the RTE then repeats the search sequence in each directory specified in COBDIR. If it reaches the last directory without finding an executable file, the RTE issues a "program not found" error message.
If you deactivate inheritance by setting the L6 RTE switch off (that is, -L6), then instead of looking in the directory where the calling program was found, the RTE starts its search in the current directory. It follows the search sequence described above, next searching each directory specified in the COBDIR, in the order you specified.
Note: You should be aware of the impact of inheritance on the RTE search sequence. If you have the same program-name in more than one directory, you can access the wrong version.
32-bit on OS/2 and Windows NT:
On the 32-bit run-time systems for Windows and OS/2, Object COBOL
programs can execute safely in multi-threaded environments such as
MQSeries Three Tier applications, using the SERIAL compiler directive and
thread_safe run-time tunable.
Normally, any attempt to run COBOL programs concurrently in separate threads of the same process results in unexpected behaviour, and would probably cause abnormal termination of the application.
The support provided by Object COBOL prevents the execution of a COBOL program in more than one thread in a single process at any given time. As soon as a COBOL program has been entered on a thread, any attempt to execute a COBOL program on a different thread is blocked by the run-time system until all COBOL programs in the first thread have exited (that is, until no COBOL programs exist on the call stack for that thread). At this point, the run-time system allows one of the threads that it had previously blocked to execute. All other COBOL threads are then blocked until all COBOL programs have exited on this thread, and so on.
The run-time system implicitly invokes thread-checking code on entry to intermediate code programs. However, generated code programs need to be compiled with the compiler directive SERIAL for them to successfully run in a multi-threaded environment. Only the first COBOL program to be executed on any given thread needs to be compiled using this directive.
For COBOL programs to be able to run on more than one thread, the main program needs to be non-COBOL. If the main program is a COBOL program, then any attempt to run a COBOL program on a secondary thread is blocked until the main program has terminated. This would mean that the secondary threads never execute because as soon as the main program terminates, so does the process.
No syntax is provided to initiate or manage threads. New threads should be created using system APIs (such as CreateThread() on Windows and DosCreateThread() on OS/2), or the C library function _beginthread(). The working-storage of a COBOL program is shared across all threads on which it is invoked.
The run-time tunable thread_safe enables COBOL
thread-safety to be switched off.
Copyright © 1998 Micro Focus Limited. All rights reserved.
This document and the proprietary marks and names
used herein are protected by international law.
| Advanced Language Features | |