

| Data Division - Screen Section | Procedure Division - Intrinsic Functions | |
![]() The Procedure Division is
optional
. The procedure division in a program definition
The Procedure Division is
optional
. The procedure division in a program definition
![]() function definition, or
function definition, or
method definition contains procedures to be executed. These
procedures can be declarative and/or nondeclarative.
![]() The procedure division for an
object definition and a factory definition contains the methods that may
be invoked on the object or factory object.
The procedure division for an
object definition and a factory definition contains the methods that may
be invoked on the object or factory object.
![]() The procedure division in a
call prototype contains no procedures, except that it may contain the
ENTRY statement.
The procedure division in a
call prototype contains no procedures, except that it may contain the
ENTRY statement.
![]() The procedure division in a
function prototype specifies the parameters and returning item, if any.
The procedure division in a
function prototype specifies the parameters and returning item, if any.
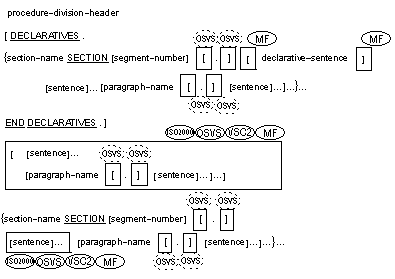
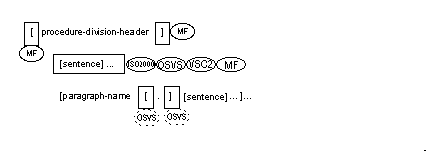

The generic term procedure-division-header is described in the next section, Procedure Division Header.
Formats 1 and 2 can be used only in
![]() a function definition, a
function prototype definition,
a function definition, a
function prototype definition,
![]() a method definition, a
program definition or a
a method definition, a
program definition or a
![]() call prototype.
call prototype.
Format 3 can be used only in a
![]() factory definition
factory definition
, an
![]() object definition
object definition
, or an
![]() interface definition.
interface definition.
The declarative sentence shown above is a USE statement (see the section later in this chapter and the chapters Debug Module and Report Writer in your Language Reference - Additional Topics). It specifies when the section is to be executed.
A procedure is composed of a paragraph or group of paragraphs, or a section or group of sections in the Procedure Division. A procedure-name is a word used to refer to a paragraph or section in the source element in which it occurs. It consists of a paragraph-name (that may be qualified) or a section-name.
If one paragraph is in a section, all must be.
![]() This rule is not enforced.
This rule is not enforced.
A paragraph comprises a paragraph-name followed by a period and a space, and any number of sentences or, if the paragraph-name is omitted, one or more successive sentences following the procedure division header or a section header. It is terminated either immediately before the next paragraph-name or section-name or at the end of the Procedure Division, or, in the declaratives portion, with END DECLARATIVES.
A section comprises a section header followed by any number of paragraphs. It is terminated either immediately before the next section or at the end of the Procedure Division, or, in the declaratives portion, with END DECLARATIVES.
![]() However, a section in the
declaratives need not have a declarative-sentence; it can be invoked by a
PERFORM statement. (See the section The PERFORM Statement later in
this chapter for details of the PERFORM statement.)
However, a section in the
declaratives need not have a declarative-sentence; it can be invoked by a
PERFORM statement. (See the section The PERFORM Statement later in
this chapter for details of the PERFORM statement.)
![]() Sentences that are not
explicitly contained within a named paragraph as described above are
considered to be contained within an unnamed implicit paragraph.
Paragraphs that are not explicitly contained within a section are
considered to be contained within an implicit, unnamed section.
Sentences that are not
explicitly contained within a named paragraph as described above are
considered to be contained within an unnamed implicit paragraph.
Paragraphs that are not explicitly contained within a section are
considered to be contained within an implicit, unnamed section.
In a program definition or
![]() method definition,
method definition,
execution
begins with the first statement in the Procedure Division, excluding
declaratives. Statements are then executed in the order in which they are
written, except where the rules indicate some other order.
![]() In a call prototype the
Procedure Division is never executed.
In a call prototype the
Procedure Division is never executed.
In an
![]() object definition or a
object definition or a
![]() factory definition,
factory definition,
declaratives behave in the same way as if they had been specified in every
contained method definition.
This segment of the chapter deals with arithmetic and conditional expressions, common and input/output phrases, intrinsic functions and COBOL verbs.
![]() The procedure-division-header
is optional in Format 2 of the Procedure Division. However, it is only
optional if there are no divisions coded before this and if the Procedure
Division begins with a COBOL sentence (not a section header, paragraph
header, or Declarative Section).
The procedure-division-header
is optional in Format 2 of the Procedure Division. However, it is only
optional if there are no divisions coded before this and if the Procedure
Division begins with a COBOL sentence (not a section header, paragraph
header, or Declarative Section).
The Procedure Division is identified by and must begin with a header in one of the following formats:
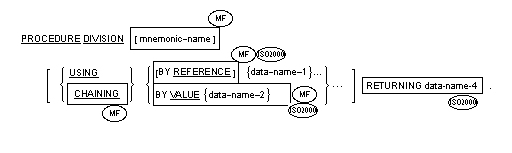
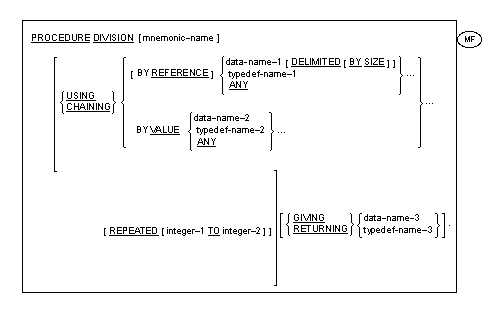
![]() Mnemonic-name must be
defined in the SPECIAL-NAMES paragraph. See the section The
Special-Names Paragraph earlier in this chapter for details of how
to do this and your COBOL system documentation on interfacing for
details of which calling conventions are supported in your run time
environment.
Mnemonic-name must be
defined in the SPECIAL-NAMES paragraph. See the section The
Special-Names Paragraph earlier in this chapter for details of how
to do this and your COBOL system documentation on interfacing for
details of which calling conventions are supported in your run time
environment.
![]() File Section or Working-Storage Section
File Section or Working-Storage Section
. A particular user-defined word must not appear more than once as data-name-1.
![]() It may appear more than
once.
It may appear more than
once.
The data description entry for data-name-1 must not contain a REDEFINES clause.
![]() It may contain a
REDEFINES clause.
It may contain a
REDEFINES clause.
Data-name-1 may, however, be the object of a REDEFINES clause elsewhere in the Linkage Section.
![]() a method definition or
a method definition or
![]() a program definition.
a program definition.
![]() Up to sixty-two
data-names are permitted in the USING phrase.
Up to sixty-two
data-names are permitted in the USING phrase.
![]() function or
function or
![]() method for any arguments
passed to it. The arguments passed to it are identified in the
activating source element by one of the following:
method for any arguments
passed to it. The arguments passed to it are identified in the
activating source element by one of the following:
The correspondence between the two lists of names is established on a positional basis
An arithmetic expression can be an identifier of a numeric elementary item, a numeric literal, such identifiers and literals separated by arithmetic operators, two arithmetic expressions separated by an arithmetic operator, or an arithmetic expression enclosed in parentheses. Any arithmetic expression can be preceded by a unary operator. The permissible combinations of variables, numeric literals, arithmetic operator and parentheses are given in Table 10-1.
Those identifiers and literals appearing in an arithmetic expression must represent either numeric elementary items or numeric literals on which arithmetic can be performed.
Table 10-1: Combination Of Symbols In Arithmetic Expressions
| First Symbol | Second Symbol | ||||
|---|---|---|---|---|---|
| Variable | * / ** + – | Unary + – | ( | ) | |
| Variable | – | P | – | – | P |
| * / ** + – | P | – | P | P | – |
| Unary + – | P | – | – | P | – |
| ( | P | – | P | P | – |
| ) | – | P | – | – | P |
| P | indicates a permissible pair of symbols |
| – | indicates an invalid pair |
| Variable | indicates an identifier or literal |
Five binary arithmetic operators and two unary arithmetic operators can be used in arithmetic expressions. They are represented by specific characters that must be preceded by a space and followed by a space.
| Binary Arithmetic
Operators |
Meaning |
|---|---|
| + | Addition |
| – | Subtraction |
| * | Multiplication |
| / | Division |
| ** | Exponentiation |
| Unary Arithmetic Operators |
Meaning |
|---|---|
| + | The effect of multiplication by numeric literal +1 |
| – | The effect of multiplication by numeric literal -1 |
| 1st | Unary plus and minus |
| 2nd | Exponentiation |
| 3rd | Multiplication and division |
| 4th | Addition and subtraction |
Arithmetic expressions may appear in a number of places , notably in the COMPUTE, IF and SEARCH verbs, and reference modification.
These expressions are evaluated at run time to give a single numerical result. The operands of a numerical expression may be either numeric constants or numeric variables.
Expressions are evaluated using the normal rules of precedence. Thus, in the expression:
1 + 2 * 3
the order of evaluation is:
yielding an intermediate result of 6
giving a result of 7.
As the expression is evaluated, one or more intermediate results is derived. Conceptually, each intermediate result is stored in a temporary data item, the value of which is determined by the parameter you select in the ARITHMETIC Compiler directive.
The Micro Focus COBOL system can evaluate each intermediate result using up to 18 integer and 18 decimal places. If you select the ARITHMETIC"MF" Compiler directive, intermediate results are not truncated, and thus this maximum accuracy is obtained. In this instance, each intermediate result has a picture of 9(18)V9(18).
The OS/VS COBOL, VS COBOL II, DOS/VS COBOL and COBOL/370 systems compute intermediate results to an accuracy determined by the pictures of the operands in the expressions. The rules, which are slightly different for each version of COBOL, are documented in appendices of the IBM VS COBOL for OS/VS manual and the VS COBOL II Application Programming Guide. Thus, each intermediate result has a picture of 9(n)V9(m). The maximum value of n+m is 30.
If you specify the OSVS or VSC2 options for intermediate results, this COBOL system will emulate the selected mainframe behavior by truncating its results accordingly, with the following limitations:
Conditional expressions identify conditions that are tested to enable selection between alternate paths of control depending upon the truth value of the condition. Conditional expressions are specified in the
![]() EVALUATE,
EVALUATE,
IF, PERFORM and SEARCH statements. Two categories of conditions are associated with conditional expressions: simple conditions and complex conditions. Each can be enclosed within any number of paired pare ntheses, in which case its category is not changed.
![]() If the
OSVS Compiler directive is set,
reference modification cannot be used within a conditional
expression.
If the
OSVS Compiler directive is set,
reference modification cannot be used within a conditional
expression.
The simple conditions are the relation, class, condition-name, switch-status, and sign conditions. A simple condition has a truth value of "true" or "false". The inclusion in parentheses of simple conditions does not change the simple truth value.
A relation condition causes a comparison of two operands, each of which can be the data item referenced by an identifier, a literal or the value resulting from an arithmetic expression. A relation condition has a truth value of "true" if the relation exists between the operands. Comparison of two numeric operands is permitted regardless of the formats specified in their respective USAGE clauses. However, for all other comparisons the operands must have the same usage. If either of the operands is a group item, the nonnumeric comparison rules apply.
![]() A nonnumeric literal can be
enclosed in parentheses.
A nonnumeric literal can be
enclosed in parentheses.
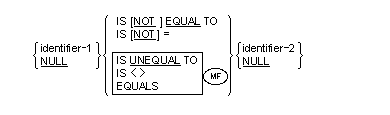
The general format of a relation condition is as follows:

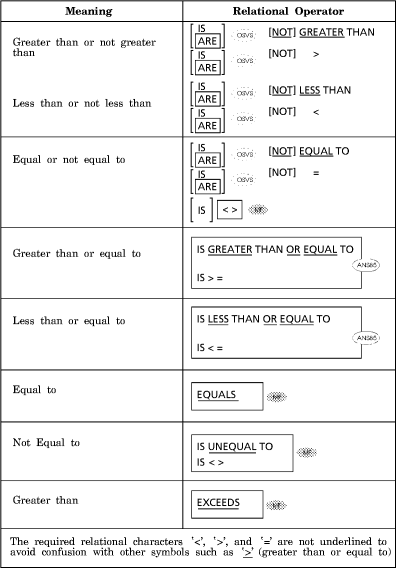
Note that the required relational characters "<" , ">", and "=" are not underlined, to avoid confusion with other symbols such as " “ ".
![]() Note that " = TO", ">
THAN" and "< THAN" will be accepted.
Note that " = TO", ">
THAN" and "< THAN" will be accepted.
The first operand (identifier-1, literal-1 or arithmetic-expression-1) is called the subject of the condition; the second operand (identifier-2 or literal-2 or arithmetic-expression-2) is called the object of the condition. The relation condition must contain at least one reference to a variable.
The relational operator specifies the type of comparison to be made in a relation condition. A space must precede and follow each reserved word comprising the relational operator. When used, "NOT" and the next key word or relation character are one relational operator that defines the comparison to be executed for truth value; for example, "NOT EQUAL" is a truth test for an "unequal" comparison; " NOT GREATER" is a truth test for an "equal" or "less" comparison. The meaning of the relational operators is as shown in Table 10-2.
The following relational operators are equivalent:
| IS EQUAL TO | and | EQUALS; |
| IS NOT EQUAL TO | and | IS UNEQUAL TO; |
| IS GREATER THAN | and | EXCEEDS; |
| IS NOT GREATER THAN | and | IS LESS THAN OR EQUAL TO; |
| IS NOT LESS THAN | and | IS GREATER THAN OR EQUAL TO. |
Table 10-2: Relational Operators
Comparison of Num eric Operands
For operands whose class is numeric a comparison is made with respect to the algebraic value of the operands. The length of the literal or arithmetic expression operands in terms of number of digits represented, is not significant. Zero is considered a unique value regardless of the sign.
Comparison of these operands is permitted regardless of the manner in which their usage is described. Unsigned numeric operands are considered positive for purposes of comparison.
Numeric edited items are of class alphanumeric, and comparisons involving them follow the rules for comparison of nonnumeric operands, as below.
Comparison of Nonnumeric Operands
For nonnumeric operands, or one numeric and one nonnumeric operand, a comparison is made with respect to a specified collating sequence of characters (see the section The OBJECT-COMPUTER Paragraph earlier in this chapter). If one of the operands is specified as numeric, it must be an integer data item or an integer literal and:
The size of an operand is the total number of standard data format characters in the operand.
![]() Comparison of a numeric edited data item with figurative constants is
allowed and is treated as an alphanumeric comparison.
Comparison of a numeric edited data item with figurative constants is
allowed and is treated as an alphanumeric comparison.
![]() Numeric and nonnumeric
operands can be compared when their usage is not the same. The numeric
operand is treated as if it were moved to a USAGE DISPLAY item of the same
size (in terms of standard data format characters), and the contents of
this were then compared to the nonnumeric operand.
Numeric and nonnumeric
operands can be compared when their usage is not the same. The numeric
operand is treated as if it were moved to a USAGE DISPLAY item of the same
size (in terms of standard data format characters), and the contents of
this were then compared to the nonnumeric operand.
There are two cases to consider:
The first encountered pair of unequal characters is compared to determine their relative position in the collating sequence. The operand that contains the character that is positioned higher in the collating sequence is considered to be the greater operand.
Comparisons Involving Index-Names and/or Index Data Items
Relation tests can be made only between:
![]()
Two items whose USAGE is either implicitly or explicitly POINTER can be compared. Only the relational operators which test for exact equality or inequality are permitted in pointer com parisons.
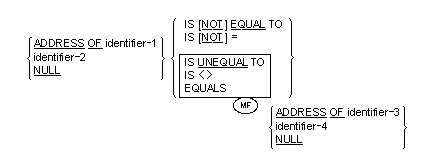
Two items whose USAGE is PROCEDURE-POINTER can be compared.
The class condition determines whether the operand is numeric, or alphabetic
![]() or alphabetic-lower, or
alphabetic-upper, or contains only the characters in the set of characters
specified by the CLASS clause as defined in the SPECIAL-NAMES paragraph of
the Environment Division.
or alphabetic-lower, or
alphabetic-upper, or contains only the characters in the set of characters
specified by the CLASS clause as defined in the SPECIAL-NAMES paragraph of
the Environment Division.
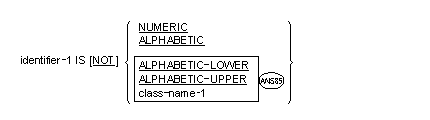
![]() or the lowercase
letters a, b, c, ... , z, space,
or the lowercase
letters a, b, c, ... , z, space,
or any combination of the uppercase
![]() and lowercase
and lowercase
letters and spaces.
![]() COMPUTATIONAL,
COMPUTATIONAL-X,
COMPUTATIONAL,
COMPUTATIONAL-X,
![]() COMPUTATIONAL-3
COMPUTATIONAL-3
![]() COMPUTATIONAL-5
COMPUTATIONAL-5
![]() or PACKED-DECIMAL.
or PACKED-DECIMAL.
![]() or national function.
or national function.
When used, NOT and the next key word specify one class condition that defines the class test to be executed for truth value; e.g. NOT NUMERIC is a truth test for determining that an operand is nonnumeric. When the class condition includes the word NOT and identifier-1 is a zero-length group item, the result of the class test is always true.
![]() The truth value of a
class test involving a zero-length group item is reversed by the
ZEROLENGTHFALSE Compiler directive.
The truth value of a
class test involving a zero-length group item is reversed by the
ZEROLENGTHFALSE Compiler directive.
![]() The NUMERIC test can be
used with an item defined as a group item composed of elementary items
whose data description indicates the presence of operational sign(s).
The NUMERIC test can be
used with an item defined as a group item composed of elementary items
whose data description indicates the presence of operational sign(s).
![]() and any combination of
the lowercase alphabetic characters "a" through "z"
and any combination of
the lowercase alphabetic characters "a" through "z"
and the space.
![]() The class condition
cannot be used for external floating- point (USAGE DISPLAY) or
internal floating-point (USAGE COMP-1 and USAGE COMP-2) items.
The class condition
cannot be used for external floating- point (USAGE DISPLAY) or
internal floating-point (USAGE COMP-1 and USAGE COMP-2) items.
In a condition-name condition, a conditional variable is tested to determine whether or not its value is equal to one of the values associated with a condition-name.
![]()
A switch-status condition determines the "on" or "off" status of one of the
![]() nine
nine
COBOL switches
![]() named respectively SWITCH-0
through SWITCH-8.
named respectively SWITCH-0
through SWITCH-8.
The value of each of these switches ("on" or "off" ) is set by the operator at the start of execution of the COBOL run unit. (See the discussion of run-time switches in your COBOL system documentation for details.) The switch and the "on" or "off" value associated with the condition must be named in the SPECIAL-NAMES paragraph of the Environment Division described earlier in this chapter.
![]()
The result of the test is true if the switch is set to the specified position corresponding to the condition-name.
If the compiler directive SWITCH-TYPE is set to 1, which is the default, it is only possible to use the Switch-Status Condition to test if a COBOL switch is set from within the runtime element that set the switch.
If the compiler directive SWITCH-TYPE is set to 2, which is set by the compiler when the compiler directive DIALECT is set to ISO2000, it is possible to use the Switch-Status Condition to test if a COBOL switch is set from within any runtime element of the run unit.
The sign condition determines whether or not the algebraic value of an arithmetic expression is less than, greater than, or equal to zero. The general format for a sign condition is as follows:
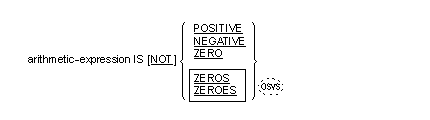
When used, "NOT" and the next keyword specify one sign condition that defines that algebraic test to be executed for truth value; for example, "NOT ZERO" is a truth test for a nonzero ( positive or negative) value. An operand is positive if its value is greater than zero, negative if its value is less than zero, and zero if its value is equal to zero. The arithmetic expression must contain at least one reference to a variable.
![]() ZEROS or ZEROES can be used
instead of ZERO in a sign test.
ZEROS or ZEROES can be used
instead of ZERO in a sign test.
A complex condition is formed by combining simple conditions, combined conditions and/or complex conditions with logical connectors (logical operators "AND" and "OR" ) or negating these conditions with logical negation (the logical operator "NOT"). The truth value of a complex condition, whether parenthesized or not, is that truth value which results from the interaction of all the stated logical operators on the individual truth values of simple conditions, or the intermediate truth values of conditions logically connected or logically negated.
The logical operators and their meanings are:
| Operator |
Meaning |
|---|---|
| AND | Logical conjunction; the truth value is "true" if both of the conjoined conditions are true; "false" if one or both of the conjoined conditions is false. |
| OR | Logical inclusive OR; the truth value is "true" if one or both of the included conditions is true; "false" if both included conditions are false. |
| NOT | Logical negation or reversal of truth value; the truth value is "true" if the condition is false; "false" if the condition is true. |
The logical operators must be preceded by a space and followed by a space.
A simple condition is negated through the use of the logical operator "NOT". The negated simple condition effects the opposite truth value for a simple condition. Thus the truth value of a negated simple condition is "true" if and only if the truth value of the simple condition is "false" ; the truth value of a negated simple condition is "false" if and only if the truth value of the simple condition is "true". The inclusion in parentheses of a negated simple condition does not change the truth value.

A combined condition results from connecting conditions with one of the logical operators "AND" or "OR".
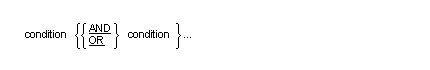
Table 10-3 indicates the ways in which conditions and logical operators can be combined and parenthesized. There must be a one-to-one correspondence between left and right parentheses such that each left parenthesis is to the left of its corresponding right parenthesis.
Table 10-3: Combinations of Conditions, Logical Operators, and Parentheses
| Element | Permitted location in conditional expression | Element can be preceded by only: | Element can be followed by only: |
|---|---|---|---|
| simple-condition | Any | OR, NOT, AND, ( | OR, AND, ) |
| OR or AND | Not first or last | simple-condition, ) | simple-condition, NOT, ( |
| NOT | Not last | OR, AND, ( | simple-condition, ( |
| ( | Not last | OR, NOT, AND, ( | simple-condition, NOT, ( |
| ) | Not first | simple-condition, ) | OR, AND, ) |
Thus, the element pair "OR NOT" is permissible while the pair "NOT OR" is not permissible; "NOT ( " is permissible while "NOT NOT" is not permissible.
When simple or negated simple relation conditions are combined with logical connectives in a consecutive sequence such that a succeeding relation condition contains a subject or subject and relational operator that is common with the preceding relation condition, and no parentheses are used within such a consecutive sequence, any relation condition except the first can be abbreviated by:

Within a sequence of relation conditions both of the above forms of abbreviation can be used. The effect of using such abbreviations is as if the last preceding stated subject were inserted in place of the omitted subject, and the last stated relational operator were inserted in place of the omitted relational operator. The result of such implied insertion must comply with the rules of Table 10-3. This insertion of an omitted subject and/or relational operator terminates once a complete simple condition is encountered within a complex condition.
![]() The order of evaluation of
the conditions can be prioritized by the use of parentheses (see example
below).
The order of evaluation of
the conditions can be prioritized by the use of parentheses (see example
below).
The interpretation applied to the use of the word "NOT" in an abbreviated combined relation condition is as follows:
Some examples of abbreviated combined and negated combined relation conditions and expanded equivalents follow.
| Abbreviated Combined
Relation Condition |
Expanded Equivalent |
|---|---|
| a > b AND NOT < c OR d |
((a > b) AND (a NOT < c)) OR (a NOT < d) |
| a NOT EQUAL b OR c |
(a NOT EQUAL b) OR (a NOT EQUAL c) |
| NOT a = b OR c |
(NOT (a = b)) OR (a = c) |
| NOT (a GREATER b OR < c) |
NOT ((a GREATER b) OR (a < c)) |
| NOT (a NOT > b AND c AND NOT d |
NOT ((((a NOT > b) AND (a NOT > c)) AND (NOT (a
NOT > d)))) |
| x > a OR y AND z |
x > a OR (x > y AND x > z) |
|
|
x > a OR (x > y AND x > z) |
|
|
(x > a OR x > y) AND x > z |
|
|
x = a OR x > b |
|
|
x = a AND ( x > b OR x < z ) |
| a EQUAL b OR NOT GREATER OR EQUAL c OR d |
(a EQUAL b) OR (NOT (a GREATER OR EQUAL c)) OR (a
GREATER OR EQUAL d) |
| a EQUAL b OR NOT >=c OR d |
(a EQUAL b) OR (NOT (a >= c)) OR (a >= d) |
Parentheses can be used to specify the order in which individual conditions of complex conditions are to be evaluated when it is necessary to depart from the implied evaluation precedence.
Conditions within parentheses are evaluated first, and, within nested parentheses, evaluation proceeds from the least inclusive condition to the most inclusive condition. When parentheses are not used, or parenthesized conditions are at the same level of inclusiveness, the following hierarchical order of logical evaluation is implied until the final truth value is determined:
relation (following the expansion of any abbreviated relation
condition)
class
condition-name
switch-status
sign
In the statement descriptions that follow, several phrases appear frequently: the ROUNDED phrase, the ON SIZE ERROR phrase
![]() the NOT ON SIZE ERROR phrase
the NOT ON SIZE ERROR phrase
and the CORRESPONDING phrase. Each of these phrases is discussed below.
In the following paragraphs, the term "resultant-identifier" refers to that identifier associated with the result of an arithmetic operation.
If, after decimal point alignment, the number of places in the fraction of the result of an arithmetic operation is greater than the number of places provided for the fraction of the resultant-identifier, truncation is relative to the size provided for the resultant-identifier. When rounding is requested, the absolute value of the resultant-identifier is increased by one whenever the most significant digit of the excess is greater than or equal to five.
When the low-order integer positions in a resultant-identifier are represented by the character "P" in the PICTURE for the resultant-identifier, rounding or truncation occurs relative to the rightmost integer position for which storage is allocated.
![]() In a floating-point
arithmetic operation, the
ROUNDED phrase is treated as documentary; the result of a
floating-point operation is always rounded.
In a floating-point
arithmetic operation, the
ROUNDED phrase is treated as documentary; the result of a
floating-point operation is always rounded.
If, after decimal point alignment, the absolute value of a result of an arithmetic operation exceeds the largest value that can be contained in the associated resultant-identifier, a size error condition exists. Division by zero always causes a size error condition. Note that the results of division by zero when no ON SIZE ERROR phrase is specified, are unpredictable. The size error condition applies only to the final results, except in MULTIPLY and DIVIDE statements, in which case the size error condition applies to the intermediate results as well.
![]() Violation of the rules for
the evaluation of exponentiation always terminates the arithmetic
operation and always causes a size error condition.
Violation of the rules for
the evaluation of exponentiation always terminates the arithmetic
operation and always causes a size error condition.
If the ROUNDED phrase is specified, rounding takes place before checking for size error. When such a size error condition occurs, the subsequent action depends on whether or not the SIZE ERROR phrase is specified, as follows:
When a size error condition occurs, the value of those resultant- identifier(s) affected is undefined. Values of resultant-identifier(s) for which no size error condition occurs are unaffected by size errors that occur for other resultant-identifier(s) during execution of this operation.
![]() After completion of the
arithmetic operation, control is transferred to the end of the arithmetic
statement and the NOT ON SIZE phrase, if specified, is ignored.
After completion of the
arithmetic operation, control is transferred to the end of the arithmetic
statement and the NOT ON SIZE phrase, if specified, is ignored.
Results of division by zero, when no ON SIZE ERROR is specified, are unpredictable. You can avoid this by using the CHECKDIV Compiler directive and O run-time switch.
When a size error condition occurs, then the values of resultant- identifier(s) affected by the size errors are not altered. Values of resultant-identifier(s) for which no size error condition occurs are unaffected by size errors that occur for other resultant-identifier(s) during execution of this operation. After completion of the execution of this operation, the imperative statement in the SIZE ERROR phrase is executed.
For the ADD statement with the CORRESPONDING phrase and the SUBTRACT statement with the CORRESPONDING phrase, if any of the individual operations produces a size error condition, the imperative statement in the ON SIZE ERROR phrase is not executed until all of the individual additions or subtractions are completed.
![]() If a size error condition
occurs, any NOT ON SIZE ERROR phrase is ignored whether or not an ON SIZE
ERROR phrase is specified.
If a size error condition
occurs, any NOT ON SIZE ERROR phrase is ignored whether or not an ON SIZE
ERROR phrase is specified.
![]() When both ON SIZE ERROR and
NOT ON SIZE ERROR phrases are specified, and the statement in the phrase
that is executed does not contain any explicit transfer of control, then,
if necessary, an implicit transfer of control is made after execution of
the phrase to the end of the arithmetic statement.
When both ON SIZE ERROR and
NOT ON SIZE ERROR phrases are specified, and the statement in the phrase
that is executed does not contain any explicit transfer of control, then,
if necessary, an implicit transfer of control is made after execution of
the phrase to the end of the arithmetic statement.
If the NOT ON SIZE ERROR phrase is specified for an arithmetic operation statement, and after execution of that statement a size error condition (as defined above) does not exist, then the NOT ON SIZE ERROR phrase is executed. The ON SIZE ERROR phrase, if specified, is ignored, and the imperative statement associated with it is not executed.
In the text that follows, d1 and d2 must each be identifiers that refer to group items. A pair of data items, one from d1 and one from d2 correspond if the following conditions exist:
![]() 78
78
or 88, the USAGE IS INDEX clause or the>
![]() USAGE IS OBJECT
USAGE IS OBJECT
clause.
![]() , USAGE IS
PROCEDURE-POINTER
, USAGE IS
PROCEDURE-POINTER
![]() , USAGE IS POINTER
, USAGE IS POINTER
![]() , or USAGE IS OBJECT
, or USAGE IS OBJECT
clause is ignored, as well as those data items subordinate to the data item that contains the REDEFINES, RENAMES, OCCURS, USAGE IS INDEX
![]() , USAGE IS
PROCEDURE-POINTER
, USAGE IS
PROCEDURE-POINTER
![]() , USAGE IS POINTER
, USAGE IS POINTER
![]() , or USAGE IS OBJECT
, or USAGE IS OBJECT
clause. However, d1 and d2 can have REDEFINES or OCCURS clauses or be subordinate to data items with REDEFINES or OCCURS clauses.
![]() Neither d1 or d2 can be
reference modified.
Neither d1 or d2 can be
reference modified.
The arithmetic statements are the ADD, COMPUTE, DIVIDE, MULTIPLY and SUBTRACT statements. Common features are as follows:
When a sending and a receiving item in a statement share a part of their storage areas,
![]() yet are not defined by the
same data description entry,
yet are not defined by the
same data description entry,
the result of the execution of such a statement is undefined.
![]() Overlapping moves are
detected at compile time only when the MOVE verb is used and neither
operand uses reference modification or subscripting. Forward overlapping
moves result in a warning message, if you set the Compiler
directive WARNING"3". Any other types result in flagging
messages, if you set the Compiler directive
FLAG"dialect", where "dialect" is anything but
OSVS. Other operations resulting in sending and receiving items
sharing the same memory are not detected.
Overlapping moves are
detected at compile time only when the MOVE verb is used and neither
operand uses reference modification or subscripting. Forward overlapping
moves result in a warning message, if you set the Compiler
directive WARNING"3". Any other types result in flagging
messages, if you set the Compiler directive
FLAG"dialect", where "dialect" is anything but
OSVS. Other operations resulting in sending and receiving items
sharing the same memory are not detected.
![]() Although portability of COBOL
source code is only guaranteed when there are no overlapping MOVE
statements, this COBOL system does allow such statements. The behavior of
such statements is sensitive to the BYTE-MODE-MOVE Compiler directive.
Although portability of COBOL
source code is only guaranteed when there are no overlapping MOVE
statements, this COBOL system does allow such statements. The behavior of
such statements is sensitive to the BYTE-MODE-MOVE Compiler directive.
The ADD, COMPUTE, DIVIDE, MULTIPLY and SUBTRACT statements can have multiple results. Such statements behave as though they had been written in the following way:
The result of the statement:
ADD a, b, c TO c, d (c), e
is equivalent to:
ADD a, b, c GIVING temp
ADD temp TO c
ADD temp TO d (c)
ADD temp TO e
and the result of the statement:
MULTIPLY a(i) BY i, a(i)
is equivalent to:
MOVE a(i) to temp
MULTIPLY temp by i
MULTIPLY temp BY a(i)
where temp is an interm
ediate result item provided by your COBOL system.
Except for the class condition (see the section Class Condition in this chapter), when the contents of a data item are referenced in the Procedure Division and the contents of that data item are not compatible with the class specified for that data item by its PICTURE clause
![]() or function definition
or function definition
then the result of such a reference is undefined.
![]() The results of referencing a
numeric field that contains nonnumeric, or otherwise invalid data, are
undefined. Such conditions may be detected, and give an error at run-time.
This behavior is affected by the F run-time switch.
The results of referencing a
numeric field that contains nonnumeric, or otherwise invalid data, are
undefined. Such conditions may be detected, and give an error at run-time.
This behavior is affected by the F run-time switch.
![]() When an alphabetic field
which contains non-alphabetic data is referenced, execution will continue,
but results may be undefined.
When an alphabetic field
which contains non-alphabetic data is referenced, execution will continue,
but results may be undefined.
When the receiving item in an arithmetic statement or a MOVE statement is a signed numeric or a signed numeric edited item, the sign is moved into the receiving item independently of any truncation of the absolute numeric data. It is possible, therefore, for the numeric value to be zero but for the sign to be negative.
The file position indicator identifies the next record to be accessed within a given file during certain input-output sequences. The setting of the file position indicator is affected only by CLOSE, OPEN, START and READ statements. The file position indicator has no effect on files opened in the output or extend mode.
If the FILE STATUS clause is specified in a file control entry, a value is placed into the specified two-character data item during the execution of an OPEN, CLOSE, READ, WRITE, REWRITE, DELETE, UNLOCK or START statement before any applicable USE procedure is executed, to indicate the status of that input-output operation.
The file status keys described in the following pages are for those files which conform fully to the ANSI standard and which use none of the extensions available with this COBOL system.
![]() Use of extensions, for
example, specifying a file as LINE SEQUENTIAL, affects the status keys
returned. Additional information is provided under the relevant verbs.
Use of extensions, for
example, specifying a file as LINE SEQUENTIAL, affects the status keys
returned. Additional information is provided under the relevant verbs.
The leftmost character position of the FILE STATUS data item is known as status key 1 and is set to indicate one of the following conditions upon completion of the input-output operation on a file of any organization.
| "0" | - Successful completion |
| "1" | - At end |
| "2" | - Invalid key |
| "3" | - Permanent error |
|
|
- Logic error |
| "9" | - Run-time system error message |
The meaning of the above conditions is as follows:
The rightmost character position of the FILE STATUS data item is known as status key 2 and is used to further describe the results of the input-output operation.
The combination of status key 1 and status key 2 defines the result of the input-output operation as detailed below:
If status key 1 contains "0" to indicate the successful completion of the input-output operation, status key 2 can contain one of the following values:
| "0" | (all files) No further information is available |
| "2" | (indexed files only) Indicates one of two possibilities:
|
| "4" |
|
| "5" |
|
| "7" |
|
AT END Condition with Unsuccessful Completion
If status key 1 contains "1" to indicate the AT END condition, status key 2 can contain one of the following values:
| "0" | (all files) Indicates that there is no next logical
record. This can be caused by two conditions:
|
| "4" |
|
INVALID KEY Condition with Unsuccessful Completion
If status key 1 contains "2" to indicate INVALID KEY condition, status key 2 indicates the cause of the condition by one of the values:
Permanent Error Condition with Unsuccessful Completion
If status key 1 contains "3" to indicate a permanent error condition, status key 2 can contain one of the following values to indicate the cause of that error:
Logic Error Condition with Unsuccessful Completion
![]()
If status key 1 contains "4" to indicate a logic error condition, status key 2 can contain one of the following values to indicate the cause of that error:
![]()
If status key 1 contains " 9" to indicate a run-time system error message, status key 2 contains the run-time system error message number in binary. These are described in full in your Error Messages.
In the following table: "S" indicates a Record Sequential file
![]() "L " indicates a
Line Sequential file
"L " indicates a
Line Sequential file
"R" indicates a Relative file
"I" indicates an Indexed file.
A particular combination of status key 1 and status key 2 is valid for a given file organization if the letter for that organization is found at the corresponding intersection in Table 10-4.
Table 10-4: Valid Combinations of Status Keys 1 and 2
| Status Key 1 | Status Key 2 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ||
| Successful Completion | 0 | SRIL | I | SRIL | SRIL | S | |||||
| At End | 1 | SRIL | R | ||||||||
| Invalid Key | 2 | I | RI | RI | RI | ||||||
| Permanent Error | 3 | SRIL | SL | SRIL | SRIL | SRIL | SRI | ||||
| Logic Error | 4 | SRIL | SRIL | SRIL | SRIL | SRIL | SRIL | SRIL | SRIL | ||
| Implementor Defined | 9 | Run-Time System Error Message (SRIL) | |||||||||
The AT END condition can occur as a result of the execution of a READ statement. For details of the causes of the condition, see the section The READ Statement later in this chapter.
The INVALID KEY condition can occur as a result of the execution of a START, READ, WRITE, REWRITE or DELETE statement. For details of the causes of the condition, see the sections The START Statement, The READ Statement, The WRITE Statement, The REWRITE Statement, and The DELETE Statement later in this chapter.
If the INVALID KEY condition exists after the execution of the input-output operation specified in an input-output statement, the following actions occur in the order shown:
When the INVALID KEY condition occurs, execution of the input-output statement which recognized the condition is unsuccessful, and the file is not affected.
Note that INVALID KEY does not trap errors when status key 1 is set to "9". Such errors must be trapped either by explicitly testing the status key or by using declaratives instead of the INVALID KEY clause.
The run-time system (RTS) supports this COBOL system's multi-user facilities which allow files to be shared between users in a multi-user environment, and allow runtime elements accessing those files to prevent access to records or entire files while data is being updated.
In single-user environments the multi-user syntax has no effect at run time, but runtime elements can be developed for use in both single- and multi-user environments.
Files are either active or inactive. An active file is open to one or more run-units. An inactive file is one that is not open to any run-unit.
Active files can be open in one of two modes: exclusive or shareable.
![]()
A file which is in exclusive mode is open to one run unit only; any other run-unit which attempts to access it will receive a "File locked" error and be denied access. Exclusive mode implies that a file lock is held by the one run unit which is able to access the file; the file lock is released by that run unit closing the file.
A file which is in shareable mode is available to any number of run units, each of which can protect data while using the file by locking one or more records at a time in the file. This prevents other run units from acquiring a lock on the individual records that are locked, but does not prevent access to the file otherwise. The organization of the file affects the way the file can be shared.
Record sequential files opened for INPUT can be shared between run units but records cannot be locked in the file. Files opened for I/O or EXTEND can also be made shareable and each run unit can maintain a record lock for the file. Files opened for OUTPUT always have an exclusive file lock.
Line sequential files that are opened INPUT or EXTEND can be made shareable but records cannot be locked in the file. Files that are opened OUTPUT always have an exclusive file lock.
Files that are opened in INPUT mode are shareable, but records cannot be locked in the file. Files that are opened I/O can be shareable but files that are opened OUTPUT or EXTEND are exclusive.
Each run unit that is sharing access to a file can be locking either a single record or multiple records in that file. A run unit cannot select single record locking and multiple record locking for the same file.
A run unit that has specified single record locking for a file (either explicitly or implicitly) can hold only one record lock in that file at any one time. A run unit can acquire a record lock in two ways: manually or automatically.
The run unit acquires a lock only if it accesses a record with a READ WITH LOCK statement.
The run unit acquires a lock whenever it reads a record in the file, unless you specify the READ WITH NO LOCK statement.
The lock is released by the same run unit:
Locking of multiple records in a file is available only when the organization of that file is relative, indexed or record sequential.
A run unit that has specified multiple record locking for a file can hold a number of record locks in one file simultaneously. This prevents other run units from updating or acquiring a lock on those locked records, but does not deny them access to any records that are not locked. Record locks can be acquired in two ways: manually or automatically.
The run unit acquires a lock only if it accesses a record with a READ WITH LOCK or READ WITH KEPT LOCK statement.
The run unit acquires a lock whenever it reads a record in the file unless you explicitly specify that it should not. If the WRITELOCK Compiler directive has been specified at the time the compilation group was submitted to your COBOL system, then a lock is acquired if the run unit accesses the file with a WRITE or REWRITE statement.
The locks are released by the same run unit:
Tables 10-5, 10-6 and 10-7 show the default type of
locking which is used when files are opened in a particular open
mode. The defa
ult locking can be modified if the
AUTOLOCK Compiler
directive was specified at the time the compilation group was
submitted to your COBOL system. The tables also indicate whether the
default type of locking can be overridden for individual files. This is
done by inserting a suitable clause in the SELECT statement for the file.
(See section The SELECT Statement later in this chapter for
details of the required syntax.)
![]() X/Open restricts those X/Open
conforming source programs that use locking to either single record locks
with automatic locking, or multiple record locks with manual locking.
X/Open restricts those X/Open
conforming source programs that use locking to either single record locks
with automatic locking, or multiple record locks with manual locking.
Table 10-5: Default Locking For Record Sequential Files
| OPEN Mode | No Directive | AUTOLOCK Compiler Directive |
Override in SELECT Statement |
| INPUT | No lock | No lock | Yes, but only to Exclusive |
| I/O | Exclusive | Lock on single record | Yes |
| OUTPUT | Exclusive | Exclusive | No |
| EXTEND | Exclusive | No lock | Yes, the file can be made shareable but no records are locked |
Table 10-6: Default Lo cking For Line Sequential Files
| OPEN Mode | No Directive | AUTOLOCK Compiler Directive |
Override in SELECT Statement |
| INPUT | No lock | No lock | No |
| I/O | Exclusive | No lock | No |
| OUTPUT | Exclusive | Exclusive | No |
| EXTEND | Exclusive | No lock | No |
Table 10-7: Default Locking For Relative And Indexed Files
| OPEN Mode | No Directive | AUTOLOCK Compiler Directive |
Override in SELECT Statement |
| INPUT | No lock | No lock | Yes, but only to Exclusive |
| I/O | Exclusive | Automatic lock on single record | Yes |
| OUTPUT | Exclusive | Exclusive | No |
| EXTEND | Exclusive | Exclusive | No |
Notes:
The number of arguments in the activating unit shall be equal to the number of formal parameters in the activated unit.
![]() If the numbers of operands
are different, then if there are more operands in the activating
statement, they are ignored and if there are more operands in the
Procedure Division header, they must not be referenced within the
activated runtime element. The positional correspondence may vary
depending on the non-COBOL calling conventions implied by mnemonic-name.
Any mismatch in the number of the operands will only be apparent at run
time and so the directive FLAG will not cause this extension to be
flagged.
If the numbers of operands
are different, then if there are more operands in the activating
statement, they are ignored and if there are more operands in the
Procedure Division header, they must not be referenced within the
activated runtime element. The positional correspondence may vary
depending on the non-COBOL calling conventions implied by mnemonic-name.
Any mismatch in the number of the operands will only be apparent at run
time and so the directive FLAG will not cause this extension to be
flagged.
The rules for conformance between arguments and formal parameters depend on whether either the formal parameter or its corresponding argument is a group item or both are elementary items.
If either the formal parameter or the argument is a group item, the corresponding argument or formal parameter shall be a group item or an elementary item of category alphanumeric, and the formal parameter shall be described with the same number or a smaller number of character positions as the corresponding argument.
The conformance rules for elementary items depend on whether the argument is passed by reference, by content, or by value.
If either the formal parameter or the corresponding argument is an object reference, the corresponding argument or formal parameter shall be an object reference following these rules:
If either the argument or the formal parameter is of class pointer, the corresponding formal parameter or argument shall be of class pointer and the corresponding items shall be of the same category. The ADDRESS special register is considered to be of class pointer and category data-pointer.
If neither the formal parameter nor the argument is of class object or pointer, the conformance rules are the following:
If the formal parameter is of class object or pointer, the conformance rules shall be the same as if a SET statement were performed in the activating runtime element with the argument as the sending operand and the corresponding formal parameter as the receiving operand.
If the formal parameter is not of class object or pointer, the conformance rules are the following:
A returning item shall be specified in the activating statement, if and
only if a returning item is specified in the procedure division header
![]() or ENTRY statement
or ENTRY statement
of the activated source element.
The returning item in the activated source element is the sending operand, the corresponding returning item in the activating source element is the receiving operand.
If either the sending or the receiving operand is a group item, the corresponding returning item shall be a group item or an elementary item of category alphanumeric, and the receiving operand shall be described with the same number of character positions as the sending operand.
If either of the operands is an object reference, the corresponding item shall be an object reference, and the following rules shall apply:
If the sending operand is not an object reference, the receiving operand shall have the same PICTURE, USAGE, SIGN, SYNCHRONIZED, JUSTIFIED, and BLANK clauses, with the following exceptions:
Copyright © 2000 MERANT International Limited. All rights reserved.
This document and the proprietary marks and names
used herein are protected by international law.
| Data Division - Screen Section | Procedure Division - Intrinsic Functions | |