

| State Maintenance Library Routines | Deploying Internet Programs Created on NetExpress | |
In just a very short period of time, the Worldwide Web (WWW) has changed how we think about computing. New companies and new products arise almost overnight changing the computing landscape. Yet the interactivity made possible by the Web has been around for quite some time.
The origins of the Web can be traced to research projects sponsored the US Government in the 1960s and 70s to build a network infrastructure capable of withstanding any number of possible disasters. The result was a loosely-coupled network of computers called the Internet.
The Internet was unique in that it didn't have one centralized host nor did it rely on predefined connection paths to move information. The genius of the Internet was that packets of information "found their own way" through the network from source to destination. The result was a network that would continue to function despite the failure of one or more nodes.
Throughout the 1980s and early 90s the Internet was used primarily by large corporations and universities for e-mail and document transfer. However, it wasn't until the development of Web browsers and a language called HTML that things really took off. HTML (Hyper Text Markup Language) was developed by Tim Berners-Lee while he worked as a researcher in Switzerland. The original intent of HTML was to provide a quick and easy way to facilitate information transfer among scientists. The basic idea behind HTML is the insertion of tags (for example <EM>) within plain ASCII text and the interpretation of those tags by a software program called a browser.
Figure A-1: Web Server and Web Browser
The first graphical browser, Mosaic, became an instant success. Users were able to view text and graphics located on other computers by clicking on specially highlighted words or links. The low overhead and simplicity of HTML led to its quick acceptance by Internet users everywhere. The result is what we see today - a simple data transfer protocol, sitting on top of a robust, fault-tolerant network infrastructure - the World Wide Web.
For many individuals, surfing the Web has become part of everyday life. Corporations are moving to quickly establish a Web presence to take advantage of what the Web can provide in terms of advertising, multimedia and electronic commerce. As a result, the Web has not only changed how we think about information transfer and data lookup but is changing how organizations do business. Two recent extensions of the basic ideas behind the Web are the intranet and extranet.
While the Internet has captured media and public attention, internal Internets, or intranets, are growing as companies look for new ways to disseminate information and applications within corporations. Through the use of firewalls, software that keeps outsiders from accessing company data, intranets are being used for company-wide information distribution, keeping employees up-to-date on everything from corporate leave policies to enterprise-critical planning. Intranets, just like the Internet, use Web browsers sitting on PCs or workstations connected to company servers.
Web browsers have the advantage that text, graphics, audio or video can be displayed without any programming effort. Browsers now come multimedia-ready, capable of displaying different standard file formats. For corporations looking to improve the way they do business, the Web is an effective vehicle for improving scheduling, report distribution, conferencing, or any activity that involves managing the extraordinary flow of information that is generated internally and externally on a daily basis across a variety of technical platforms.
Many companies have already developed intranets and are now expanding their reach to include selected sites outside the company. The new network structure known as an extranet extends an intranet to include sites integral to enterprise operations. For example, a manufacturing company may want to expand its intranet to include suppliers of critical goods and materials, making information from those suppliers available to corporate planners. GE, for example, is creating its own application called Trading Process Network (TPN) where qualified subcontractors can search GE databases and submit bids via secure links to GE's intranet Web servers. Web connections make this possible, opening up new ways for companies to meet customer needs.
The Web has forced a rethinking of traditional client-server computing. In the 1960s and 1970s, corporate information resources were housed in mainframes that talked to dumb terminals used primarily for data capture and display. As PC's and desktop platforms grew in power, local area networks (LANs) made it possible to partition applications, taking some of the burden off centralized mainframe servers.
The result was a client-server model of computing that distributed processing among powerful clients. Because client platforms required more memory and disk space to carry out their responsibilities, they became known as fat clients, distinguishing them from the earlier generation of dumb or thin clients that served only for display and data entry.
In the past, IS managers had to be careful about the kinds of platforms deploying client-server applications within an organization since application portability was always an issue. Today, with the move to fully networked environments, the functionality that matters is the functionality that can be shared with partners, colleagues and customers independent of platform.
One direct result of the new network-centric view of client-server computing is the resurrection of the mainframe as an important corporate resource. In a thinner-client world where both data and programs can be delivered from the server, it is important to have servers with horsepower, and that typically involves mainframes.
Although the Web browser-to-server connection may appear on the surface as a traditional client-server connection, the Web adds a new twist since any Web browser can connect to any Web server - anywhere in the world! This broadening of the traditional meaning of client-server has generated tremendous excitement in the computing world since applications can transcend their conventional bounds whether it be limitation by Ethernet LAN or SNA connection. It also means an opportunity to leverage the millions of lines of COBOL that sits at the heart of many corporations.
For organizations with COBOL applications and COBOL programmers, the Web opens up a wide range of new options and opportunities. For legacy applications, the Web means that COBOL programs can take on new life by adding Web connections through simple COBOL statements. It also means that COBOL programmers can use COBOL to program the connections between important enterprise applications, data and the rest of the world. The implication for COBOL is significant. The value of legacy COBOL applications goes up, particularly with Server Express's built in features for accepting and displaying information on the Web.
Server Express also opens up a new role for COBOL as a language for writing Web server applications. What is more natural for a language that has been the workhorse for mainframe applications for over thirty years? Thus, rather than risking rewrites of existing COBOL applications in new languages, legacy programs can be extended and made Web-ready through Server Express's built-in Web access languages features. However, before looking at how Server Express does this, let's look at the how information is transferred back and forth between a Web browser and a Web server.
The basic principle behind the Web is simple. Programs known as Web browsers (such as Netscape Navigator and Microsoft Internet Explorer) located on one computer request Web pages from Web servers.
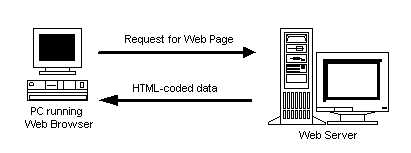
Figure A-1: A Web Browser Talking to a Web Server
Requests for Web pages result in documents being transferred from the Web server to the client Web browser. We can think of the Worldwide Web (WWW) as consisting of the following components:
Web Browsers such as Netscape or Microsoft Internet Explorer are software programs that allow you to display Web pages on your computer screen. Users of Web browsers generally type in phrases such as http://www.w3c.org to view Web pages received from remote computer sites. In order to use a Web browser, your computer must be connected to the Internet. This requires a modem or other network connection.
Web sites are computer systems maintained by organizations or individuals who make their Web pages available for downloading by a Web browser. Individuals visit Web sites. Web sites are categorized as commercial, government or educational. You can tell the kind of Web site you are connecting to by examining its extension; for example:
| Entity
|
Extension
|
Full Web Site Name
|
|---|---|---|
| Corporate | com | http://www.merant.com |
| Government | gov | http://www.whitehouse.gov |
| Educational | edu | http://www.seas.smu.edu |
| UK company | co.uk | http://www.merant.co.uk |
Web documents are files that reside on a Web site for download by a Web browser. Web documents usually contain links to other documents on the Web. Users clicking on a link connect to either the same or different Web sites to view other Web documents. Moving from document to document via Web links is commonly known as web-surfing.
Web servers are software applications running on Web sites that handle requests from Web browsers. Servers "serve up" Web pages to a Web browser. Web server software returns Web pages (including pictures, audio and possibly video), encoded in HTML, back to their Web browser clients. More importantly, Web servers can capture information from users and start up other server-resident programs. This opens the door to accessing corporate databases and legacy COBOL applications from the Web.
Software that accepts and handles requests from a Web server on behalf of a user. Because Server Express supports the Web standard CGI, the Common Gateway Interface, COBOL can be used to write Web gateway programs. Gateway programs open up the door to providing flexible responses to user requests. Gateway programs can create dynamic Web pages on-the-fly as well as query databases and package results for a user.
Web browsers such as Netscape Navigator and Microsoft Internet Explorer allow users to view Web pages transferred to their computers from Web servers. While the look of different Web browsers may vary, they all share the ability to display Web resources - files of information that reside on a Web server. The exciting thing about the Web is that the files are not limited to text but can include graphics, sound, animation, video and even virtual reality, making the Web a truly universal platform for distributing many different kinds of information. In fact, Web browsers not only let you view Web pages but also have built-in support for Email, connecting to Usenet discussion groups, and downloading load files via ftp (file transfer protocol). The secret to all of this is the URL.
Computers on the Internet use the Uniform Resource Locator (URL) to make a connection between a Web browser and the target Web server. The URL is the address of a file. This address is in a format that can be interpreted by a Web server, which then retrieves the file. A URL can contain a filename, a bookmark to a specific location in the file, a server on which the file resides, and a scheme that tells how the file is to be retrieved.
Each Web site has its own net address which is embedded in a URL. For example, the Microsoft Web address is www.microsoft.com and when embedded in a URL appears as:
http://www.microsoft.com
Typing in the above name at the top of Web browser will take you to the main Micro Focus home page. While URLs often correspond to company names, they do not have to.
Sometimes you will see URLs with more than one item after the company address. For example:
http://www.w3.org/
In addition to connecting to company home pages, URLs can also be used to connect to individual documents stored on a Web server. Clicking on Web page links often takes you to specific documents within subdirectories at Web server locations. By typing in the full URL name in a Web browser you can go directly to a document without having to navigate links. For example, the URL:
http://www.w3.org/cgi
will take you to a specific document on the W3C's server that gives links to descriptions, specifications and discussion of the CGI interface.
URLs are based on the following general format:
protocol://hostComputer/path:port
The following sections explain each of the component parts of a URL.
A protocol is a set of rules for communication between two entities. The Department of State maintains a protocol book for how to communicate with dignitaries of foreign countries. Protocols for computer-to-computer interaction serve a similar purpose: to define the rules for transmitting and receiving data.
The most common protocol on the Web is HTTP, the Hypertext Transfer Protocol. HTTP specifies the rules for communication between a Web browser (client) and a Web server. Although HTTP is the mostly widely used protocol, it is not the only protocol used on the Web. Other protocols include FTP (File Transfer Protocol) for transferring data and program files across the Web, gopher for transferring menus of files and mailto for e-mail.
Following the protocol name and the two forward slashes (//) is the name of the host computer. For example, the name www.microsoft.com is the host computer, commonly referred to as the domain name of the Web server. Domain names can be read from right to left as follows:
Actually, as the request goes out from a Web browser onto the Web, the text domain name is converted into a numeric IP (Internet Protocol) address that is used to locate the Web site. The Internet Protocol is the basis for computer to computer communication across the Internet, and is part of a lower level communication protocol known as TCP/IP. Each IP address consists of four numbers separated, in groups of three, by periods.
Any text after the host computer name is interpreted as the path name of the document to be retrieved. If no path is specified, the HTTP default is to search for a directory named public_html and a file called index.html.
When you connect to a Web server from your Web browser you can perform several Web activities at once. For example, you can download a Web page, transfer a file using ftp and check Email, all from the same server. To keep things straight, the server uses different ports for different activities. To make life easy for users, there are default ports for different protocol-based connections. Thus when entering the URL:
http://www.w3.org
a port number of 80 assumed. Sometimes however, you may need to specify port numbers in your URL. Port numbers appear as part of the host computer name and are preceded by a colon as in:
http://www.w3.org:80
| Protocol
|
Description
|
URL Format
|
|---|---|---|
| FTP | Transfer files from one machine to another | ftp://user:password@host/pathname |
| Gopher | List the directory structure of a remote computer | gopher://host/pathname |
| HTTP | Transfer Web documents | http://host/path |
| Mailto | Send Internet mail | mailto:name@hostcomputer |
| News | Read USENET newsgroups | news:newsgroup |
| Telnet | Connect to another computer | telnet://user:password@host/pathname |
The most common Internet protocol is HTTP which is an abbreviation for HyperText Transfer Protocol. The basis for HTTP is HTML, the HyperText Markup Language.
For every Web page you see, there is a text file coded with HTML tags in the background. In fact, it is ASCII text with tags that is sent from Web server to Web browser. The job of the Web browser is to interpret the tags and draw a Web page based on the tags and the text.
HTML has codes for headings, lists, forms and other elements of a Web page. It is important to realize that HTML does not specify how a Web browser is to format the display. HTML merely states the fact that portions of a document are headings, text, lists or forms. It is up to the Web browser to interpret the HTML and provide the display. This greatly simplifies the data transfer between Web servers and Web browsers. It also means, however, that pages may display differently on different browsers. Thus, it is important that Web page developers view their pages on different browsers to make certain no unwelcome surprises occur.
HTML tags are embedding tags within a Web document. When a Web browser sees a tag, it interprets that tag and supplies a format. For example, the HTML tag <EM> indicates that subsequent text should have emphasis. However, how emphasis is provided is browser-dependent. Some browsers may emphasize the text with italics, others as bold text and others with color. Again, this underscores the fact that different browsers should be used to test one's Web pages.
The HTML tags within the text of a HTML document provide information to a browser about the structure and form of a page. The following summarizes some of the more common HTML tags.
| <HTML>...</HTML> | Encloses the entire HTML document |
| <HEAD>...</HEAD> | Defines the Header of the HTML document |
| <BODY>...</BODY> | Defines the Body of the HTML document |
| <TITLE>...</TITLE> | Defines document title |
| <H1> | First level heading |
| <H2> | Second level heading |
| <P>...</P> | Defines begin and end of a paragraph |
| <OL>...</OL> | Begin/End of ordered (numbered) list |
| <UL>...</UL> | Begin/End of bulleted list |
| <MENU>...</MENU> | Begin/End of menu list of items |
| <LI> | List element used with <OL>, <UL> or <MENU> |
| <OL>...</OL> | Begin/End of ordered (numbered) list |
| <UL>...</UL> | Begin/End of bulleted list |
| <FORM>...</FORM> | HTML form into which users can insert information |
| <INPUT>...</INPUT> | Form objects (text boxes, check boxes, radio buttons, submit buttons) are represented by INPUT elements. The TYPE attribute determines what type of object to display. For example, if TYPE has the value TEXT (this is the default), a text box is generated. |
| <SELECT>...</SELECT> | Specifies list boxes and drop-down lists. |
| <OPTION>...</OPTION> | Specifies each item in the drop-down list specified by SELECT. |
Web browsers open the door to the display of various kinds of multimedia. Web browsers are now able to display many different kinds of information including text, graphics, video, audio and even virtual reality. Web browsers are able to support different multimedia formats through the use of plug-ins and add-ons that tell the browser how to display the different kinds of standard files that may be sent from Web servers.
For example, Web designers can add graphic elements to a Web page by including an HTML tag for images <IMG... > and an internal code that specifies the file name that holds the image. For example:
<IMG SRC="mypicture.gif">
loads the image contained in the file mypicture.gif from the Web server for display in the Web browser.
The following sections provide a brief overview of the kinds of standard multimedia components that one can use in Internet, intranet or extranet applications.
The most common graphic images that are used on the Web are GIF (Graphics Interchange Format) and JPEG (Joint Photographic Experts Group). GIF files support up to 256 colors and are best suited for simple graphics and drawings. JPEG files support over a million colors through the use of 24-bit graphics and are appropriate for photographic images.
Web audio is based on 8 bit sampling which is good for voice and low quality music. Common audio file formats are .wav and .au so it is useful to have your browser configured to handle these files.
Web video is often in MPEG (Motion Pictures Expert Group) format, Apple's QuickTime or Intel's Indeo format. Both QuickTime and Indeo support synchronized audio and video.
One method of Web-based animation, the combination of moving images and audio, is possible through the use of small programs called applets that can be downloaded from Web sites. Applets are written in the new Java programming language developed by Sun Microsystems. The more recent browsers have the capability of running Java applets.
Three dimensional shapes and landscapes can be transferred from Web servers to Web browsers through the use of VRML (Virtual Reality Modeling Language) formatted files. VRML is seen as having the potential to open doors to new ways of modeling and displaying data.
While Web browsers support the display of a mix of text, graphics, sound and video, much excitement about the Web has been generated by Java, the new programming language for Internet applications developed at Sun Microsystems. Programs written in Java are compiled into an intermediate byte-code representation and shipped to Web browsers. The Web browser then interprets the byte-coded program and runs it on the client's machine.
The advantage of this approach is that applications, or applets, written in Java are accessible to any platform with a Java-enabled browser. The underlying operating system and hardware is irrelevant. The reason that corporations are so excited about this technology is that it provides a simple, easy way to distribute software and documentation over the Web.
Until recently, the Web was a static medium. Documents, stored on servers, were downloaded to Web Browsers for passive viewing. However, it is now possible to obtain information directly from Web users via HTML Forms. Forms work by packaging user supplied information within the http://message. This information, when arriving at the server, can be used to trigger other programs on the server. The key to making this happen is CGI, the Common Gateway Interface.
CGI or Common Gateway Interface is a standard interface, supported by all Web servers, that allows information to be passed between Web browsers and Wed servers. Programs on the server that understand the CGI specification can retrieve information from users running Web browsers and incorporate database or legacy application connections to build dynamic Web pages tailored specifically to meet the needs of users.
The Common Gateway Interface (CGI) has revolutionized our conception of clients and servers. CGI-based gateway programs open the door to the Web as a universal network for applications. With potential clients all over the world, CGI-savvy programs can send forms to users, accept input, use that input to search databases or begin transactions, and then download screens of data appropriate to the user's requests.
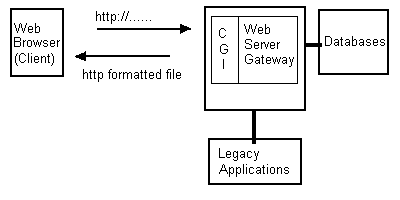
Figure A-2: The Web Server as Gateway
One of the most important features of Server Express is its ability to open up Web programming to the COBOL programmer. Until Server Express, CGI programming meant two things. First, one had to learn the details of the CGI interface specification. And second, one had to master a new language in order to parse the URL string that came in from the Web browser. PERL, a rather cryptic language for string parsing, is currently one of the more popular languages for deciphering incoming URLs and data streams.
Yet, while PERL is a popular language for building Web server programs, it has major drawbacks. Languages such as PERL do not integrate well with existing COBOL programs nor do they leverage the skill of COBOL programmers or COBOL's preeminence as a data manipulation language.
Server Express takes COBOL's data manipulation capability to new heights by hiding the complexity of CGI, while making Web programming as easy as manipulating familiar COBOL record structures. Server Express accomplishes this by introducing one new clause, External-Form, and by extending the syntax of the COBOL verbs, ACCEPT and DISPLAY. COBOL programmers familiar with ACCEPT can simply ACCEPT data from a HTML form into a predefined data record. Similarly, the familiar DISPLAY statement is used to map data elements from a COBOL program directly to client Web pages.
This is important for several reasons:
if ($address =~ /^\d+\s+(\w+)St\.$/) {
print ìYou live on $1.\nî;
With Server Express, all the power of mainframe legacy applications is now accessible from Web clients. Remember, the gateway program that talks to Web browsers is a COBOL program - a COBOL program that itself can talk to other programs, databases or transaction monitors.
The CGI standard is described at http://www.w3.org/cgi
There is a vast array of books available on all aspects of the World Wide Web, the Internet and intranets, ranging from simple to very detailed. For more information, visit your nearest bookstore and browse what is available. There are five main areas that you should consider: General Internet, HTML, CGI, ActiveX and JavaScript. Books on CGI programming should include an explanation of the concepts of CGI, and help you understand how to design your applications. You probably won't need to understand much about JavaScript.
For example, the Special Edition series published by Que contain the titles Using the Internet, Using HTML, Using CGI and Using ActiveX.
For JavaScript, look at Teach Yourself JavaScript in a Week published by SAMS, and JavaScript Unleashed.
There are several sites on the Internet that contain useful information about the Internet, World Wide Web and intranets. Those below are a representative selection:
| CGI | CGI Primer |
| Cookies | Cookie Specification |
| JavaScript | Netscape JavaScript Authoring Guide |
| JScript | Microsoft JScript Authoring Documentation |
| NSAPI | Netscape Server APIs (NSAPIS) 2.0 |
| SQL | SQL Tutorial |
Copyright © 1999 MERANT International Limited. All rights reserved.
This document and the proprietary marks and names
used herein are protected by international law.
| State Maintenance Library Routines | Deploying Internet Programs Created on NetExpress | |