7.1 Understanding collector templates for identity sources
Identity collectors populate the catalog with identities and group data. Identities are at the core of the functions of OpenText Identity Governance. All collectors share some common elements and features. In addition, identity collectors also include identity specific collector views and publication behavior settings.
7.1.2 Understanding publication behavior
When you create an identity source, you can specify a publication option. The catalog contains data collected from multiple data sources. To create a unified identity for each person, you need to merge, or unify, the different sets of collected information. Merging occurs during the publication process. For each identity source, you can specify one of the following publication option:
- Publish and merge
-
Use this option when you collect data for the same identity from different data sources. For example, both Active Directory and Salesforce.com have the same first_name and last_name attributes for Jane Smith. This option allows you to combine the duplicate attributes from the sources into one identity for Jane in the OpenText Identity Governance catalog.
When identity sources are merged to create combined published users, there are scenarios where a user collected from an identity source will not merge with a user from another identity source. By default, OpenText Identity Governance will create a new user when it cannot merge a collected user with an existing user. However, there are some identity sources where it is not desirable for a new user to be created. These identity sources are only intended to add information to existing users, and are not meant to create new users. You can specify whether a merged identity source should be allowed to create new users, or must always merge with a user collected from another identity source by enabling or disabling .
When you edit the configuration of a publish and merge collector, the schema mapping user interface presents a check box next to each attribute mapping row. You must select at least one matching attribute before you can save the configuration. By specifying the matching attribute you can merge the collected data from an identity source to the existing data. For example, the Workfore ID is used as the matching attribute to map EmployeeNumber to Workforce ID and Last Name to LastName.
Figure 7-1 Attribute matching
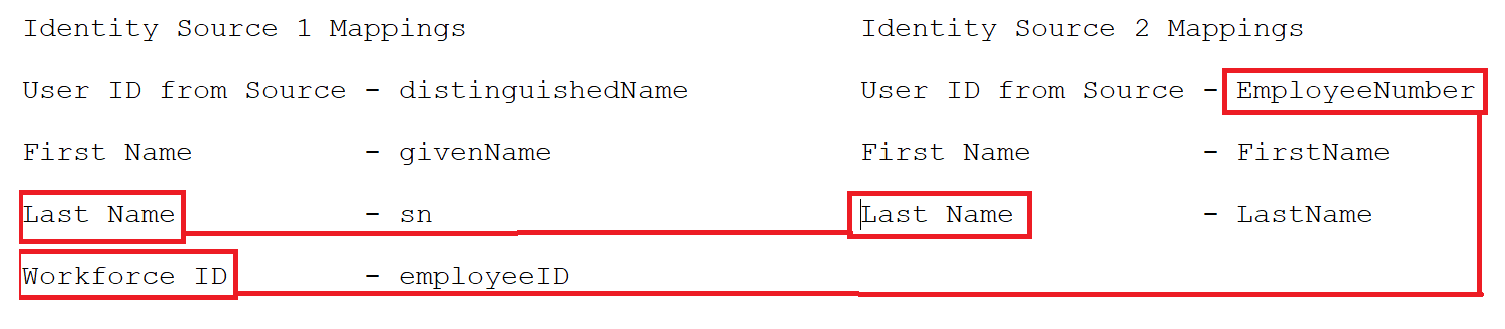
NOTE:You must specify unique values for the attributes you want to match during merging. In addition, do not use an empty (null) value as a matching attribute value. If a matching attribute has a null value, the record from the second source is discarded.
You must also specify the rules for merging. Only one of your data sources can be an authoritative source for each identity attribute. To help you specify the attribute authority, OpenText Identity Governance numbers the data sources within each collection. The first source listed becomes the default authoritative source for all attributes in the collection. However, you can reorder the priority of the data sources or override the default setting for specific attributes. For more information, see Section 9.1, Publishing identity sources.
- Publish without merging
-
Use this option if you have only one identity source or your data sources do not contain the same identities. Since OpenText Identity Governance does not perform any merging activities during publication, you might observe faster performance. However, if your sources do contain the same identity, OpenText Identity Governance will treat those identities as separate people.
- Do not publish
-
Use this option when you are configuring the identity source. For example, you might not want to publish any collected data when you are testing the process.