The REPLACE Statement
General Formats for Format 1
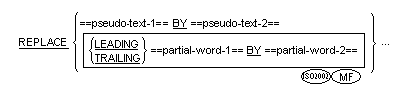
General Formats for Format 2
Syntax Rules
- A REPLACE statement can be specified anywhere in source text or in library text that a character-string or a separator, other than the closing delimiter of a literal, can appear. It must be preceded by a separator space except when it is the first statement in a compilation group.
- A REPLACE statement must be terminated by a separator period.
- Pseudo-text-1 must contain one or more text-words.
- Pseudo-text-2 can contain zero, one, or more text-words.
- Character-strings within pseudo-text-1 and pseudo-text-2 can be continued.
- A text-word within pseudo-text must be between 1 and 322 characters long.
- Pseudo-text-1 must not consist entirely of a separator comma or a separator semicolon.
- If the word REPLACE appears in a comment-entry or in the place where a comment-entry can appear, it is considered part of the comment-entry.

 Partial-word-1 must consist of one text-word.
Partial-word-1 must consist of one text-word.
- Partial-word-2 must consist of zero or one text-word.
- Neither a nonnumeric literal nor a national literal can be specified as partial-word-1 or partial-word-2.
General Rules
- Pseudo-text-1 specifies the source text to be replaced by pseudo-text-2.
- Partial-word-1 specifies the text to be replaced by partial-word-2.
- The Format 2 REPLACE statement specifies that any text replacement currently in effect is discontinued.
- A given occurrence of the REPLACE statement is in effect from the point at which it is specified until the next occurrence of the REPLACE statement or the end of the compilation unit, respectively.
- Any REPLACE statements contained in a source unit are processed after the processing of any COPY statements contained in that source unit.
- The text produced as a result of the processing of a REPLACE statement must contain neither a COPY statement nor a REPLACE statement.
- The comparison operation to determine text replacement begins with the text immediately following the REPLACE statement and
occurs in the following manner:
- Starting with the leftmost source text-word and the first pseudo-text-1 or partial-word-1, pseudo-text-1 or partial-word-1 is compared to an equivalent number of contiguous source text-words.
- Pseudo-text-1 matches the source text if, and only if, the order sequence of text-words that forms pseudo-text-1 is equal,
character for character, to the ordered sequence of source text-words.
When the LEADING phrase is specified, partial-word-1 matches the source text-word only if the contiguous sequence of characters
that forms partial-word-1 is equal, character for character, to an equal number of contiguous characters starting with the
leftmost character position of that source text-word. When the TRAILING phrase is specified, partial-word-1 matches the source
text-word only if the contiguous sequence of characters that forms partial-word-1 is equal, character for character, to an
equal number of contiguous characters, ending with the rightmost character position of that source text-word.
- The following rules apply for the purpose of matching:
- Each occurrence of a separator comma, semicolon, or space in pseudo-text-1 or in the source text is considered to be a single space. Each sequence of one or more space separators is considered to be a single space.
- Except when used in nonnumeric or national literals, each lower-case letter is equivalent to the corresponding upper-case letter as specified for the COBOL character set.
- text-words within a debugging line participate in the matching as if the "D" did not appear in the indicator area.
 Each operand and operator of a concatenation expression is a separate text-word.
Each operand and operator of a concatenation expression is a separate text-word.
- If no match occurs, the comparison is repeated with each next successive occurrence of pseudo-text-1 or partial-word-1, until either a match is found or there is no next successive occurrence of pseudo-text-1 or partial-word-1.
- When all occurrences of pseudo-text-1 or partial-word-1 have been compared and no match has occurred, the next successive source text-word is then considered as the leftmost source text-word, and the comparison cycle starts again with the first occurrence of pseudo-text-1 or partial-word-1.
- Whenever a match occurs between pseudo-text-1 and the source text, the corresponding pseudo-text-2 replaces the matched text
in the source text.
When a match occurs between partial-word-1 and the source text-word, the matched characters of that source text-word are either
replaced by partial-word-2 or deleted when partial-word-2 consists of zero text-words.
The source text-word immediately following the rightmost text-word that participated in the match is then considered as the leftmost source text-word. The comparison cycle starts again with the first occurrence of pseudo-text-1 or partial-word-1.
- The comparison operation continues until the rightmost text-word in the source text which is within the scope of the REPLACE statement has either participated in a match or been considered as a leftmost source text-word and participated in a complete comparison cycle.
- Comment lines or blank lines occurring in either the source text or pseudo-text-1 are ignored for purposes of matching; and the sequence of text-words in the source text and in pseudo-text-1 is determined by the rules for reference format. See the topic Reference Format Representation in the chapter Language Fundamentals. Comment lines or blank lines in pseudo-text-2 are placed into the resultant source text unchanged whenever pseudo-text-2 is placed into the source text as a result of text replacement. A comment line or blank line in source text is not placed into the resultant source text if that comment line or blank line appears within the sequence of text-words that match pseudo-text-1.
- Only after all COPY and REPLACE statements have been completely processed, can the syntactical correctness of the rest of the source code be determined.
- text-words inserted into the source text as a result of processing a REPLACE statement are placed in the source text according to the rules for reference format. See the topic Reference Format in the chapter Language Fundamentals. When inserting text-words of pseudo-text-2 into the source text, additional spaces can be introduced only between text-words where a space (including the assumed space between source lines) already exists.
- If additional lines are introduced into the source text as a result of the processing of REPLACE statements, the indicator
area of the introduced lines contains the same character as the line on which the text being replaced begins, unless that
line contains a hyphen, in which case the introduced line contains a space.
If any literal within pseudo-text-2 is of a length too great to be accommodated on a single line without continuation to another line in the resultant source text and the literal is not being placed on a debugging line, additional continuation lines are introduced to contain the remainder of the literal. If replacement requires the continued literal to be continued on a debugging line, the compilation unit is in error.
- The source text for which a REPLACE statement is in effect must not contain an EXEC HTML statement. Violation of this rule
may result in unexpected behavior and syntax errors.