Chapter 6: Span
This chapter describes the Databridge Span Accessory and how to use it.
How Span Works
The Span Accessory provides host-based replication of a DMSII database. Use Span to create data files that contain copies of DMSII database records. This approach is useful when a network is not available for a Databridge server-client relationship or when a Databridge Client does not exist for a particular client system.
When Span requests updates for data sets that have not been cloned, the Databridge Engine (DBEngine) initiates a routine to extract all of the records for the uncloned data sets from the DMSII database. DBEngine returns these records to Span as if they were newly-created records. DBEngine also forwards any additional changes that occurred to these records during the extraction. (This extraction may include duplicate records or other anomalies.)
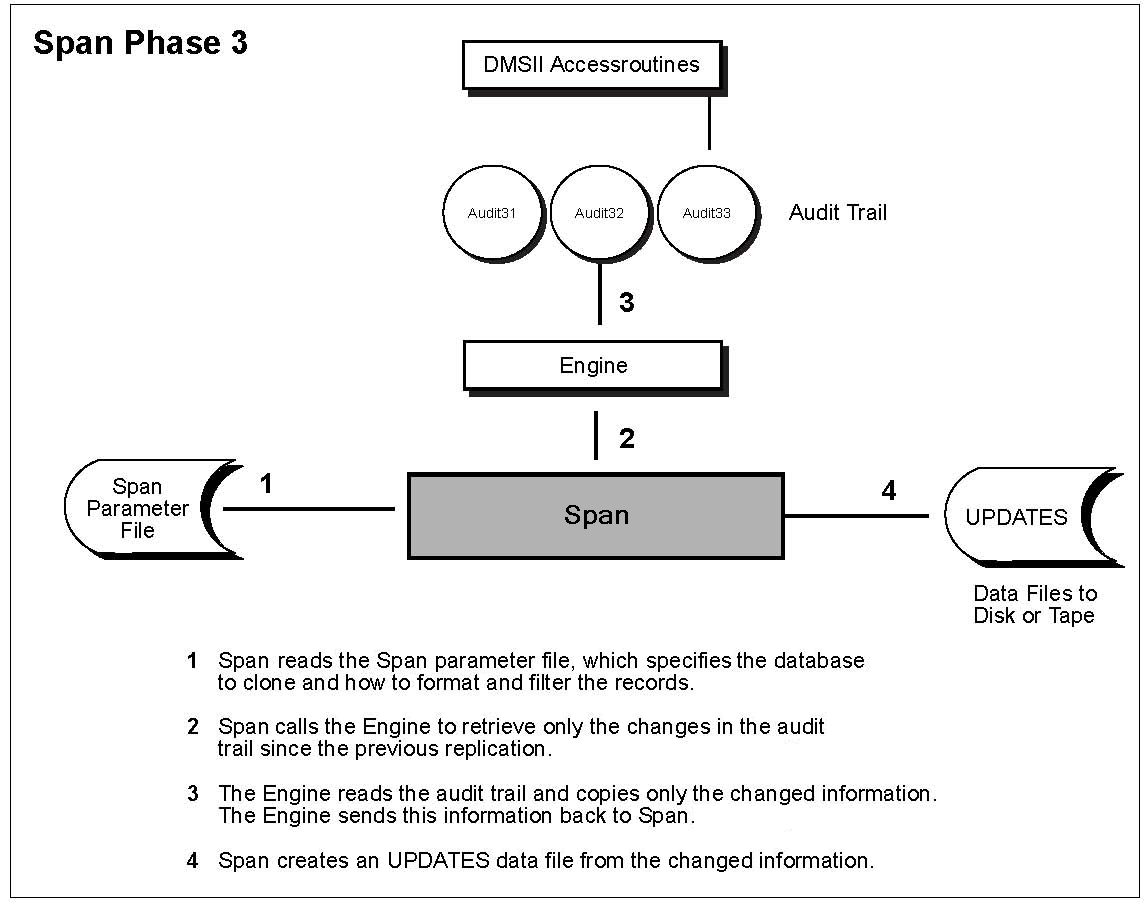
There are three phases when using Span:
Phase 1: Run Span to generate a Span parameter file for the database to be replicated.

Phase 2: Run Span to replicate the database.

Phase 3: Run Span to update the replicated database based on changes in the audit file since the initial replication or since the previous update.
Span and Snapshot Compared
The Span and Databridge Snapshot Accessories both extract the DMSII database to flat sequential disk files or tape. The following table includes a comparison of these Accessories to help you choose the most suitable replication method.
| Span | Databridge Snapshot |
|---|---|
| Most useful when you have frequent, ongoing database changes that you need to track. | Most useful for one-time clones. Also useful for gathering periodic information (such as month-end information that can be queried from a database). |
| Cleanup and consolidation occur on the secondary database system (requires fewer mainframe resources than Snapshot). | Cleanup and consolidation occur on the mainframe. |
| Maintains audit location information about each replicated data set. This information is used to determine where to start retrieving changes that it finds in the audit trail. This quiet point location is stored in the DATA/SPAN/databasename/CONTROL file on the host. | Records in the data files created by Snapshot represent the same QPT (quiet point) in the audit trail. |
| Provides updates to the secondary database (only database changes are gathered). When Span requests updates for data sets that have not been cloned, DBEngine initiates a routine to extract all of the records for the uncloned data sets and returns these records to Span as newly-created records. In addition, DBEngine forwards any changes that occurred to these records during the extraction. |
When you update the database, you must run Snapshot again to reclone it. |
| Span's update data must be loaded to the secondary database (for example, via a user-written program). | Snapshot's output data files must be transported to the secondary database. |
Span WFL
This WFL (WFL/DATABRIDGE/SPAN) starts Span. You can modify it for the:
- QUEUE—If, for example, you want Span to enter the system through job queue 10, you must modify the WFL job that compiles Databridge software to include the QUEUE (or CLASS) = 10 declaration.
- STARTTIME
- BDNAME—This is the default file naming convention for the printer file. The name of the printer file that is generated by default is
DBBD/RUN/SPAN/dbname.
Span TASKVALUEs
WFL/DATABRIDGE/SPAN also includes support for reporting the success or failure of Span. To do so, Span sets its TASKVALUE (same as VALUE) to either a positive or negative number.
When Span encounters any errors from DBEngine (DBMnnn), it returns the nnn number as a positive TASKVALUE. These DBMnnn values are listed in the Databridge Error and Message Guide, included with the product documentation.
When Span detects an error specific to itself (for example, no such parameter file), it returns a negative number, as listed in the following table.
In WFL/DATABRIDGE/SPAN, the TASK variable is named SPAN and the value is returned as SPAN
(VALUE). The following sample WFL code displays the SPAN (VALUE).
Example:
IF SPAN(TASKVALUE) < Ø THEN
DISPLAY "SPAN TASKVALUE = -" & STRING(SPAN(TASKVALUE), *);
ELSE
DISPLAY "SPAN TASKVALUE = +" & STRING(SPAN(TASKVALUE), *);
| Taskvalue | Description |
|---|---|
| TV_USER_TERMINATED = -1 | An operator entered the AX QUIT command to terminate Span. |
| TV_CONTROL_INUSE = -2 | The Span parameter file is in use by another version of Span. Wait until that version is finished and try again. |
| TV_CONTROL_CREATED = -3 | This value is returned when you run Span for the first time. It indicates that the Span parameter file was successfully created. |
| TV_HEADER_MISMATCH = -4 | This value indicates that the HEADER option is set to TRUE. Span is set to output to a consolidated file, but one of the following occurred:
|
| TV_WRITE_ERROR = -5 | This value indicates that Span is attempting to write output, but an I/O error occurred, resulting in Span terminating. |
| TV_CF_SYNTAX = -6 | This value indicates a syntax error in the Span parameter file. Make the correction in the parameter file and try again. |
| TV_RECOMPILE_FORMAT = -7 | This value indicates that the formatting entry point in the Support Library does not match the database layout. This is usually the result of a data set reorganization. Recompile the Support Library and then rerun Span. |
| TV_DUP_ENTRY = -8 | This values indicates duplicate entries in the Span parameter file. When there are two entries for the same data set, Span terminates with TASKVALUE = -8. |
| TV_AUDITFILE_LIMIT = -9 | This value indicates that Span has processed the number of audit files specified by the STOP AFTER parameter. |
| TV_RECORD_LIMIT = -10 | This value indicates that Span has reached the output file size limit specified by the STOP AFTER parameter. |
| TV_AUDITTIME_LIMIT = -11 | This value indicates that Span has stopped processing because of the time specified by the STOP AFTER parameter. |
| TV_AUDITNAME_LIMIT = -12 | This value indicates that Span has stopped processing because of the task name specified by the STOP parameter. |
Run the Span Accessory
You must run Span twice to replicate a database, as follows:
- First, to create a parameter file for the database you specify
- Second, to actually perform the replication
Once the database is replicated, run Span to perform the gathering and propagating of updates from the original database.
For subsequent runs of Span, you can use the existing Span parameter file for the database you are cloning. In other words, once you run Span to create the parameter file, you do not need to create the parameter file again.
To run Span:
-
Run Span without a parameter file, but with the name of the database to be replicated.
START WFL/DATABRIDGE/SPAN ("databasename" [,"logicaldatabasename"])Where Is "databasename" The title of the DESCRIPTION file without the DESCRIPTION node. The database name can include a usercode and pack, which are used to locate the database DESCRIPTION file, as follows: "(usercode)databasename ON packname"
The quotation marks are required.
When you enter just a database name, Span creates a parameter file named as follows:(usercode)DATA/SPAN/databasename/CONTROL ON familyname"logicaldatabasename" An optional name of a logical database when you want to do one of the following: - Clone the data sets and data items in the logical database instead of in the physical database.
- Create an alternate parameter file for the physical database, which is useful when you want to generate multiple support libraries for the same database but with different parameter files.
When you enter a logical database name:- Span uses DATA/SPAN/dbname/ldbname/CONTROL as the title of the parameter file, if it exists.
- Otherwise, Span uses DATA/SPAN/ldbname/CONTROL as it did in previous releases, if it exists.
- Otherwise, if neither file exists, Span creates one titled
DATA/SPAN/dbname/ldbname/CONTROL
The logical database name provides a means for having multiple parameter files for the same database. If ldbname is the name of a logical database within the dbname database, Span uses that logical database. If not, it uses ldbname to specify an alternate parameter file. -
Use CANDE to edit the Span options in the parameter file that Span just created. To do so, use the parameter descriptions listed in the Span Parameter File. These parameters determine where output is located, types of formatting and filtering routines to use, etc.
-
For each data set you want to replicate, replace the comment sign (%) that precedes the replication status information (structure number and state information) with a space. The replication status information looks similar to the following:
00005 000 0024 0000000866 0000340 00010 20140611135255 2 00000 00000If you prefer, you can also uncomment the actual data set name. However, uncommenting the data set name has no effect on replication. You must uncomment the replication status information for the data set to be replicated.
-
Save the edited the Span parameter file.
-
Run Span again, this time with the edited parameter file.
START WFL/DATABRIDGE/SPAN ("databasename" [,"logicaldatabasename"])where databasename and logicaldatabasename indicate the database names you used in step 1.
Note
If the message "No data set entries in parameter file" appears, make sure that you uncommented the replication information for each data set. Although you can uncomment data set names, Span reads only the replication information to clone a data set. For an example, see Sample Span Parameter File.
-
While Span is running, you can view the number of records it has replicated by using the AX STATUS command. Span creates the output data files for the data sets that are to be replicated as listed in the parameter file. If Span is writing the output data files to disk, skip to step 8.
If Span is writing to tape, dismount the tapes as soon as Span closes the output data file destined for that tape.
For example, Span closes an output data file when both of the following conditions occur: - The mode (Extract, Fixup, or Update) changes - The destination for the new mode is different than that for the old mode
-
When Span is finished, move the output files to the secondary database.
-
Back up the Span parameter file. This is essential if you need to reprocess from this point later. For example, if you do a rollback, you will use these parameter files. Keep in mind that the audit locations for synchronizing data set updates are written to the parameter file each time you run Span.
-
For the next step, you may want to do one or more of the following:
- Replicate a new database. Repeat steps 1-8 in this procedure.
- Determine how often to run Span for gathering updates. See Automating Span Processing and Span Tracking.
- Recover from a reorganization or rollback. See Chapter 11. DMSII Reorganizations and Rollbacks.
Span Parameter File
The first time you run Span on a particular database, it creates a parameter file for that database. This parameter file contains audit synchronization information (STATEINFO) for every data set in the database. You can then edit the parameter file Span created and designate the data sets you want to replicate. When you run Span the second time, it uses the parameter file and replicates the data sets you designated.
Span uses the parameter file to keep track of which data has been replicated. The parameter file also contains options that affect how Span processes the records. The default title for the Span parameter file is as follows:
DATA/SPAN/databasename/CONTROL
For the format of the Span parameter file, note the following:
- For all TRUE entries, you can use the synonym YES; likewise, for all FALSE entries, you can use the synonym NO.
- You can enter the parameters in the parameter file in any order.
- You can enter multiple parameters on a single line.
- You can split parameters across multiple lines except for data set replication status lines.
- There is no termination character.
- There is no continuation character.
- The comment character is the percent sign (%). The comment character can appear anywhere on a line and anything after the comment character is ignored.
-
If you have a file name or family name that is the same as a parameter file keyword, enclose the file name or family name in quotation marks. For example, if you have a family named SUPPORT (which is also the name of an option in the Span parameter file) and you want to enter that for the AUDIT ON option, enclose SUPPORT in quotation marks, as follows:
AUDIT ON "SUPPORT"This means that the audit files are on a family called SUPPORT.
-
All parameters are optional except for the list of data set replication statuses.
-
If a data set name has a hyphen, you must enclose the data set name in quotation marks.
The remainder of this section describes the syntax and semantics of each parameter. However, before you edit or create a Span parameter file, read Run the Span Accessory.
The first part of the parameter file contains all of the Span options listed in this section. Edit these as necessary.
Determining Output
The first three options in the Span parameter file determine where Span writes its output. There are three types of Span output, and you can specify the same or different locations for each output type, as follows:
- EXTRACTS—These output files contain the records that Span gathers from the DMSII database during the clone.
- FIXUPS—These output files contain the records that are recorded in the audit trail during the extraction phase of cloning. Fixup records are any update records that are written to the audit file while cloning takes place. If the database was not updated during the extraction phase, there will be no FIXUPS files.
- UPDATES—These output files contain the update records that Span retrieved from the audit files since the end of the fixup phase.
To direct the output files to the same location, specify the location for the UPDATES option and leave the other two options (EXTRACTS and FIXUPS) blank. In this case, all output is written to the location specified by UPDATES.
Note, however, that the filename and devicename parts of the EXTRACTS, FIXUPS, and UPDATES options default separately, as in the following examples:
Example 1
In this example, all UPDATES, FIXUPS, and EXTRACTS files are named with the file title nodes/ filename and are written to DISK.
EXTRACTS
FIXUPS
UPDATES nodes/filename ON DISK
Example 2
In this example, the UPDATES and FIXUPS files are named with the file title nodes/filename and are written to DISK. The EXTRACTS files are named with the file title nodes/filename but are written to TAPE.
EXTRACTS ON TAPE
FIXUPS
UPDATES nodes/filename ON DISK
Example 3
In this example, the UPDATES files are named with the file title nodes/filename and are written to DISK. The FIXUPS files are named A/B/= and are written to DISK. The EXTRACTS files are named with the file title nodes/filename but are written to TAPE.
EXTRACTS nodes/filename ON TAPE
FIXUPS A/B/=
UPDATES nodes/filename ON DISK
Example 4
In this example, the UPDATES files are named with the files title nodes/filename and are written to
DISK. The FIXUPS files are named nodes/filename and are written to PACK. The EXTRACTS files are
named with the file title nodes/filename and are written to TAPE.
EXTRACTS nodes/filename ON TAPE
FIXUPS nodes/filename ON PACK
UPDATES nodes/filename ON DISK
File Title and Device Names
The file title and device name designations default separately. If you specify EXTRACTS ON TAPE, Span uses the file title designation of the UPDATES. Even if UPDATES are designated to be written to DISK, the EXTRACTS will be written to TAPE.
Using this same example, if you specify FIXUPS A/B/= with no device name, the FIXUPS files will be
located in the place designated by UPDATES, in this case, DISK. The FIXUPS files will be named A/B/datasetname.
Note
Normal family substitution applies to the device name DISK. For example, if your family substitution statement is FAMILY DISK = DATAPACK OTHERWISE HLDISK, Span will write the output files to DATAPACK rather than the disk called DISK.
AUDIT JOB
Syntax: AUDIT JOB "(usercode)WFLname ON pack"
The quotation marks are required.
Use this parameter to specify the name (and optional usercode and pack) of a WFL that you want Span to start after it has processed an audit file. Span passes the WFL an integer, which is the AFN (audit file number).
AUDIT JOB takes effect when both of the following circumstances are met:
- The AFN changes.
- There is a COMMIT.
You might use AUDIT JOB, for example, to initiate the Audit Remove WFL to remove an audit file from a secondary pack. For more information, see Audit Remove Utility. You can combine the AUDIT ON and AUDIT JOB options as in the following syntax:
AUDIT ON packname JOB "WFLname"
AUDIT ON
Syntax: AUDIT ["fileprefix"] ON media [OR media][NO WAIT]
where media is one of the following:
[ PRIMARY | SECONDARY ] alternatepack
[ PRIMARY | SECONDARY ] ORIGINAL FAMILY
The optional fileprefix parameter can specify a title prefix, enclosed in quotes. This enables processing of audit files that have been renamed.
When the optional NO WAIT parameter appears, DBEngine will not wait when an audit file is missing. Instead, it will return DBM_AUD_UNAVAIL(7).
PRIMARY refers to the primary audit (for example, BANKDB/AUDIT1234) and SECONDARY refers to the secondary audit (for example, BANKDB/2AUDIT1234). If you don’t specify PRIMARY or SECONDARY, then Databridge will look for both if the database is declared to have duplicated audit.
Use one of the AUDIT ON parameters to specify where the audit files are stored. This parameter overrides the audit pack specified in the DMSII CONTROL file. You can combine the AUDIT ON and AUDIT JOB options as in the following syntax:
AUDIT ON packname JOB "WFLname"
Note
The AUDIT ON parameter does not specify where audit files are created; it only specifies where Databridge will look for audit files. During cloning, however, Databridge ignores the AUDIT ON parameter and reads from the active audit file on the original family where it is being written.
The following are examples of AUDIT ON parameters. In these examples, the database is called BANKDB and 1234 is the stored audit file. The DASDL has the following statement:
AUDIT TRAIL ATTRIBUTES (PACK = PAUDIT, DUPLICATED ON PACK = SAUDIT).
Modify the following examples to meet your specific needs:
AUDIT ON PRIMARY ORIGINAL FAMILY
% BANKDB/AUDIT1234 ON PAUDIT
AUDIT ON SPARE OR ORIGINAL FAMILY
% BANKDB/AUDIT1234 ON SPARE, or
% BANKDB/2AUDIT1234 ON SPARE, or
% BANKDB/AUDIT1234 ON PAUDIT, or
% BANKDB/2AUDIT1234 ON SAUDIT
CLONE
Syntax: CLONE [ OFFLINE | ONLINE ]
Use this parameter to specify whether Databridge should do an online extraction (the database is open for updates) or an offline extraction (the database is not open for updates).
If you do not specify OFFLINE or ONLINE, Span will do an online clone. You might want to clone offline to avoid having to apply any fixup records to the extracts file. If you specify OFFLINE, there will not be a fixup phase in the replication process since there will be no updates to the cloned data sets during the extract phase.
If the database has INDEPENDENTTRANS set, DBEngine will use SECURE STRUCTURE to enforce an offline clone. This allows other programs to update the data sets not being cloned. Otherwise, an offline dump is simulated.
DEFAULT MODIFIES
The DEFAULT MODIFIES option controls what Span writes to its updates files for all data sets except those for which you override DEFAULT MODIFIES, as explained in the next section.
The DEFAULT MODIFIES options are as follows:
DEFAULT MODIFIES AFTER IMAGES ONLY
DEFAULT MODIFIES BEFORE AND AFTER IMAGES
Use only one of these two options at a time. If both are uncommented, the last one in the list takes precedence.
You can override this value for individual data sets. See Individual Data Set Options for more information.
Selecting DEFAULT MODIFIES
Span can write the modified record only (AFTER IMAGE), or it can write the record as it looked before the modification (BEFORE IMAGE) and how it looked after the modification (AFTER IMAGE).
Typically, your decision on whether or not to save AFTER IMAGES ONLY or save BEFORE AND AFTER IMAGES is based on what you will do with the output file. Use the following table as a guide for which DEFAULT MODIFIES option to select.
| DEFAULT MODIFIES | Description |
|---|---|
| AFTER IMAGES ONLY | Span writes only the resulting change to the Span output file. In other words, Span writes the record the way it looks after the update. Selecting AFTER IMAGES ONLY is useful if your database has keys that are unique and that won’t change (for example, a customer number). This way, a client database can always find records via the key and therefore process any changed records. |
| BEFORE AND AFTER IMAGES | In this case, Span writes both the before image and the after image to the Span output file. This is the same as converting any modification of an existing record to a DELETE/CREATE pair (DELETE contains the before image; CREATE contains the after image). Selecting BEFORE AND AFTER IMAGES is useful when the DMSII database allows key fields to be updated. It ensures that even if the key of a record is changed, the client database can process the change correctly. For example, when the output file contains before and after images, the client software can search for the before image and find a match before it makes the update. The disadvantage of selecting BEFORE AND AFTER IMAGES is that the number of records for modifies doubles and could result in additional disk space requirements in the output files and additional processing time to write and read the records. |
DEFAULT RECORDS PER BLOCK/AREA
DEFAULT MODIFIES Description
| DEFAULT RECORDS PER BLOCK | DEFAULT RECORDS PER BLOCK nnn Default value: 100 records per block. Use this option to indicate the number of records per block for the output files. |
| DEFAULT RECORDS PER AREA | DEFAULT RECORDS PER AREA nnnn Default value: 1000 records per area Use this option to indicate the number of records per area for the output files. |
These values can be overridden for individual data sets. See Individual Data Set Options for more information.
EMBEDDED EXTRACTS
Syntax: EMBEDDED EXTRACTS [ TRUE | FALSE ]
Use this parameter to specify that embedded data sets should be extracted even if INDEPENDENTTRANS is not set, or the parent data sets do not have valid AA values (such as COMPACT or ORDERED data sets).
Note
This parameter does not allow you to track embedded data sets.
ERRORSFATAL
Syntax: ERRORSFATAL [ TRUE | FALSE ]
Use this option to specify whether or not you want to terminate Span on the first error encountered, as described in the following table.
| Value | Description |
|---|---|
| FALSE or NO | Default. Span continues processing when it encounters an error. If Span encounters a fatal error, however, it terminates immediately. |
| TRUE or YES | Span treats any error as a fatal error. In other words, Span reports the error message and then terminates processing immediately. |
Note
Span sets its TASKVALUE to the last DBM error code. TASKVALUEs less than zero are errors or warnings defined by Span. By checking for the DBM error code in TASKVALUE in WFL/DATABRIDGE/ SPAN, you can more easily determine the success or failure of a Span run.
EXTRACTS
Syntax: EXTRACTS [ directoryname | filename [ON devicename] ]
Leave this option blank if you want to use your entry for UPDATES as the default location. If you leave this option blank, EXTRACTS defaults to the destination for UPDATES. Otherwise, this location specifies where Span will write records extracted from the DMSII data sets during replication.
| Directory | To specify a directory location, enter the following:EXTRACTS directoryname/=Span creates an output file for each data set in the directory specified by directoryname. The title of each output data file is directoryname/datasetname. For example, the following entry: EXTRACTS DATA/MYDB/= ON DATAPACKcauses the EXTRACTS output file for the CUSTOMER data set to be titled as follows: DATA/MYDB/CUSTOMER ON DATAPACKIf the data set has variable formats, Span appends the record type number as the last node of the file title. For example, the following entry: EXTRACTS = ON TAPEensures that each data set is written to a separate tape titled data set name. If the data set has variable formats, the tapes are labeled as follows: datasetname/recordtype |
| Usercode | You can also specify a usercode as part of the directory name or file title. If so, you must do one of the following:
A usercode is not required for files output to TAPE. |
File Title Instead of Directory Name
If you specify filename rather than directoryname , Span writes all extracted records to that one file, which is called a consolidated file. By default, it is a STREAM file containing variable- length records. This option is intended primarily for sites replicating the data onto a PC or UNIX database, where data files are stream-oriented and a line-feed character delimits each record. The formatting routine in the Support Library should append the data set number and line-feed character to each record as needed.
Note
To specify fixed-length records, uncomment the file equation for EXTRACTS in the Span WFL job and adjust the file attributes as needed.
For example, the following entry:
EXTRACTS DATA/SPAN/COMBINED ON PACK
ensures that all extracted records are written to the following:
DATA/SPAN/COMBINED ON PACK
If you omit ON packname, the output defaults to the pack name for UPDATES. If you specify ON packname, FAMILY substitution rules apply.
FILTER
Syntax: FILTER filtername
where filtername is the name of a GenFormat filter routine that you have created. To create your own filtering routine, see Creating a Filter.
This option specifies the name of a filtering procedure, which is an entry point in the Support Library. Span calls the filtering procedure in the Support Library for each data set record. Your entry for SUPPORT determines the library that Span calls.
FIXUPS
Syntax: FIXUPS [ directoryname | filename [ON devicename] ]
This option specifies where Span writes the fixup records generated after the extraction phase of replication. Fixup records are any update records that are written to the audit file while extraction takes place.
Note
If you do an offline clone, there is no fixup phase.
directoryname or filename are treated the same as they are for the EXTRACTS.
Leave this option blank if you want to use your entry for UPDATES as the default location. If you leave this option blank, FIXUPS defaults to the destination for UPDATES.
FORMAT
Syntax: FORMAT formatname
This option specifies the name of the formatting procedure, which is the entry point in the Support Library. Span calls the format in the Support Library for each data set record. Your entry for SUPPORT determines which library Span calls.
Valid values include the following:
| formatname | Description |
|---|---|
| userwrittenformat | This is the name of a format routine that you have created. To create your own formatting routine, see Creating a Format. |
| FIXEDFORMAT | This is a format in the default Support Library. This format converts a data set record into fixed width, readable (EBCDIC) fields. This is similar to a COBOL program moving each field to a PIC … DISPLAY. When you use FIXEDFORMAT (or a similar format), you might want to set the DATACHECK format option to FALSE for improved performance. See FORMAT Options. |
| COMMAFORMAT | This is a format in the default Support Library. This format delimits all records in the data set by commas. |
| RAWFORMAT | This is a format in the default Support Library. This is a binary format that DMSII uses to store data on the host. BINARYFORMAT This is a format in the default Support Library. This is a binary format that applies the filter and any ALTERs. |
HEADER
Syntax: HEADER [ TRUE | FALSE ]
The HEADER option applies only to consolidated Span output files. A consolidated Span output file results when you specify a file title for the EXTRACTS, FIXUPS, and UPDATES options. In this case, the file specified by the file title contains all of the Span output. Compare this to specifying these options with directory/= , which creates several Span output files, each with the name of the data set in its title.
Use this option to specify whether or not you want Span to place a header at the beginning of a consolidated output file. The header contains the HOSTNAME as well as the complete starting and ending audit location in readable format. The HEADER option applies to normal updates, which occur when MODE = 2. The normal updates refer to updating a previously replicated database.
Using HEADER can facilitate secondary database processing by clarifying the order in which to process files. It also provides some continuity checking to ensure that files aren’t lost or processed twice.
| Value | Description |
| FALSE or NO | Default. No header is placed at the beginning of the consolidated output file. |
| TRUE or YES | Span writes a header record containing the complete audit locations corresponding to the start and end of the data file. Span inserts the following symbols in the header record:
- @ to designate the beginning of header data
- > to designate the starting audit location
- < to designate the ending audit location
If Span discovers that the data file already exists, it ensures that the old ending audit location matches the current starting location. If it does not match, Span renames the file by adding a node (…/BAD) and opens a new file. |
NONSTOP.
Syntax: NONSTOP nonstopoptions
If you want to use the NONSTOP option, you must add it to the Span parameter file. By default, it does not appear in the file.
Ordinarily, Span stops processing when it receives a purge or reorganization notification from DBEngine, or an output file reaches its maximum file size. You can override this, however, with the NONSTOP option.
Caution
Span does not handle the problem of a change in record size due to a reorganization; therefore, use these options with care. If you anticipate record size changes, turn the NONSTOP REORG option off.
You can specify any combination of the following nonstopoptions after the literal NONSTOP.
| nonstopoptions | Description |
|---|---|
| REORG | Span reselects the structure with values indicating that the problem has been resolved and continues processing even though DBEngine notifies it of a DMSII reorganization. Span will stop, however, in the case of a purge if NONSTOP PURGE has not been specified. |
| PURGE | Span reselects the structure with values indicating that the problem has been resolved and continues processing even though DBEngine notifies it of a DMSII purge. Span will stop, however, in the case of a reorganization if NONSTOP REORG has not been specified. |
| FILE LIMIT | CAUTION: NONSTOP FILE LIMIT applies only when you are using Span to update a replicated database. If you use NONSTOP FILE LIMIT for the initial database clone, the data extraction results will be unpredictable. Span closes the output file and creates a new one when the current output file reaches the host file size limit of 15000 areas. When the output file reaches 15000 areas and new records still need to be added, Span stops processing unless you set the NONSTOP FILE LIMIT option. When NONSTOP FILE LIMIT is set, Span closes the output file and renames it as follows: outputfilename/ending_ABSNwhere outputfilename is determined by the entries explained in File Title and Device Names. Span then opens a new output file under the original name. If the full output file contains a partial transaction at the end of the file, Span will move the partial transaction to the new output file before closing the original file. Therefore, all output files will contain only complete transactions. |
READER
Syntax: READER "librarytitle" using "param"
where librarytitle is the title of a Databridge FileXtract Reader library and param is the directory where the flat files you want to replicate are located. This parameter enables you to specify a Databridge FileXtract Reader library and the directory of the flat files you want to replicate, as in the following example:
READER "BANKFILE" USING "DATA/LOAD/SAMPLE/DATABASE"
REPORT
Syntax: REPORT reportoptions
The REPORT option controls the following:
- The types of information that Span writes to its report file. The types of information are controlled by the ERRORS, WARNINGS, and INFO options. Your selections are identified by the label “Logging” in the Span report file.
- The type of data errors that Span writes to its report file when the formatting routines detect a data error in a data set record. The types of data errors are controlled by the INVALID or NULL NUMBERS and TEXT options. Your selections are identified by the label “DataErrors” in the Span report file.
Caution
The formatting routines apply the data error options when you are using a formatting routine generated by GenFormat such as BINARYFORMAT, COMMAFORMAT or FIXEDFORMAT. RAWFORMAT routines do not use the data error options. User-written formatting routines do not use the data error options.
You can specify any combination of the following report options after the literal REPORT.
| reportoptions | Description |
|---|---|
| ERRORS | Span writes all error messages to the report. ERRORS include any errors detected by the formatting routines generated by the GenFormat program. |
| WARNINGS | Span writes all warning messages to the report. |
| INFO | Span writes informational messages such as data file titles, number of records replicated, etc., to the report. |
| INVALID NUMBERS | Span checks for the following error conditions:
|
| INVALID TEXT | Span writes all invalid text to the report. Invalid text is any text that has unreadable characters in an ALPHA data item. |
| ALL | This is the equivalent of ERRORS, WARNINGS, and INFO. This is also the default, and it is in effect even when you comment out the REPORT option. The only way to turn off the REPORT option is to enter NONE, explained next. |
| NONE | Span still creates a printer backup file, but it contains only the date Span was initialized, the version, and the Span parameter filename. |
The internal name of the Span report file is MSGFILE and it defaults to a printer backup file named as follows:
(usercode)DBBD/RUN/SPAN/databasename/jobnumber/tasknumber/000MSGFILE
For a sample report file, see Span Report Files.
You can file equate MSGFILE to some other device in WFL/DATABRIDGE/SPAN. The location of the printer backup file depends on the configuration at your site.
SOURCE
Syntax: SOURCE sourcename AT hostname VIA protocol PORT number
where sourcename is the name of a SOURCE in DBServer parameter file on the remote host, hostname is either the name of the remote host or if using TCP/IP, its TCP/IP address, protocol is either TCPIP, HLCN, or BNA, and number is the port number DBServer is using on the remote system.
Use the SOURCE parameter to specify that the audit files are on a remote host. This allows Span to run on a host that is less busy than the production host. DBEngine will communicate with DBServer on the remote host to retrieve portions of the audit trail.
The following is an example of a SOURCE parameter:
SOURCE BANKDB AT PROD VIA TCPIP PORT 3000
STOP
Syntax: STOP [ BEFORE | AFTER ] option
Use the STOP parameter to limit how much Span will replicate by specifying when it should stop processing audit information.
Note
Time in the STOP command refers to the time the update occurred on the primary system, not the current time of day. The “+/- days” are in relation to the Span Accessory start date. For example, when Span starts, it calculates an Audit file STOP date based on the current date plus or minus the “+/- days” parameter. Span stops when it reaches an Audit file with this calculated date.
The following table explains the STOP parameters:
| STOP Parameter | Description |
|---|---|
STOP AFTER n AUDIT FILES |
Span will stop processing at the first quiet point after n audit files have been processed. Use this option to set the maximum number of audit files Span will read during a Span run. For example, the following command informs Span to stop processing after seven audit files: STOP AFTER 7 AUDIT FILES |
STOP AFTER n RECORDS |
Span will stop processing at the first quiet point after n records have been processed. Use this option to limit the number of records Span will write to its update files during a run. For example, the following command informs Span to stop processing at the first quiet point after 1000 records: STOP AFTER 1000 RECORDS |
STOP { BEFORE |
Span will stop processing at either the last quiet point before or the first quiet point after the time ( hh:mm ) and number of days (0 indicates current) specified. Use this option to set the earliest or latest time and date at which Span will stop processing. For example, the following command informs Span to stop processing at the last quiet point before 10:30 p.m.: STOP BEFORE 10:30 PM |
STOP { BEFORE |
Span will stop processing at either the last quiet point before the designated task started or the first quiet point after the designated task is completed. If you specify a usercode in taskname, Span looks for a task name match under the specified usercode. Otherwise, Span looks for task name match under any usercode. Use the STOP AFTER option to coordinate termination of Span with that of another, unrelated task. When Span finds a record in the audit trail that is a result of the specified task doing a CLOSE on the database, it stops at the next QPT. Use the STOP BEFORE option to ensure that Span update data represents the data available before the specified task started. When Span finds a record in the audit trail that is a result of the specified taskdoing an OPEN UPDATE on the database, it rolls back to the previous QPT, which results in stopping before the specified task. For example, the following command informs Span to stop processing at the first quiet point after the EOT of a task named OBJECT/SAVINGS/POSTING: STOP AFTER "OBJECT/SAVINGS/POSTING" |
STOP { BEFORE |
Depending on which occurs first, Span will stop processing at either the last quiet point before the designated task started or the first quiet point after the designated task finished or at either the last quiet point before or the first quiet point after the designated time on the designated date. For example, the following command informs Span to stop processing at the first quiet point after the EOT of task name OBJECT/SAVINGS/POSTING on December 9, 2012 or to stop processing at the last quiet point before 10:30 p.m. on December 9, 2012, whichever occurs first: STOP AFTER "OBJECT/SAVINGS/POSTING" OR BEFORE 10:30 PM ON 12/9/2012 |
SUPPORT
Syntax: SUPPORT title
If you are using a tailored support library, type the name of the tailored support library for the database you are replicating. The names you enter for FORMAT and FILTER must be compiled in the tailored support library that you specify for SUPPORT. If you have not created a tailored support library yet, see Understanding DBGenFormat.
Otherwise, if you don’t enter a SUPPORT title, it is automatically entered the first time you run Span. Span looks for Support libraries in this order:
OBJECT/DATABRIDGE/SUPPORT/dbname/ldbname
OBJECT/DATABRIDGE/SUPPORT/dbname
OBJECT/DATABRIDGE/SUPPORT
TAPE
If you specify ON TAPE, Span names the tapes depending on the format (directory/= or filename) that you enter. Tape names can be only two nodes long, so Span resolves them as follows:
| directory/= | If the format is directory/=, Span names each tape as follows: last_node_of_the_directory/datasetname For example, if you enter EXTRACTS A/B/C/= ON TAPE, the resulting tapes would be named as follows: C/datasetnameIf the data set has variable formats, the tape is named for each variable format (except 0) as follows: datasetname/variable_format_number |
| filename | If the format is filename, Span names each tape with the last two nodes of the file title, as follows: second_to_last_node/last_node For example, if you enter EXTRACTS D/E/F ON TAPE, the resulting, single tape would be named as follows: E/F |
TITLE
Syntax: TITLE [ TIMESTAMP | AFN | ABSN ]
This optional parameter followed by at least one field causes additional nodes to appear in the output file titles. If TIMESTAMP is used, the current date and time are appended to output file titles, in YYYYMMDD/HHMMSS format. If AFN or ABSN are used, the audit file number or audit block serial number is appended to the output file titles. Ordering is fixed when multiple TITLE fields are specified. For example, if all fields are specified, titles are appended with TIMESTAMP first, followed by AFN and then ABSN.
Note
The TITLE option is ignored for files created by clones.
TRANGROUP
Syntax: TRANGROUP [ QPT | CHECKPOINT | NONE ]
Using this parameter enables you to specify a different size for the transaction groups instead of using the normal transaction groups (Checkpoint) that is specified in the DBEngine parameter file (see Checkpoint Frequency for more information).
Your entry for TRANGROUP can be one of the following:
directory/ = If the format is directory/ =, Span names each tape as follows:
| Option | Description |
|---|---|
| QPT | This option causes Span to perform a commit at every quiet point. |
| CHECKPOINT | DBEngine will determine the size of transaction groups based on the CHECKPOINT option in the DBEngine parameter file. This is the default. |
| NONE | This option makes Span modeless and transactions ungrouped. DBEngine will send updates to Span as part of one long group and will never tell Span to abort any updates. Also, it will ignore any reorgs or purges it encounters. This feature is useful for simply reporting the records in the audit trail without regard for transaction groups or audit discontinuities. NOTE: This option, NONE, is intended for reporting purposes only; it is not intended for generating data to be loaded in another database or for production processing. |
TRANSFORM
Syntax: TRANSFORM transformname
where transformname is the name of a GenFormat transform routine that you have created. To create a transform routine, see Transforms.
This option specifies the name of the transform routine, which is the entry point in the Support Library. Span calls the transform in the Support Library for each data set record. Your entry for SUPPORT determines which library Span calls.
UPDATES
Syntax: UPDATES [ directoryname | filename [ON devicename] ]
This option specifies where Span writes the normal update records retrieved during tracking.
directoryname or filename are treated the same as they are for the EXTRACTS option. The default name for UPDATES is as follows:
DATA/SPAN/databasename/dataset
If the UPDATES output files already exist, Span appends the new records to the existing files.
Note
Each time Span closes a disk UPDATES file, the USERINFO file attribute is set to the ending ABSN.
Tape Example
If you enter UPDATES ON TAPE, Span takes the default filename, which for UPDATES is DATA/SPAN/ databasename /=.
However, since tape names can be only two nodes, the tape names would actually be databasename/datasetname. If a data set requires more than one tape (or cartridge), the tape name stays the same, but the MCP increments the reel number.
Caution
If you specify a directory name (resulting in one file per structure) ON TAPE, you must have one tape drive per structure, and they must all be opened at once.
Individual Data Set Options
Individual data set options for RECORDS PER ... and BYTES PER RECORD apply only when each data set is written to its own file (that is, you are not using a consolidated output file). The individual data set options override the settings for the following:
- DEFAULT MODIFIES
- DEFAULT RECORDS PER BLOCK
- DEFAULT RECORDS PER AREA
Individual data set options are listed in the Span parameter file in the following format:
% Dataset "datasetname"
% Records per Area nnnn
% Records per Block nnn
% Bytes per Record?
% After Images Only
% Before and After Images
00004 000 0000 0000000000 0000000 00000 00000000000000 0 00000 00000
Overriding DEFAULT MODIFIES
Once you set an option for DEFAULT MODIFIES, you can override it for individual data sets by removing the comment character (%) in front of your selection.
The following example is from the BANKDB database.
% Dataset "BANKDB"
% Records per Area 1000
% Records per Block 100
% Bytes per Record?
% After Images Only
Before and After Images
00001 000 0000 0000000000 0000000 00000 00000000000000 0 00000 00000
| Overriding DEFAULT RECORDS PER AREA | Syntax: RECORDS PER AREA nnnnDefault value: 1000 records per area. This option determines the size of each area (in records) that will be written to the Span output files. |
| Overriding DEFAULT RECORDS PER BLOCK | Syntax: RECORDS PER BLOCK nnnDefault value: 100 records per block. This option determines the size of each block (in records) that will be written to the Span output file. |
| Overriding DEFAULT RECORD SIZE | Syntax: BYTES PER RECORDThere is no default value for BYTES PER RECORD because the actual value depends on the format routine you select. This option determines the size of each record (in bytes) that will be written to the Span output files. For Span to calculate the bytes per record automatically, leave the comment character (%) in front of this option. If you do not specify a BYTES PER RECORD value, the record size is dependent on the format you select. For example, a COMMAFORMATQUOTEALL format will require more space than a FIXEDFORMAT. If you do decide to set bytes per record, keep the following in mind: If the bytes per record are set too large, you get all the data, but the drawback is the extra space required. If the bytes per record are set too small, the data are truncated. The size limit is the host record size limit. |
Sample Span Parameter File
The following is a sample Span parameter file for a DMSII database titled BANKDB.
The Span parameter file is divided in two parts: the first part lists the Span parameters; the second part lists all of the data sets and remaps in the database being replicated.
% Databridge Span parameter file for BANKDB
% Created Monday, November 30, 2015 @ 10:39:52 by Version 6.6.0.001
% location of output data files
Extracts ON SPANDISK
Fixups ON SPANDISK
Updates (DB66)DATA/SPAN/BANKDB/= ON SPANDISK
%Title TIMESTAMP % put date and time nodes in titles
%Title ABSN % put starting ABSN in titles
%Title AFN % put starting AFN in titles
Support (DB66)OBJECT/DATABRIDGE/SUPPORT/BANKDB ON USER
%Transform <transformname> % transform routine in DBSupport
Format BINARYFORMAT % formatting routine in DBSupport
Filter DBFILTER % filtering routine in DBSupport
Prefiltered false % false => do not use filtered audits
% ONLY => use only filtered audits
% PREFERRED => filtered audits preferred
%Reader "librarytitle" using "param" % FILEBridge
TranGroup Checkpoint % use Engine's Checkpoint value (default)
%TranGroup QPT % commit at every quiet point
%Source <sourcename> at <hostname> via TCPIP port 3000 % remote host
%Audit "(<usercode>)<directory>" % audit file name prefix
%Audit on <packname> % location of audit files
%Audit on ORIGINAL FAMILY % audit files on original packs
% Audit no wait % don't wait on NOFILE for audit
%Audit Job "<WFL job>" % job to zip when done with audit file
Report ERRORS WARNINGS INFO % message reporting options
% INVALID Numbers Text % report invalid data
% NULL Numbers Text % report NULL data
ErrorsFatal true % true => if any error occurs, stop program
Header false % true => audit location in consolidated file
%Extract Embedded % true => extract embedded w/o INDEPENDENTTRANS
%Clone OFFLINE % OFFLINE => exclusive use of database
% ONLINE => allow updates and database dump
%Stop At First QPT After n AUDIT FILES % max audit files processed
%Stop At First QPT After n RECORDS % max records written
%Stop At First QPT After hh:mm on + 0 % lower bound time and date
%Stop At Last QPT Before hh:mm on + 0 % upper bound time and date
%Stop At First QPT After "taskname" % after EOT
% or Before hh:mm on mm/dd/yyyy % but by this time & date
%Stop At Last QPT Before "taskname" % before BOT
Default Records per Block 100 % default number of records per block
Default Records per Area 1000 % default number of records per area
Default Modifies After Images Only % new record value only
%Default Modifies Before and After Images % old record value first
%Data Rec File Aud Block Segment Word Date Time Mo- Format-Lvl
%-set Type Nbr SerialNbr Number Index YYYYMMDDhhmmss de DMS Client
%---- --- ---- --------- ------- ----- -------------- - ---- ----
% Dataset "BANKDB"
% Records per Area 1000
% Records per Block 100
% Bytes per Record?
% After Images Only % modified records
% Before and After Images % modified records
00001 000 0003 0000000376 0000000 00000 00000000000000 0 00000 00000
% Dataset "DBTWINCONTROL"
% Records per Area 1000
% Records per Block 100
% Bytes per Record?
% After Images Only % modified records
% Before and After Images % modified records
%00002 000 0000 0000000000 0000000 00000 00000000000000 0 00000 00000
% Dataset "RG"
% Records per Area 1000
% Records per Block 100
% Bytes per Record?
% After Images Only % modified records
% Before and After Images % modified records
%00004 000 0000 0000000000 0000000 00000 00000000000000 0 00000 00000
% Dataset "MASTER-DS"
% Records per Area 1000
% Records per Block 100
% Bytes per Record?
% After Images Only % modified records
% Before and After Images % modified records
%00005 000 0000 0000000000 0000000 00000 00000000000000 0 00000 00000
% Dataset "ORDERED-DS"
% Records per Area 1000
% Records per Block 100
% Bytes per Record?
% After Images Only % modified records
% Before and After Images % modified records
%00006 000 0000 0000000000 0000000 00000 00000000000000 0 00000 00000
% Dataset "EMB-STANDARD"
% Records per Area 1000
% Records per Block 100
% Bytes per Record?
% After Images Only % modified records
% Before and After Images % modified records
%00008 000 0000 0000000000 0000000 00000 00000000000000 0 00000 00000
% Dataset "RSDATA"
% Records per Area 1000
% Records per Block 100
% Bytes per Record?
% After Images Only % modified records
% Before and After Images % modified records
%00011 000 0000 0000000000 0000000 00000 00000000000000 0 00000 00000
% Dataset "BANK"
% Records per Area 1000
% Records per Block 100
% Bytes per Record?
% After Images Only % modified records
% Before and After Images % modified records
%00013 000 0000 0000000000 0000000 00000 00000000000000 0 00000 00000
% Dataset "BRANCH"
% Records per Area 1000
% Records per Block 100
% Bytes per Record?
% After Images Only % modified records
% Before and After Images % modified records
%00016 000 0000 0000000000 0000000 00000 00000000000000 0 00000 00000
% Dataset "MERGE-BRANCH"
% Records per Area 1000
% Records per Block 100
% Bytes per Record?
% After Images Only % modified records
% Before and After Images % modified records
%00017 000 0000 0000000000 0000000 00000 00000000000000 0 00000 00000
% Dataset "CUSTOMER"
% Records per Area 1000
% Records per Block 100
% Bytes per Record?
% After Images Only % modified records
% Before and After Images % modified records
%00019 000 0000 0000000000 0000000 00000 00000000000000 0 00000 00000
% Dataset "EMPLOYEES"
% Records per Area 1000
% Records per Block 100
% Bytes per Record?
% After Images Only % modified records
% Before and After Images % modified records
%00020 000 0000 0000000000 0000000 00000 00000000000000 0 00000 00000
% Dataset "DEPENDENTS"
% Records per Area 1000
% Records per Block 100
% Bytes per Record?
% After Images Only % modified records
% Before and After Images % modified records
%00021 000 0000 0000000000 0000000 00000 00000000000000 0 00000 00000
% Dataset "R-CUST"
% Records per Area 1000
% Records per Block 100
% Bytes per Record?
% After Images Only % modified records
% Before and After Images % modified records
%00025 000 0000 0000000000 0000000 00000 00000000000000 0 00000 00000
% Dataset "CUSTONELINE"
% Records per Area 1000
% Records per Block 100
% Bytes per Record?
% After Images Only % modified records
% Before and After Images % modified records
%00026 000 0000 0000000000 0000000 00000 00000000000000 0 00000 00000
% Dataset "CUSTNAMEONLY"
% Records per Area 1000
% Records per Block 100
% Bytes per Record?
% After Images Only % modified records
% Before and After Images % modified records
%00027 000 0000 0000000000 0000000 00000 00000000000000 0 00000 00000
% Dataset "TELLER"
% Records per Area 1000
% Records per Block 100
% Bytes per Record?
% After Images Only % modified records
% Before and After Images % modified records
%00030 000 0000 0000000000 0000000 00000 00000000000000 0 01751 01751
% Dataset "ACCOUNT"
% Records per Area 1000
% Records per Block 100
% Bytes per Record?
% After Images Only % modified records
% Before and After Images % modified records
%00032 000 0000 0000000000 0000000 00000 00000000000000 0 00000 00000
% Dataset "ACCOUNT" (1)
% Records per Area 1000
% Records per Block 100
% Bytes per Record?
% After Images Only % modified records
% Before and After Images % modified records
%00032 001 0000 0000000000 0000000 00000 00000000000000 0 00000 00000
% Dataset "ACCOUNT" (2)
% Records per Area 1000
% Records per Block 100
% Bytes per Record?
% After Images Only % modified records
% Before and After Images % modified records
%00032 002 0000 0000000000 0000000 00000 00000000000000 0 00000 00000
% Dataset "ACCOUNT" (3)
% Records per Area 1000
% Records per Block 100
% Bytes per Record?
% After Images Only % modified records
% Before and After Images % modified records
%00032 003 0000 0000000000 0000000 00000 00000000000000 0 00000 00000
% Dataset "ACCOUNT" (4)
% Records per Area 1000
% Records per Block 100
% Bytes per Record?
% After Images Only % modified records
% Before and After Images % modified records
%00032 004 0000 0000000000 0000000 00000 00000000000000 0 00000 00000
% Dataset "ACCOUNT" (5)
% Records per Area 1000
% Records per Block 100
% Bytes per Record?
% After Images Only % modified records
% Before and After Images % modified records
%00032 005 0000 0000000000 0000000 00000 00000000000000 0 00000 00000
% Dataset "R-ACCT"
% Records per Area 1000
% Records per Block 100
% Bytes per Record?
% After Images Only % modified records
% Before and After Images % modified records
%00035 000 0000 0000000000 0000000 00000 00000000000000 0 00000 00000
% Dataset "R-ACCT" (3)
% Records per Area 1000
% Records per Block 100
% Bytes per Record?
% After Images Only % modified records
% Before and After Images % modified records
%00035 003 0000 0000000000 0000000 00000 00000000000000 0 00000 00000
% Dataset "R-ACCT" (1)
% Records per Area 1000
% Records per Block 100
% Bytes per Record?
% After Images Only % modified records
% Before and After Images % modified records
%00035 001 0000 0000000000 0000000 00000 00000000000000 0 00000 00000
% Dataset "R-ACCT" (2)
% Records per Area 1000
% Records per Block 100
% Bytes per Record?
% After Images Only % modified records
% Before and After Images % modified records
%00035 002 0000 0000000000 0000000 00000 00000000000000 0 00000 00000
% Dataset "R-ACCT" (4)
% Records per Area 1000
% Records per Block 100
% Bytes per Record?
% After Images Only % modified records
% Before and After Images % modified records
%00035 004 0000 0000000000 0000000 00000 00000000000000 0 00000 00000
% Dataset "R-ACCT" (5)
% Records per Area 1000
% Records per Block 100
% Bytes per Record?
% After Images Only % modified records
% Before and After Images % modified records
%00035 005 0000 0000000000 0000000 00000 00000000000000 0 00000 00000
% Dataset "SERIOUS-STUFF"
% Records per Area 1000
% Records per Block 100
% Bytes per Record?
% After Images Only % modified records
% Before and After Images % modified records
%00036 000 0000 0000000000 0000000 00000 00000000000000 0 00000 00000
% Dataset "HISTORY"
% Records per Area 1000
% Records per Block 100
% Bytes per Record?
% After Images Only % modified records
% Before and After Images % modified records
%00037 000 0000 0000000000 0000000 00000 00000000000000 0 00000 00000
% Dataset "TRIALBALANCES"
% Records per Area 1000
% Records per Block 100
% Bytes per Record?
% After Images Only % modified records
% Before and After Images % modified records
%00039 000 0000 0000000000 0000000 00000 00000000000000 0 00000 00000
% Dataset "ADDRESSES"
% Records per Area 1000
% Records per Block 100
% Bytes per Record?
% After Images Only % modified records
% Before and After Images % modified records
%00041 000 0000 0000000000 0000000 00000 00000000000000 0 00000 00000
% Dataset "DIS-ORDERED"
% Records per Area 1000
% Records per Block 100
% Bytes per Record?
% After Images Only % modified records
% Before and After Images % modified records
%00043 000 0000 0000000000 0000000 00000 00000000000000 0 00000 00000
% Dataset "EMB-ORDERED"
% Records per Area 1000
% Records per Block 100
% Bytes per Record?
% After Images Only % modified records
% Before and After Images % modified records
%00044 000 0000 0000000000 0000000 00000 00000000000000 0 00000 00000
% Dataset "L1"
% Records per Area 1000
% Records per Block 100
% Bytes per Record?
% After Images Only % modified records
% Before and After Images % modified records
%00047 000 0000 0000000000 0000000 00000 00000000000000 0 00000 00000
% Dataset "L2"
% Records per Area 1000
% Records per Block 100
% Bytes per Record?
% After Images Only % modified records
% Before and After Images % modified records
%00048 000 0000 0000000000 0000000 00000 00000000000000 0 00000 00000
% Dataset "L3"
% Records per Area 1000
% Records per Block 100
% Bytes per Record?
% After Images Only % modified records
% Before and After Images % modified records
%00049 000 0000 0000000000 0000000 00000 00000000000000 0 00000 00000
% Dataset "R-L2"
% Records per Area 1000
% Records per Block 100
% Bytes per Record?
% After Images Only % modified records
% Before and After Images % modified records
%00051 000 0000 0000000000 0000000 00000 00000000000000 0 00000 00000
% Dataset "L1-WITH-EMB"
% Records per Area 1000
% Records per Block 100
% Bytes per Record?
% After Images Only % modified records
% Before and After Images % modified records
%00055 000 0000 0000000000 0000000 00000 00000000000000 0 00000 00000
% Dataset "R-L1"
% Records per Area 1000
% Records per Block 100
% Bytes per Record?
% After Images Only % modified records
% Before and After Images % modified records
%00056 000 0000 0000000000 0000000 00000 00000000000000 0 00000 00000
% Dataset "L1-NO-EMBEDDED"
% Records per Area 1000
% Records per Block 100
% Bytes per Record?
% After Images Only % modified records
% Before and After Images % modified records
%00057 000 0000 0000000000 0000000 00000 00000000000000 0 00000 00000
% Dataset "SHORT-VF"
% Records per Area 1000
% Records per Block 100
% Bytes per Record?
% After Images Only % modified records
% Before and After Images % modified records
%00058 000 0000 0000000000 0000000 00000 00000000000000 0 00000 00000
% Dataset "SHORT-VF" (2)
% Records per Area 1000
% Records per Block 100
% Bytes per Record?
% After Images Only % modified records
% Before and After Images % modified records
%00058 002 0000 0000000000 0000000 00000 00000000000000 0 00000 00000
% Dataset "SHORT-VF" (5)
% Records per Area 1000
% Records per Block 100
% Bytes per Record?
% After Images Only % modified records
% Before and After Images % modified records
%00058 005 0000 0000000000 0000000 00000 00000000000000 0 00000 00000
% Dataset "STATEMENT"
% Records per Area 1000
% Records per Block 100
% Bytes per Record?
% After Images Only % modified records
% Before and After Images % modified records
%00060 000 0000 0000000000 0000000 00000 00000000000000 0 00000 00000
% Dataset "NAMES"
% Records per Area 1000
% Records per Block 100
% Bytes per Record?
% After Images Only % modified records
% Before and After Images % modified records
%00061 000 0000 0000000000 0000000 00000 00000000000000 0 00000 00000
% Dataset "R-BRANCH"
% Records per Area 1000
% Records per Block 100
% Bytes per Record?
% After Images Only % modified records
% Before and After Images % modified records
%00063 000 0000 0000000000 0000000 00000 00000000000000 0 00000 00000
Replication Status
The replication status information follows the data set parameters (records per area, record per block, etc.) and is organized as follows:
 The following table briefly describes the replication status information. Do not make changes to the
replication status information unless you are instructed to do so.
The following table briefly describes the replication status information. Do not make changes to the
replication status information unless you are instructed to do so.
| Column | Description |
|---|---|
| Data Set Structure Number | The DMSII structure number of the data set or remap. |
| RecType | The record type for variable format data sets. |
| AFN ABSN SEG INX | The information in these columns represent the physical point in the audit file for the data set. |
| Date Time | The point in time of the data set in the audit file. NOTE: The first time you run Span, there is no audit file time and date. Therefore, the date and time column contains 00000000000000, which is the host zero date. After the data set is replicated, the date and time stamp indicate the position in the audit file. |
| Mode | Indicates the data set status, as follows:
|
| DMS Format Level | This is the data set format level. Span puts the format level in thiscolumn during the clone and during DMSII reorganizations. NOTE: Zero is a valid format level. The format level will change when the DMSII data set is reorganized. |
| Client Format Level | This is the format level in the client database. |
Do not make changes to the replication status information in the Span parameter file except in the following circumstances:
- Modify Mode when you do a purge or reorganization. A mode of 3 indicates a data set reorganization. A mode of 4 indicates data set purge (DMUTILITY initialize).
- After the reorganization on the client side, change the mode to 2 and then update the Client column (Format Level) to match the DMSII column (also under Format Level). The DMSII and Client columns are as follows:
- The DMSII column is the DMSII update level (when the data set was added to or modified in the database definition). Each DASDL compile increments the level by one. For example, if you reorganized a data set the tenth time you update the DASDL, that data set has the number 0010 in the DMSII column. Note, however, that if the data set was ALTERed using GenFormat, the format level is recomputed and will have no obvious relationship with the DASDL compile number.
- The Client column represents the update level of the data set in the Client database. Using the example of a data set reorganized on the tenth update, you would update the Client column to 0010 (the same as the DMSII level) after you reorganized that data set in the Client database.
Purges
When you purge a data set in the DMSII database, the value for the mode changes to 4. A mode of 4 indicates that the data set was purged; however, there is no DMS format level change. Instead, when you get a mode of 4, you must purge the corresponding table (data set) in the client database and then change the mode to 2.
Reorganizations
When you change the DMSII database layout (for example, adding a data item), two things happen, as follows:
-
The DMSII format level corresponding to the changed data set is increased to the current database update level. The client format level, however, does not change. Instead, update the client database with the change and then increase the client format level to match the DMSII level.
Note
The change to the data set may require you to do a reorganization on the client database.
-
The mode changes to 3. Once you add the data item, for example, to the client database and increase the client format level, change the mode back to 2.
Span Report Files
Following are examples of Span output based on the Span parameter file described previously. The Span report files are named as follows:
DBBD/RUN/SPAN/databasename/jobnumber/tasknumber/nnnMSGFILE ON packname
First Printer Backup File
The following printer backup file is created when you run Span for the first time for a database.
Databridge SPAN Initializing month dd, yyyy @ hh:mm:ss on host hostname.
Version 7.0.x.x compiled date @ hh:mm:ss
Creating new parameter file DATA/SPAN/BANKDB/CONTROL
Databridge SPAN Terminating date @ hh:mm:ss
Report File
A printer backup file similar to the following is created whenever you run Span to replicate or track a database. After the list of option settings, the Span report file shows the mode and data set name followed by the output file name:
- To the left of the arrow is a description of the mode (for example, extracts or updates) and type of record.
- To the right of the arrow is the actual name of the file Span used to write these records. A + (plus sign) preceding the file name indicates that the file already existed and Span appended the new records to it.
The message "Databridge Engine: >> [0007] Audit file 3 is unavailable; Current (active) audit file <<" indicates why Span stopped processing. In this case, Span processed all of the available audit files and then stopped when it encountered the audit file the Accessroutines was still using.
The last part shows how many records Span wrote and skipped (due to the filter) for each data set.
Databridge SPAN Initializing month dd, yyyy @ hh:mm:ss on host hostname
Version 7.0.x.x compiled date @ hh:mm:ss
Reading parameter file (DB70)DATA/SPAN/BANKDB/CONTROL ON HOST
Option settings for database BANKDB:
Extracts = (DB70)DATA/SPAN/BANKDB/= on DISK
Fixups = (DB70)DATA/SPAN/BANKDB/= on DISK
Updates = (DB70)DATA/SPAN/BANKDB/= on DISK
Support = (DB70)OBJECT/DATABRIDGE/SUPPORT/BANKDB ON HOST
Transform = DBTRANSFORM
Format = COMMAFORMAT
Filter = DBFILTER
Errors = Fatal
Audits = Normal
TranGroup = Checkpoint
Limit = <no limits>
Logging = Errors Warnings Informational
DataErrors= <ignore>
Clone = Online
Defaults:
Block = 100 records
Area = 1000 records
Modifies= After-images only
Extracts BANK ===> (DB70)DATA/SPAN/BANKDB/BANK ON HOST
Extracts BRANCH ===> (DB70)DATA/SPAN/BANKDB/BRANCH ON HOST
>> [0007] Active audit file 2 is unavailable <<
Replicated Skipped
---------- -------
BANK 7 0
BRANCH 28 0
Total records: 35 0
Thruput: 9 records/sec. CPU (excluding Extract Workers)
2 records/sec. elapsed
Final audit location: date @ time, AFN = 2, ABSN = 56
Databridge SPAN Terminating date @ time
Span Commands
AX STATUS |
To display status information about Span, enter the following:where mixnumber is the mix number of Span. Once you enter this AX STATUS command, enter one of these:
Span responses will appear in the system messages. The following is an example of Span in the process of extracting: #9936 Databridge Engine: Extracting for CUSTOMER. |
| AX QUIT | If for any reason you don’t want Span to complete, enter the following command:mixnumber AX QUITwhere mixnumber is the mix number of OBJECT/DATABRIDGE/SPAN. The AX QUIT command causes Span to terminate at the next quiet point.After you enter the AX QUIT command, Span displays the message Terminating at next quiet point. The number of records replicated and the number of records skipped is written to the Span report file (MSGFILE).For example, if the Span mix number is 1234 and you want Span to terminate at the next quiet point, enter the following: 1234AX QUIT |
Automating Span Processing
This section explains automating Span after an audit file closes. For information on controlling when audit files close, see AuditTimer Utility.
When you use Span to replicate a database, you must determine how often and when you want it to gather updates to the DMSII database. You could run Span each time an audit file closes, or you could run it once per day.
| Run Span at Audit File Close | The most convenient option is to run Span with the DMSII copy audit WFL that the Accessroutines initiate when an audit file closes. (The advantage of this method is that the audit file is readily available. The disadvantage is that you don’t have much control over when it runs.) To run Span each time an audit file closes, you must configure and run the Copy Audit program. For instructions, see Copy Audit Utility. |
| Once Per Day Alternative | Another option is to run Span once per day (as part of batch processing) and have it process all audit files closed during that day. The advantage is that you have complete control over when Span runs. The disadvantage is that the audit files Span needs may have been already copied to tape and removed from disk. In this case, you would have to mount the audit tapes as Span requests them. For instance, if you prefer to run Span only once a day during the nightly batch run, include the Span WFL that runs Span in the nightly batch job stream. |
| Transaction Groups Across Audit Files | Regardless when you choose to run Span, a transaction group might be started in one audit file and finished in the next. Since the end of an audit file is not necessarily a quiet point—transaction groups often start in one audit file and finish in another—Span may need a previous audit file so that it can find the (partial) transaction group that didn’t finish until the next audit file. For example, suppose Span processes audit file 104. At the end of audit file 104, it sees the start of a transaction group that is carried over into audit file 105. Since Span only returns completed transaction groups, it will not return this transaction group until audit 105 is available. At that time it will read the end of audit file 104 and continue on reading audit file 105. Because of this, Databridge requires at least two audit files to remain on disk to accommodate transactions that start in one audit file but end in another. To ensure that Databridge has the audit files it needs, use the Copy Audit program (WFL/DATABRIDGE/COPYAUDIT). You can use the Copy Audit Utility to keep a specified number of closed audit files on disk. |
Span Tracking
Tracking is the process of extracting only completed changes from a DMSII audit file and then updating the secondary database with those changes. To accomplish the tracking of changes from the host DMSII database to a secondary database, Span uses the audit files created by DMSII. The audit files contain information about which records have been modified, deleted, or added.
You can determine how “up-to-date” your secondary database is by how often you close the DMSII audit files and run Span. For example, you can close the audit file every hour, every day, or even every week, depending on how crucial current information is. If you do not explicitly close the audit file, the Accessroutines close it when the audit file reaches the size specified in the DASDL. If you use the DBEngine parameter setting READ ACTIVE AUDIT = TRUE, Span can process the entire audit trail up to the last quiet point. Since a new audit file is opened as soon as an old one is closed, you can take the closed audit file and immediately begin the updating on the secondary database. Of prime importance is that the secondary database know its exact position in the audit trail.
For information on automating this process, see Automating Span Processing. For information on controlling when audit files close, see Databridge Utilities.
When updating the secondary database, any of the following issues can arise:
- Audit position
- Replicating additional data sets
- DMSII rollback or rebuilding
- DMSII reorganizations
| Audit Position | Each secondary database must record the current audit position for each data set. (Databridge provides this information at the end of each transaction group.) If the secondary database is rolled back or reloaded from a dump, the audit position of the secondary database can be rolled back to an audit position prior to the database rollback or reload. Tracking then starts at the rolled back audit position so that the data records on the secondary database are in sync with the actual data records. |
| Replicating Additional Data Sets | If you want to replicate data sets that you did not include in previous runs of Span, you must uncomment the appropriate entry in the Span parameter file so that Span replicates the added structures as well. |
| DMSII Rollback or Rebuilding | Before you perform a rollback or reload, see Normal Recovery from a Rollback. |
| DMSII Reorganizations | Before you perform a reorganization, see DMSII Reorganizations. |
Troubleshooting Span
This topic includes guidelines for troubleshooting any problems you may encounter with Span.
-
Read the Span report (MSGFILE).
The report includes the following:
- The name of the parameters file that Span read
- The option settings that Span used
- The output file destinations
- The number of records replicated and the number of records skipped
- The reason Span stopped processing
See REPORT and Span Report Files.
-
If only some data sets are updated, check the Mode column for each data set in the Span parameters file.
-
If the mode is 3, the DMSII data set was reorganized. You must change the mode to 2 and change the client format level to the DMS format level after you make the corresponding change in the client database.
-
If the mode is 4, the data set was initialized using DMUTILITY. You must change the mode to 2 after you purge the corresponding rows in the client database.
Change the mode before you run Span again. For more details, see Complete a DMSII Reorganizations.
-
-
If Span renames files by adding the node .../BAD, check your entry for the HEADER option in the Span parameters file.
Most likely the HEADER option is TRUE, but you have existing files that do not have the correct header. This could be because the HEADER option was previously FALSE when those files were created.
-
If Span waits on a NO FILE for an audit file, it can't find the audit file (on disk or tape) it needs to continue processing. Do one of the following:
-
Mount the tape containing that audit file and let Span continue.
-
DS the DATABRIDGE/MISSING_AUDIT_FILE task, which tells it that you cannot provide the audit file now. In this case Span stops processing immediately. The next time Span runs, it requests the same audit file.
If replication fails during the fixup phase, the fixup phase can be restarted. The Span receives COMMITs at the end of transaction groups during the fixup phase. You can restart the replication from the last COMMIT.
-
-
If Span finds duplicate data file names on the host, remove the data files as you move them to the client system for processing or do the following:
- Change the data file titles
CHANGE SPAN/DATA/databasename/datasetname TO READYTOMOVE/SPAN/DATA/databasename/datasetname-
Transfer the READYTOMOVE files to a client system or another location.
-
Remove the READYTOMOVE files.
-
Process Span anomalies.
Since DBEngine does not have the opportunity to consolidate the changes that occurred during the extraction with the extracted records themselves, there is the possibility that during the fixup phase, Span will receive duplicate creates, deletes, or modifies for deleted records. Databridge does not flag these anomalies; therefore, you should be aware that these anomalies can occur.
-
When a duplicate record is encountered on a new record insert, replace the old record in the table with the new record to be created. For example, for duplicate creates, convert the second create to a modify.
-
Ignore missing records when a delete function is requested. For example, when the delete function fails, ignore the second delete.
-
When a modify function does not find a record in the client table, discard the modify.
If the client cannot handle the anomalies, you can use Snapshot to create a clean snapshot of the data sets.
-