Multibyte Support
Unicode is a list of all known characters. It includes all alphabets of all spoken and unspoken languages. Each character has its own unique index in the Unicode list. The first 128 characters are known as ASCII characters.
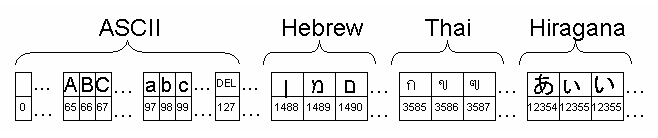
When data is stored or computed, the Unicode list is not used to represent the characters. Instead, so-called character encodings (or character sets) define how characters are represented on computers and within files. Numerous character sets are used throughout the world.
Two of the more frequently-used character encodings that cover all Unicode characters are:
- UTF-8: Requires 1-4 Bytes per character; this character set is widely used for international Web sites and international text representation. Strings in the Linux kernel and Java are encoded in UTF-8.
- UTF-16: Requires 2 or 4 Bytes per character; this encoding is mainly used for string representation in the Windows NT kernel (Win NT and newer).
- ASCII: Single Byte encoding: 1 Byte per character
- Latin-1 (Windows Codepage 1252): Single Byte encoding: 1 Byte per character
- Shift-JIS (Windows Codepage 932): Double Byte encoding: 1 or 2 Bytes per character
- EUC-JP (Windows Codepage ): Includes 3 Japanese char sets: 1, 2, or 3 Bytes per character
When developing applications for Windows, programmers can choose between Unicode (UTF-16) string representation or Multi-Byte-Character-Set (MBCS) string representation. MBCS representation refers to a geographic region-dependent code page encoding (for example, Shift-JIS for Japan; Latin-1 for the Americas and most European countries). This affects all GUI elements, as all data needs to be displayed in the same string representation that has been selected for the application.