Introducing Databridge Twin
Databridge Twin is a mainframe program that replicates (clones and then updates) a DMSII database as another DMSII database. The layouts of the two databases must be identical. Their usercodes and families may differ but they must contain exactly the same data sets, sets, and data items.
The original DMSII database is called the primary database, and it is typically a production database. The copy of the primary DMSII database is called the secondary database, and it typically resides on a development or departmental mainframe. Updates to the primary database are applied to the secondary database as DMSII audit becomes available.
-
Primary System
The primary system is the mainframe that contains the original DMSII database. The primary system must contain the Databridge database replication server software (“Databridge Host”) including DBEngine and DBServer. (For an explanation of the Databridge Accessories, see accessories or refer to the Databridge Host Administrator’s Guide.)
If you have only one mainframe, the primary system is distinguished by the usercode under which the original DMSII database resides.
-
Secondary System
The secondary system is the mainframe that contains the copy of the DMSII primary database. The secondary system does not require a Databridge Host software installation. It does, however, require the Databridge Twin software. For a list of software components, see Databridge Twin Components for more information.
If you have only one mainframe, the secondary system is distinguished by the usercode under which the secondary DMSII database resides.
-
Primary Database
The primary database is always the original DMSII database.
-
Secondary Database
The secondary database is a duplicate or copy of the primary database except that it may or may not contain the entire contents of the primary database. In all other respects, however, it is a complete DMSII database with its own CONTROL, DESCRIPTION, and audit files.
The secondary database is typically used only for queries and not updates. Some of the query workload can be offloaded from the primary system to the secondary system. Only the Databridge Twin Engine updates the secondary database, and the audit files reflect the updates replicated from the primary database.
How Databridge Twin Works
Following is a simplified description of the flow of data between the primary and secondary DMSII databases. This description starts after all of the necessary Databridge database replication server software and Databridge Twin components are correctly installed and configured.
-
The Databridge Twin program (secondary system) initiates the Databridge Twin Engine, which calls Databridge Server (primary system).
-
Databridge Server initiates Databridge Engine to retrieve updated information from the audit trail. Databridge Server then sends the updated information to the Databridge Twin Engine.
Note
By default, Databridge Engine processes only closed audit files. However, if you set the Read Active Audit option to true in the Databridge Engine parameter file on the primary system, Databridge Engine can also process the current audit file. To determine how long Databridge Twin waits before checking for available audit files, use the RETRY and MAXWAIT options in the Databridge Twin parameter file. Also note that you can use the DBAuditTimer utility (primary system) to close the current audit file periodically. The DBAuditTimer utility is explained in the Databridge Host Administrator’s Guide.
-
When the Databridge Twin Engine receives the audit file data, it does the following by calling routines in the Databridge DMSII Support library:
- Updates the secondary database (CREATE, LOCK, STORE, and DELETE).
- Prior to commits, updates either the restart data set or the DBTWINCONTROL data set (whichever is in use) in the secondary database with the current audit location.
The Databridge DMSII Support library is a normal application database program. Therefore, all of the usual database operations and exceptions apply to Databridge Twin, such as the possibility for DEADLOCKS, auditing all updates, etc.
The following Databridge Twin features are available:
-
REDUNDANT UPDATES, a configuration parameter, specifies whether updates already present in the secondary database should be applied anyway, or discarded.
See the Sample Databridge Twin Parameter File for details.
-
The tailored support library for the secondary database will apply reformatting specified in an ALTER command. Reformatted data items must be the same size and type as the original item, and virtual items are not allowed.
-
A filter in a tailored support library can discard updates for certain records. Filters may not, however, exclude individual data items from a record.
-
Databridge Twin writes the audit location and record contents to the report file for any record it cannot find in the client database.
-
Databridge Twin can connect to alternate hosts that mirror the primary database or use Remote Database Backup (RDB).
-
By default, Databridge Twin writes report files to the DBBD/RUN/TWIN directory on the normal printer backup disk. You can modify WFL/DATABRIDGE/TWIN to change this behavior if desired.
Primary and Secondary Database Locations
The primary database and the secondary database can reside on the same mainframe or on separate mainframes. If the databases are on the same mainframe, they are differentiated by their usercodes. The primary and secondary systems communicate via a port (network) file using TCP/IP.
The DMSII System Software Release level on the secondary system must match the primary system.
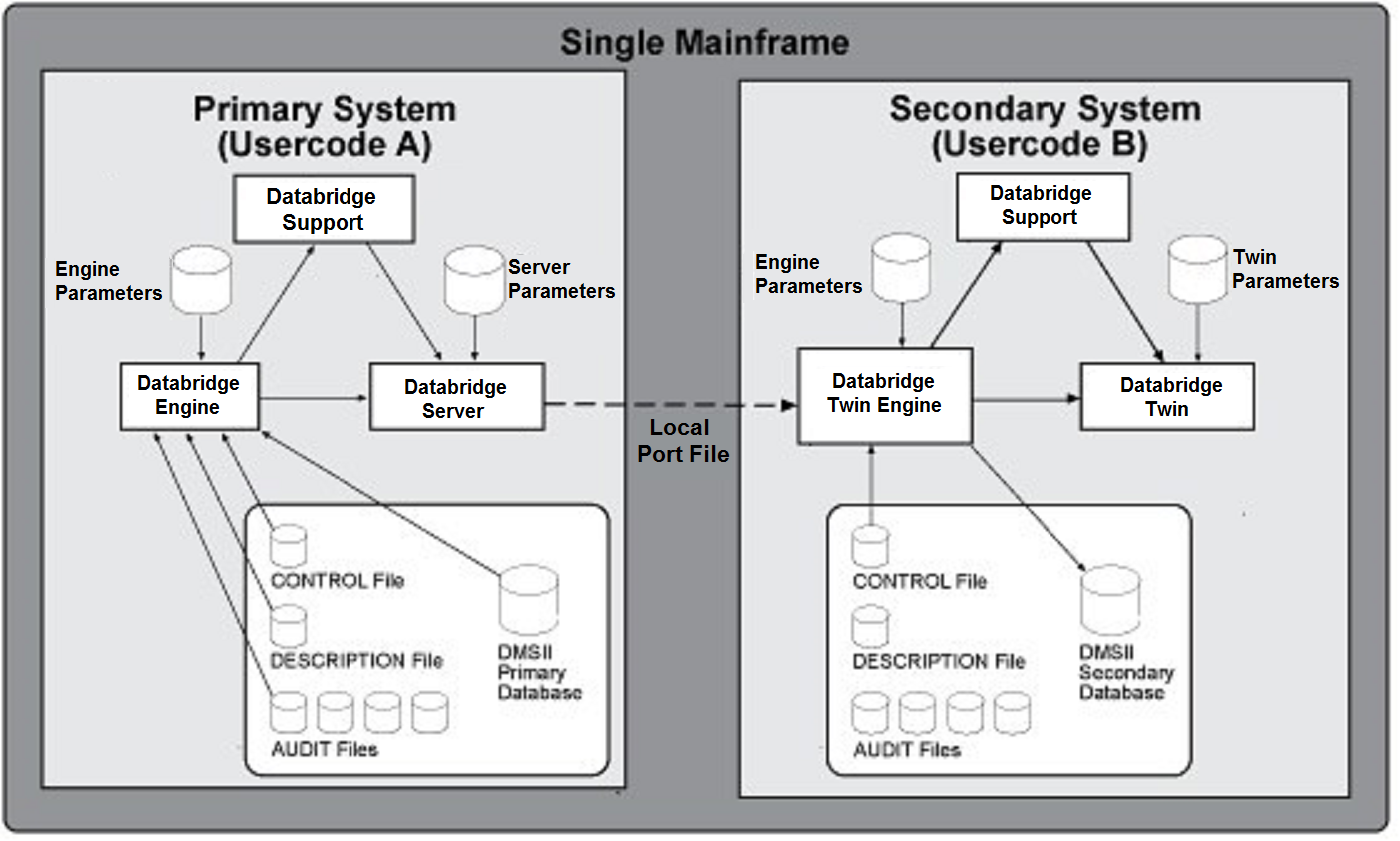
The following diagram shows a typical installation of the Databridge Host and Databridge Twin software on a single mainframe.
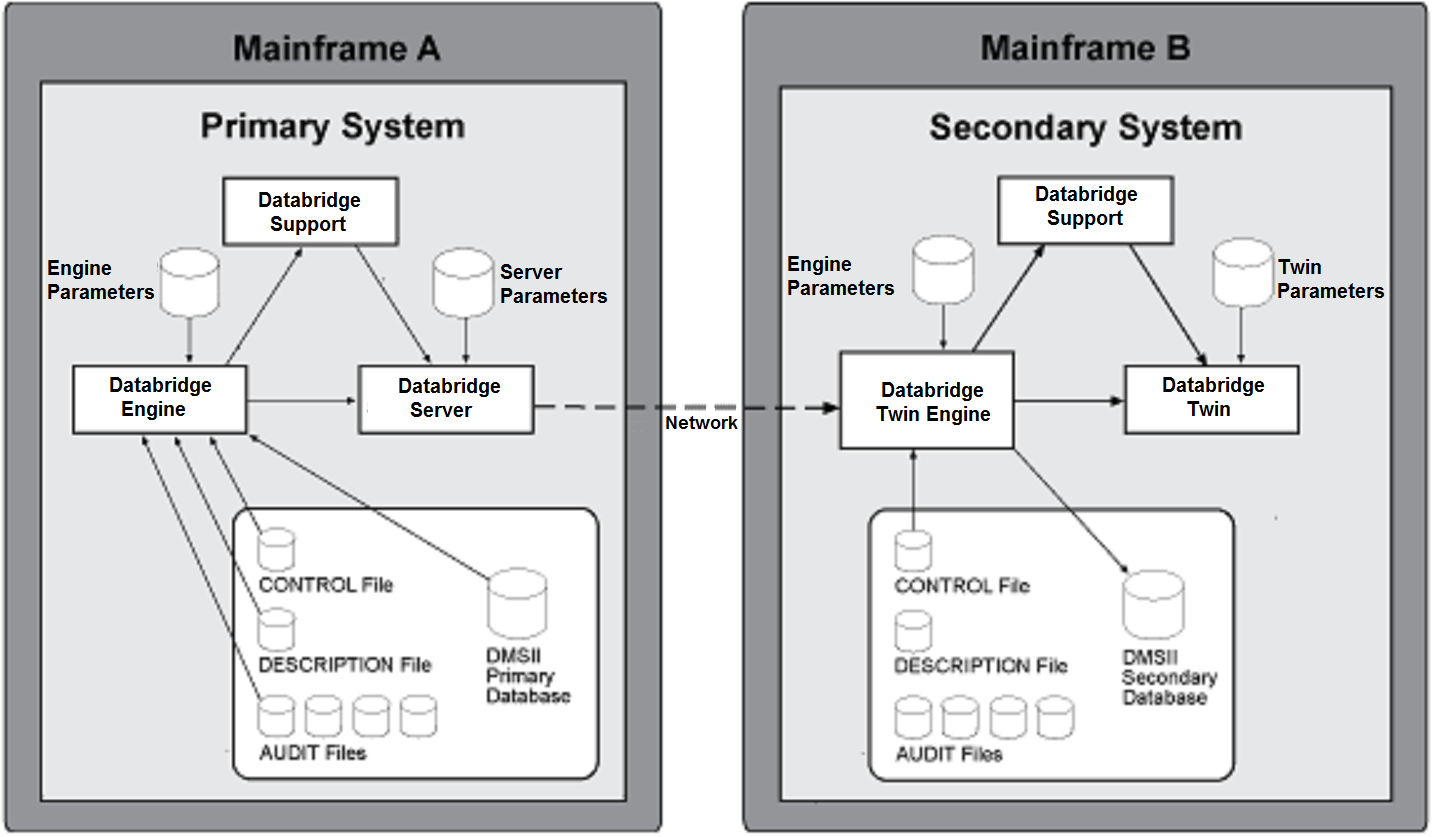
The following diagram shows a typical installation of the Databridge Host and Databridge Twin software on separate mainframes.
If you are going to LOAD a database dump from the primary database to create the secondary database and the databases are on separate mainframes, the primary and secondary databases must use the same pack names. Even though the primary and secondary databases physically reside on separate mainframes, the secondary database pack name(s) must be the same as that on the primary system. For example, if the primary database pack is named PRODUCTS, then the secondary database must also reside on a pack named PRODUCTS. This restriction does not apply if you are going to use the CLONE command to create the secondary database.
If the primary and secondary databases are on the same mainframe, you must specify different usercodes in the CONTROL FILE declaration in the DASDL source file.
Databridge Twin Components
As shown in the previous diagrams, Databridge Twin consists of the following components:
| Component | Description |
|---|---|
| Databridge Server (on the mainframe) | The Databridge Server program calls the Databridge Engine (also on the mainframe), which reads the database CONTROL and audit files on the primary system. When requested, Databridge Server sends the updates to the Databridge Twin Engine running on the secondary system. |
| Databridge Twin | The Databridge Twin program calls routines in the Databridge Twin Engine to create the secondary database using either a dump from the primary database or by cloning the primary database. From then on, it calls another routine to update the secondary database using the audit information from the primary database. |
| Databridge Twin Engine | The Databridge Twin Engine is a subset of the full Databridge Engine. The Databridge Twin Engine has the same file name as the full Databridge Engine (OBJECT/ DATABRIDGE/ENGINE). You should not register it as a system library using the SL command. If desired, you can use the full Databridge Engine in place of the special Databridge Twin Engine because it contains all of the same functionality. |
| Databridge Support Library | The Support Library on the secondary system is the same as the Support Library on the primary system, except that you cannot use column filtering, complex ALTERs, or VIRTUALs. You can use the Support Library to filter the records coming from the primary system so that only certain records are replicated. Note, however, that record filtering is ignored if you use a database dump to create the secondary database. In this case, all records will be loaded into the secondary database. But if you use (record-by-record) cloning to populate the secondary database, the records will be filtered as expected. |
Databridge Limitations
Databridge Twin does not support embedded data sets. Any embedded data sets will be empty in the secondary database.
Databridge Twin does not support RSN (Record Serial Number) data item values. In general, a record's RSN in the secondary database will differ from the same record’s RSN in the primary database. Any sets that use the RSN data item as a key item will return a different record in the secondary database than in the primary database. If a data item in a data set contains the RSN of another record it will, in general, refer to a different record in the primary database than in the secondary database.
Databridge Twin will not return an error if a data set has a visible RSN data item, but the results are unpredictable.