Raw Measure Data Capturing
When to use raw measure data capturing
After you have run a load test you can analyze the results in detailed reports in Performance Explorer. If you need data that is even more detailed or if you want to process collected data in another program, you can use Silk Performer to capture raw measure data and store it in CSV files. You can then, for example, import the raw measure data into a spreadsheet program and generate custom graphs.
How does Silk Performer capture raw measure data?
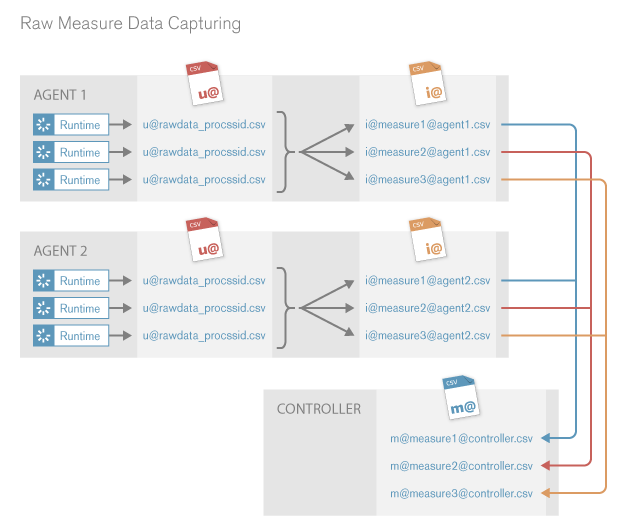
- Raw measure data is collected in u@... files (on the agents).
- Raw measure data is merged from the u@... files into i@... files (on the agents).
- Raw measure data is merged from the i@... files into m@... files (on the controller).
When you start a Silk Performer test, the Silk Performer controller deploys the test to the agents you have specified. Each agent starts several perfRun.exe processes, and within each process, several virtual users execute the test. During execution, Silk Performer creates one u@... file per process.
The raw measure data is then merged into i@... files and the u@... files are removed. Each i@... file holds the raw measure data of one measure name/measure type combination. The files are stored in the RawData folder: Silk Performer <version number>/Projects/MyProject/RawData.
Once the i@... files have been transferred to the controller, the raw measure data is merged into m@... files (also in the RawData folder). The i@... files remain in the RawData folder. Each m@... file holds the raw measure data of one name/type combination of all agents.
Step one and two of the raw measure data capturing process are executed on the agents, step three is executed on the controller.
What do the file names mean?
These are the full names of the raw measure data files:
- u@rawdata_processid.csv
- i@name_type@agent.csv
- m@name_type@controller.csv
The data is stored in CSV files (comma-separated value files), which allows you to easily process the raw measure data with a spreadsheet program. u stands for user file, i for intermediate file, and m for merged file. Here is an example of some i@... and m@... files:
i@ShopIt+-+Greetings_131@testingserver.csv i@ShopIt+-+Greetings_132@testingserver.csv i@SilkPerformer+Test+Site_131@testingserver.csv i@SilkPerformer+Test+Site_132@testingserver.csv m@ShopIt+-+Greetings_131@pc-johndoe.csv m@ShopIt+-+Greetings_132@pc-johndoe.csv m@SilkPerformer+Test+Site_131@pc-johndoe.csv m@SilkPerformer+Test+Site_132@pc-johndoe.csv
Note the following from this example:
- There are no u@... files in this example, since they are removed when their content is merged into the i@... files. They are just temporary files.
- The measure names are URL-encoded (ShopIt+-+Greetings).
- The measure type is represented by its number code. 131 is the number code for Page time[s], 132 is the number code for Document download time[s].
- testingserver is the machine name of the agent.
- pc-johndoe is the machine name of the Controller.
What does a raw measure data file look like?
Here is an example of what the raw measure data in an m@... file looks like:
;MeasureName:;ShopIt - Greetings ;MeasureType:;Page time[s] C;Timestamp;Value;VUName ;1381231408198;46;VUser ;1381231431291;31;VUser ;1381231433032;31;VUser ;1381231434120;16;VUser ;1381231436307;15;VUser ...
The data within the CSV files is sorted by the timestamp (which is a Unix timestamp). The timestamp represents the elapsed microseconds since 01.01.1970. Time measure values are logged in seconds, file size values are logged in kilobytes.