Using Regular Expressions
A regular expression (regex or regexp) is a special text string used to describe a search pattern, according to certain syntax rules. For example, l[0-9]+ matches "l" followed by one or more digits.
Use regular expressions judiciously and only when necessary. If you require even greater complexity than regular expressions can support, consider using event handlers instead. Using regular expressions, or event handlers, indiscriminately can result in significant performance overhead.
Host Integrator regular expressions are based on Perl syntax. Host Integrator supports regular expressions for:
-
Signature patterns for entity recognition—match a regular expression over a region of the terminal screen
-
Patterns for errors—you can use regular expressions to support "or" conditions
-
Recordset termination—terminate when a Host Integrator condition is satisfied
Host Integrator conditions can contain regular expressions. However, while conditions can use values of model variables, entity attributes, and recordset fields, reqular expressions cannot. Regular expressions only support the use of literal values.
-
Recordset filtering—exclude records that match condition
-
Attributes—read and write substitutions in the attribute value
-
Selection of data—parsing out a particular piece of data from a string, for example everything after the third space up to the last comma (think of parsing a first name or last name from a string or grabbing the state from a street address)
-
Recordset Fields—read and write substitutions
Note
Perl programming documentation is available at Perl regular expressions quick start. This is a good introduction to regular expressions.
Special characters
Certain characters are reserved for special use. If you want to use any of these characters as a literal in a regular expression, you need to escape them with a backslash. If you want to match 1+1=2, the correct regex is 1\+1=2. Otherwise, the plus sign will have a special meaning.
\/ literal /
\\ literal \
\. literal .
\* literal *
\+ literal +
\? literal ?
\| literal |
\( literal (
\) literal )
\[ literal [
\] literal \
\- The - must be escaped inside brackets: [a-z0-9_.\-\?!]
| Character | Description | Example |
|---|---|---|
| // | Used to search a string for a match. | "Hello World" =~ /World/; In this statement, World is a regex and the // enclosing /World/ tells Perl to search a string for a match. The operator =~ associates the string with the regex match and produces a true value if the regex matched, or false if the regex did not match. In this case, World matches the second word in "Hello World" , so the expression is true. |
\ (backslash) |
Escape character used to represent characters that would otherwise be a part of a regular expression. | "\." = the period character. |
| [abc] | Match any character listed within the square brackets. | [abc] matches a, b or c |
\d,\w, and \s |
Shorthand character classes matching digits 0-9, word characters (letters and digits) and white space respectively. Can be used inside and outside character classes | [\d\s] matches a character that is a digit or whitespace |
\D,\W, and \S |
Negated versions of the above. Should be used only outside character classes. | \D matches a character that is not a digit |
\b |
Word boundary. Matches at the position between a word character (anything matched by \w) and a non-word character (anything matched by [^\w] or \W) as well as at the start or end of the string if the first or last characters in the string are word characters or an alphanumeric sequence. Use to perform a "whole words only" search using a regular expression in the form of \bword\b. \b also matches at the start or end of the string if the first or last characters in the string are word characters. |
\b4\b matches 4 that is not part of a larger number. |
\B |
Non-word boundary. \B is the negated version of \b. \B matches at every position where \b does not. Effectively, \B matches at any position between two word characters as well as at any position between two non-word characters. |
\B.\B matches b in abc |
| . (period) | Match any single character | "." matches x or any other character. |
| x (reg character) | Match an instance of character "x". | x matches x |
| ^x | Match any character except for character "x". | [^a-d] matches any character except a, b, c, or d |
| ^ (caret) | Match the beginning of a string. Matches a position rather than a character. | ^. matches a in abc\ndef. Also matches d in "multi-line" mode. |
| $ (dollar) | Match the end of a string. Matches a position rather than a character. Also matches before the very last line break if the string ends with a line break. | .$ matches f in abc\ndef. Also matches c in "multi-line" mode. |
| (pipe symbol) | Or. Match either the part on the left side, or the part on the right side. Can be strung together into a series of options. The pipe has the lowest precedence of all operators. Use grouping to alternate only part of the regular expression. | abc (pipe symbol)def (pipe symbol)xyz matches abc, def or xyz abc(def (pipe symbol)xyz) matches abcdef or abcxyz |
| (abc) (parentheses) | Used to group sequences of characters or expressions. | (Larry(pipe symbol)Moe(pipe symbol)Curly) Howard matches Larry Howard, Moe Howard, or Curly Howard “ |
\1, $1, $$ |
\1 Refers to first grouping, used in the expression $1 Refers to first grouping, used in the replacement string $$ Literal “$” used in the replacement string. |
/(.+)((\r?\n(pipe symbol)\r)\1)+\b/ig,“$1” Removes duplicate lines from a list. The (.+) grabs a line of text and the parenthesis save it for a reference. The (\r?\n(pipe symbol)\r) grabs the line separator, either \r\n, \n, or \r. Next,\1 references the first line and so ((\r?\n(pipe symbol)\r)\1)+ matches 1 or more subsequent lines that match the first line. Notice that in Javascript, a reference within the expression is \1 while a reference in the replacement string is $1. The \b prevents “street” and “streets” from being seen as the same word. |
| { } (curly braces) | Used to define numeric qualifiers | a{3} matches aaa |
| {N,} | Match must occur at least "N" times | Z{1,} matches when "Z" occurs at least once |
| {N,M} | Match must occur at least "N" times, but no more than "M" times | a{2,4} matches aa, aaa or aaaa |
| ? (question mark) | Makes the preceding item optional or once only. The optional item is included in the match if possible. | abc? matches ab or abc |
| *(star) | Match on zero or more of the preceding match. Repeats the previous item zero or more times. As many items as possible will be matched before trying permutations with less matches of the preceding item, up to the point where the preceding item is not matched at all. | "go*gle" matches ggle, gogle, google, gooogle, and so on. |
| + (plus) | Match on 1 or more of the preceding match. Repeats the previous item once or more. As many items as possible will be matched before trying permutations with less matches of the preceding item, up to the point where the preceding item is matched only once. | "go+gle" matches gogle, google, gooogle, and so on (but not ggle.) |
| i | Case insensitive search | /expression/i |
| g (plus) | Global replacement. Replaces all matches. | /expression/g |
| q(?=u) | Matches q only before u. Does not match the u. This is positive lookahead. The u is not part of the overall regex match. The lookahead matches at each position in the string before a u. | q(?=u) matches the "q" in question, but not in Iraq. |
| q(?!u) | Matches q except before u. | q(?!u)) matches "q" in Iraq but not in question. |
For information about additional pattern matching operators for conditions and filters, see Condition Edit Filter.
Examples of Regular Expressions
-
Matches when an error message is displayed on the status line.
ERROR [0-9]{1,4}: .* -
Match 3 instances of a string.
"/(John){3}/" (Matches John John John) -
Match any of several first names, followed by a common last name.
"(Homer|Marge|Bart|Lisa|Maggie) Simpson" (Matches any member of the Simpson family) -
Condition matching "Page N of M" when N = M.
PageStatus =~ s/Page ([0-9]+) of [0-9]+/$1/ = PageStatus =~ s/Page [0-9]+ of ([0-9]+)/$1/ -
Recordset condition to match records where myfield starts with "P".
myrecordset.myfield =~ m/P.*$/ -
Recordset condition where the field is not numeric.
myrecordset.myrecordsetfield =~ /[0-9]+/
Additional Resources
Regular expressions can be complex. A number of resources are available on the Internet to help you understand regular expressions.
- Test tool for regular expressions including examples and syntax.
- A detailed description of regular expression syntax in Perl
Details of a Substitution Regular Expression Example
The regular expression described here is used in Substituting a Regular Expression for a Recordset Field under Substitutions. This example changes a value usually displayed with a trailing minus sign to a value with a leading minus sign.
Search for: (^|[^-.\d])(\d+(?:\.\d+)?)-(?=[^-.\d]|$)
Replace with : $1-$2
A "capture group" is a regular expression surrounded by parentheses that is remembered as a numbered variable for use in the replacement.
| Detail of Expression | Description |
|---|---|
(^ "pipe symbol"[^-.\d]) A numbered capture group (Becomes $1 in the replacement) |
Select from 2 alternatives: Beginning of line or string Any character that is not in this class: [-.\d] (minus, decimal, or digit) |
(\d+(?:\.\d+)?) A numbered capture group (Becomes $2 in the replacement) |
\d+(?:\.\d+)? Any digit, one or more repetitions Optional (zero or one repetitions) of dot followed by one or more digits |
| - | (Match on trailing minus) |
([^-.\d] (pipe symbol)$) Match a suffix but exclude it from the capture. |
Select from 2 alternatives: Any character that is not in this class: [-.\d] (minus, decimal, or digit) End of line or string |
This translates a string like "123.45-" to "-123.45". Any leading non-numeric characters are retained and trailing non-numeric characters are removed so that "ABC123.45-XYZ" would be changed to "ABC-123.45".
Substitutions
Read or Write Substitutions (Attribute or Field)
Use this dialog box to configure substitutions in attributes or recordset field strings. Select either the Attribute Properties tab or the Recordset Fields tab and click Advanced in the Read or Write box.
Define the substitution you would like to perform by specifying the string you want to search for and the string you want to use as a replacement. You can include regular expressions to specify your substitutions. For example, to remove trailing blanks from an attribute or recordset, type \s+$ for the string to search for and leave the replacement specification blank.
The list of string substitutions are applied in the order listed in the user interface. By performing multiple replacements, it is possible to isolate words or substrings. Each substitution is equivalent to the Perl regular expression syntax s/<Search for>/<Replace with>/g. The "g" stands for "global", which replaces all matches (not just the first one).
For example, to replace 2 or more blanks with a single space:
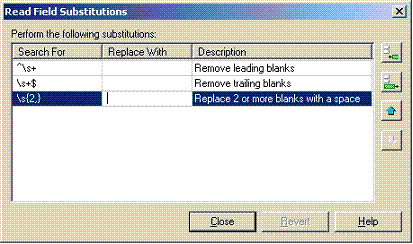
Regular expressions in Host Integrator uses the syntax described in How to Use Regular Expressions.
Substitution Examples
| Purpose | Search For | Replace With |
|---|---|---|
| Remove leading blanks (white space at beginning is replaced with an empty string) | ^\s+ |
|
| Remove trailing blanks | \s+$ |
|
| Remove all spaces | \s |
|
| Remove first word | ^[A-Za-z]+\s |
|
| Remove last word | [A-Za-z]+$ |
|
| Change negative numbers represented with parentheses (123) to be a negative sign -123. | \(([0-9]+)\) |
-$1 |
| Prepend value (at beginning) | (^.*$) |
<value>$1 |
| Append value (at end) | (^.*$) |
$1<value |
Substituting a Regular Expression for a Recordset Field
Use the Substitution dialog box to configure advanced read and write options for both attributes and recordset fields.
Note
Use regular expressions judiciously and only when necessary. Added performance overhead can occur when using regular expressions.
In this example, use the sample model CCSDemo to substitute a recordset field usually displayed with a trailing minus sign, with one which will be displayed with a leading minus sign. There are also steps to test the output.
-
Open CCSDemo in the Design Tool.
-
Click
 to connect to the host.
to connect to the host. -
Select AcctTransactions from the Entity list to navigate to the AcctTransactions entity.
-
Click the Recordset tab, then select the Fields tab on the lower portion of the Recordset tab.
-
Select the row named Amount.
-
In the Read group box, click Advanced to open the Read Field Substitutions dialog box.
-
Click Insert to add a row for a new substitution.
-
Create an expression that matches a money field with a trailing minus sign. In the Search For column of the newly created row, enter the expression:
(^|[^-.\d])(\d+(?:\.\d+)?)-(?=[^-.\d]|$)See this expression in detail -
To transpose the minus sign to the front of the field, enter the following in the Replace With column: $1-$2
-
In the Description column, type:
Move minus sign to front -
Close the Read Field Substitutions dialog box and click Apply to update your model.
-
To test the results, select Procedure Test from the Debug menu.
-
From the Table drop down list, select Transactions and confirm that the GetTransactions procedure is selected.
-
In the Value field of the Procedure Filters box, type
167439459 -
Click Execute.
-
Scroll down the procedure output and note that several amounts have a leading minus sign.
Condition Edit Filter
Use this dialog box to create conditions or filters for terminating the fetching of data from recordsets and for executing operations. Select entries from the Variables, Entity attributes, or Recordset fields list to build string expressions in the Condition/Filter String box. Use the condition operand buttons to create your string or type the string directly into the box.
To reference attributes, fields, and variables, use the following syntax:
- Attributes:
<AttributeName> - Fields:
<RecordsetName>.<FieldName> - Variables:
Variables.<VariableName>
For example, create the following condition that addresses cursor syncing when the cursor is expected to arrive at one of two possible locations:
(Variables.CursorRow = 5 And Variables.CursorColumn =27)
-or-
(Variables.CursorRow = 24 And Variables.CursorColumn =1)
The following condition operands are supported by the Host Integrator:
| Condition operands | Description |
|---|---|
| = | Equal to |
| =* | Equal to (without being case-sensitive) |
| <> | Not equal to |
| > | Greater than |
| >= | Greater than or equal to |
| < | Less than |
| <= | Less than or equal to |
| =~ | The regular expression matches the value expression. For example, object =~/[0-9]+/ means that object is numeric. |
| !~ | The regular expression does not match the value expression. |
| And | And |
| Or | Or |
| Not | Not |
| ( | Left parenthesis |
| ) | Right parenthesis |
| + | Add |
| - | Subtract |
| * | Multiply |
| / | Divided by |
Certain Host Integrator API methods use filter expressions as arguments (for example, see the FetchRecords and SelectRecordByFilter methods in the Visual Basic Methods Reference). See the Host Integrator API Reference for more information about the connectors. To view an example of creating a filter string, see the documentation for using the Select Record action in the Test Recordset dialog box.
Tip
You can use expressions on both the left and right sides of the condition statement. Make sure to enclose data in quotation marks.
More About Regular Expressions
A regular expression is a pattern that can match various text strings; for example, l[0-9]+ matches l followed by one or more digits.
Syntax for pattern matching
<ValueExp> =~ [m]/<RegEx>/[i][m]
<ValueExp> !~ [m]/<RegEx>/[i][m]
<ValueExp> =~ s/<RegEx>/<ReplaceWith>/[g][i][m]
where
m This is the "Match" operator. It means read the input string expression (on the left of the =~ or !~ operator), and see if any part of it matches the expression within the delimiters following the m. The =~ operator means return boolean true if there is a match; the !~ operator means the opposite
s/ "Search and replace" or "substitution" operator. In the input string (to the left of the =~ operator), the regular expression match is replaced. When the regular expression uses parentheses, backreferences (such as $1) can be used in the ReplaceWith string. The output is the result after replacements.
/i Ignore case option for case-insensitive pattern matching.
/g Global option. Replaces all regex matches in the string, not just the first one.
/m Multi-line option. Within the regular expression, caret (^) and dollar ($) match the beginning and end of lines respectively within the string.
If your regular expression or replacement value contains the forward slash character (/), you can use a different delimiter symbol (such as !).
Example
You can set up an expression to terminate a recordset where the last screen is identified by text on the screen stating the current page and the total number of pages, such as "Page 1 of 12" or "Page 12 of 12".
To terminate the recordset, define an attribute called PageStatus at the screen location where the "Page x of y" text occurs. In the Recordset Termination dialog, define the following termination condition:
PageStatus =~ s/Page ([0-9]+) of [0-9]+/$1/ = PageStatus =~ s/Page [0-9]+ of ([0-9]+)/$1/(